Reinforcement Learning — Beginner
Understand how machines learn through trial and reward
This beginner-friendly course is a short technical book designed for people with zero background in artificial intelligence, coding, or data science. If you have ever wondered how a machine can improve by making attempts, seeing results, and adjusting its next move, this course gives you a clear and simple path into that idea. Reinforcement learning may sound advanced, but at its core it is about learning through trial and error, much like people do in everyday life.
Instead of starting with formulas, programming, or technical language, this course starts with familiar examples. You will first understand what it means to learn from experience, then slowly build toward the main parts of a reinforcement learning system. By the end, you will be able to describe how an agent learns from an environment using actions, rewards, and repeated practice.
The course is organized into six connected chapters, and each one builds naturally on the last. Chapter 1 introduces the core idea of learning by trying. Chapter 2 gives names to the key parts, such as the agent, environment, action, reward, and goal. Chapter 3 explains how better choices appear over time as a result of feedback and repetition. Chapter 4 explores a famous beginner concept in reinforcement learning: the difference between trying something new and using what already seems to work. Chapter 5 looks at real-world uses, and Chapter 6 teaches you how to think like a simple reinforcement learning designer.
Because the course is shaped like a short technical book, it is ideal for self-paced learners who want understanding before complexity. Every chapter has a clear purpose, plain language, and a strong learning progression.
This means you can focus on understanding how reinforcement learning works before worrying about tools or software. The goal is to help you build a strong mental model that will make future AI learning much easier.
By completing this course, you will be able to explain reinforcement learning in plain language, identify the main parts of a learning system, and describe how rewards influence behavior. You will understand why machines need both exploration and exploitation, why bad rewards can create bad outcomes, and where reinforcement learning is useful in the real world. You will also be able to recognize situations where reinforcement learning is not the right tool.
This foundation is valuable whether you are learning for curiosity, career growth, or digital literacy. Reinforcement learning appears in topics such as robotics, game-playing systems, recommendations, routing, and decision optimization. Understanding the basic logic behind it gives you a practical advantage when reading about modern AI.
This course is made for absolute beginners, career changers, students, non-technical professionals, and anyone who wants a gentle entry into AI. If other AI courses felt too fast, too mathematical, or too full of jargon, this course is designed to feel different. It helps you understand the big ideas clearly before moving on to more advanced material.
If you are ready to begin, Register free and start learning today. You can also browse all courses to continue your AI journey after this one.
The purpose of this course is not to overwhelm you. It is to give you a simple, accurate, and useful understanding of how machines improve by trying. With the right explanation, reinforcement learning becomes much easier to grasp than many beginners expect. Start here, move chapter by chapter, and build the confidence to explore more of artificial intelligence with a strong foundation.
Machine Learning Educator and AI Foundations Specialist
Sofia Chen teaches beginner-friendly AI and machine learning concepts for new learners entering the field for the first time. She specializes in turning complex technical ideas into clear, practical lessons that do not require coding experience.
When people first hear the phrase reinforcement learning, it can sound technical or distant. But the core idea is very familiar. Reinforcement learning is about learning through trial and error. A machine does something, sees what happens, and slowly adjusts what it does next. If an action leads to a better result, the machine becomes more likely to choose that action again in similar situations. If an action leads to a worse result, it becomes less likely to repeat it.
This style of learning appears all around daily life. A child learns how hard to push a door. A person learns the fastest route to work. A pet learns which behaviors lead to treats and which lead to being ignored. In all of these cases, improvement does not come from a perfect instruction manual. It comes from acting, receiving feedback, and changing future behavior.
That is why reinforcement learning exists in AI. Some problems are too messy, too uncertain, or too dynamic to solve by writing a fixed list of rules. A machine may need to discover a good strategy by interacting with a situation over time. In reinforcement learning, we usually talk about an agent, which is the learner or decision-maker, and an environment, which is everything the agent interacts with. The agent takes an action, the environment responds, and the agent receives a reward. The reward is a signal that says, in effect, “that was helpful” or “that was not helpful.” The agent’s goal is not just to get one reward once, but to learn a pattern of behavior that earns good rewards over time.
This chapter introduces that idea in simple language. You will see why feedback is the engine of improvement, why rewards shape behavior so strongly, and why badly designed rewards can create bad results. You will also begin to distinguish reinforcement learning from other common AI approaches. In some AI systems, the machine learns from labeled examples prepared by people. In others, it finds patterns in data without labels. Reinforcement learning is different because learning happens through interaction. The machine is not just studying a static dataset. It is doing, observing, and adapting.
As you read, keep an engineering mindset. A reinforcement learning system is not magic. It improves only if the setup makes sense: the goal must be clear enough, the reward must encourage the right behavior, and the environment must provide useful feedback. If any of these pieces are poorly designed, the system may learn slowly, learn the wrong lesson, or exploit shortcuts that look successful but fail in practice. Understanding this early will help you read later examples such as mazes, games, and robot tasks with much more confidence.
In the sections that follow, we will build the idea step by step. We will start with everyday examples, connect them to beginner-friendly AI concepts, and then walk through the simple loop that defines reinforcement learning: act, observe, evaluate, and improve. By the end of the chapter, you should be able to describe reinforcement learning in plain words and recognize its basic workflow in common examples.
Practice note for Recognize trial-and-error learning in daily life: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand why reinforcement learning exists: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Before thinking about machines, it helps to notice how often humans and animals learn by experience. Imagine learning to ride a bicycle. At first, you wobble, over-correct, and make awkward movements. You do not solve the problem by reading a thousand exact rules about balance. Instead, you try, feel what works, and adjust. Small successes encourage you to repeat certain motions. Mistakes teach you what to avoid. Improvement comes from a cycle of action and feedback.
The same pattern appears in ordinary decisions. You try a new shortcut to the grocery store. If traffic is lighter, you remember it. If it takes longer, you stop using it. You adjust how much seasoning to add while cooking. You learn where to stand in the shower to get the right water temperature. In each case, there is no grand theory required. There is trying, noticing the result, and changing future behavior.
This is the intuition behind reinforcement learning. A machine can be placed in a situation where it has choices. It makes a choice, gets a result, and uses that result to improve its next choice. The machine does not need perfect knowledge in advance. It learns from experience gathered over time.
A practical lesson here is that trial-and-error learning usually works best when feedback is clear. If every route to work feels equally slow, it is hard to learn the best one. If feedback arrives much later, learning also becomes harder. This matters in engineering. When building systems that learn from rewards, designers try to create signals that are timely and meaningful. Good feedback speeds learning. Weak or confusing feedback slows it down.
A common beginner mistake is to think trial and error means random guessing forever. That is not the point. Early on, the learner may explore more because it does not yet know what works. Over time, useful patterns emerge, and behavior becomes less random and more purposeful. So learning from experience is not chaos. It is structured improvement driven by feedback.
Artificial intelligence is a broad term. For beginners, the simplest way to think about it is this: AI is about building systems that perform tasks requiring decision-making, pattern recognition, or adaptation. Some AI systems recognize faces in images. Some translate text. Some recommend movies. Some control robots or play games. Reinforcement learning is one member of this larger AI family.
It helps to compare reinforcement learning with two other common learning styles. In supervised learning, a model learns from examples that already include correct answers. For instance, thousands of pictures might be labeled “cat” or “dog,” and the system learns to predict the label for new pictures. In unsupervised learning, the system looks for structure or patterns in data without being told the correct answers. It might group similar customers together based on purchasing behavior. In reinforcement learning, by contrast, the learner is not mainly given correct answers for each step. Instead, it interacts with a setting and receives rewards or penalties based on outcomes.
This difference is important. Reinforcement learning is useful when the best action depends on context and when success unfolds over time. A single action might not look impressive by itself, but it may set up a better result later. For example, in a game, moving a piece to a quiet position now may create a winning opportunity several turns later. The machine must learn to connect current choices with future consequences.
For beginners, a practical mental model is to picture AI as a toolbox, not one single method. Different tools fit different jobs. If you already have labeled examples and want predictions, supervised learning may fit. If you want to discover hidden structure, unsupervised learning may help. If you need a system to improve through interaction and delayed feedback, reinforcement learning becomes attractive.
Engineering judgment matters here. People sometimes try to use reinforcement learning just because it sounds advanced. That can be a mistake. If a simple rule or standard machine learning method solves the problem well, that may be the better choice. Reinforcement learning becomes valuable when action, feedback, and long-term strategy truly matter. Good practitioners choose the simplest method that matches the problem.
Some tasks are easy to describe but hard to solve with fixed rules. Consider a robot learning to walk. You could try to write exact instructions for every joint angle, every tiny shift in balance, and every surface condition. In practice, that becomes extremely difficult. The world is noisy. Conditions change. The “right” movement may depend on what happened one moment earlier. Trial and error gives the machine a way to discover workable behavior instead of requiring humans to hand-code every detail.
Games provide another clear example. In a maze, the machine must find a path from start to finish. You might tell it the goal, but you may not want to specify every correct turn in every possible maze. In a board game, good play depends on planning ahead, not just reacting to one move at a time. Trial-and-error learning lets the system test actions, experience outcomes, and gradually prefer stronger strategies.
Why not always use direct instructions? Because in many real problems, the environment is too complex, too large, or too uncertain. There may be far too many situations to list in advance. A rule that works in one case may fail in another. Reinforcement learning exists because interaction can reveal useful knowledge that is hard to write down beforehand.
However, trial and error also brings challenges. It can be slow. It may require many attempts before good behavior appears. The learner may discover tricks that maximize reward in the wrong way. For example, if a robot is rewarded only for moving fast, it may move unsafely. If a game agent is rewarded for points without regard to sportsmanship or fairness, it may exploit loopholes. This is why reward design is not a side issue. It is central to the whole method.
A practical takeaway is that reinforcement learning is strongest when the problem has clear measurable outcomes, repeated opportunities to improve, and room for strategy discovery. It is not just about trying random actions. It is about using experience to uncover a better policy, meaning a better way of choosing actions over time.
Now we can state the basic reinforcement learning idea clearly. There is an agent, which is the learner or decision-maker. There is an environment, which is the world the agent interacts with. The agent observes the current situation, takes an action, and then the environment changes in response. The agent receives a reward, a number or signal representing how good or bad that outcome was. Over time, the agent tries to learn behavior that leads to more total reward.
The word goal matters because the agent is not only chasing immediate pleasure. In many tasks, the best strategy includes short-term sacrifices for long-term gain. A maze solver may move away from the exit briefly to avoid a dead end. A game-playing system may give up a small advantage to secure a larger one later. Reinforcement learning is therefore about long-term consequences, not just instant reactions.
You can think of the learning loop like this: observe, act, receive feedback, update, repeat. That loop is simple, but it captures a powerful idea. The machine learns from consequences rather than from direct correction at every step. No teacher says, “Action number three was exactly right.” Instead, the reward tells the agent whether the path it is taking is leading somewhere useful.
This is why feedback is the engine of improvement. Without feedback, the agent cannot tell whether one behavior is better than another. With feedback, even imperfectly at first, the agent can begin to compare choices and shift toward better ones. In practice, the quality of that feedback strongly affects the quality of the learned behavior.
A common mistake is to assume reward always equals true success. In real systems, reward is only a designed signal. It is our attempt to represent success. If the reward misses something important, the learned behavior may also miss it. For example, a delivery robot rewarded only for speed might cut corners in dangerous ways. Engineering reinforcement learning means thinking carefully about what the reward encourages, not just whether it is easy to measure.
To understand how a machine improves, focus on the chain from action to result. The agent takes an action in a particular situation. The environment responds. The result may be helpful, harmful, or neutral. That result becomes information. The agent uses it to change how strongly it prefers certain actions in similar situations next time. Improvement is therefore not magic insight. It is the repeated adjustment of behavior based on outcomes.
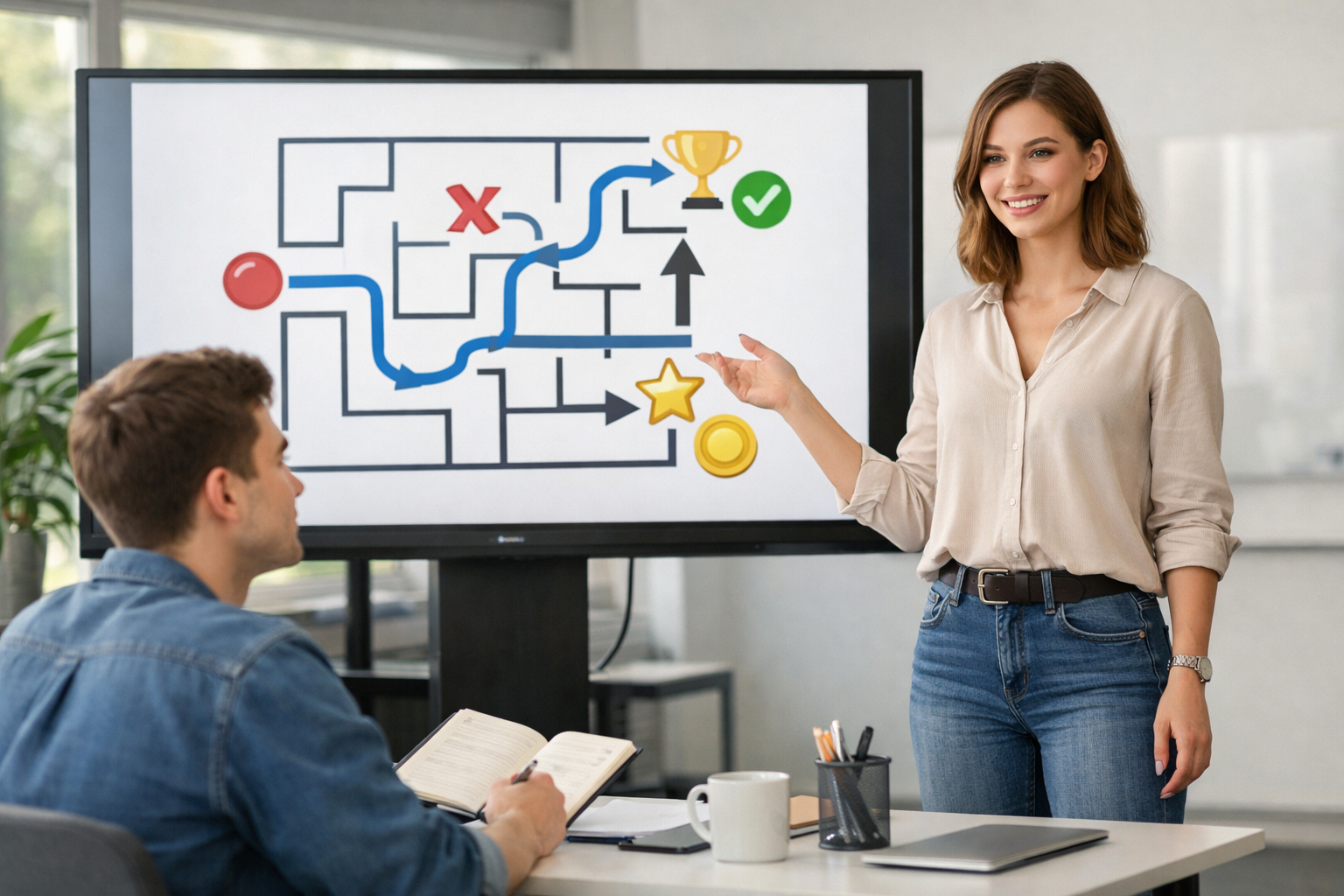
Suppose an agent is navigating a maze. If moving right leads into a wall, that action is not useful in that state. If moving up eventually gets the agent closer to the exit, that action may become more valuable. Over many attempts, the agent begins to build a map of which choices tend to work. It is not memorizing one lucky path only. Ideally, it is learning a better decision strategy.
In engineering practice, improvement depends on repetition and consistency. One reward signal may be noisy or misleading by chance. But across many attempts, patterns become visible. This is one reason reinforcement learning often needs many episodes, where an episode is one full attempt at the task, such as one game or one run through a maze. Beginners are sometimes surprised by this. Learning can take time because the system must gather experience before it can recognize what truly works.
Another practical issue is balancing exploration and exploitation. Exploration means trying actions that might reveal something better. Exploitation means using the best-known action so far. If the agent only exploits, it may get stuck with a decent but not great strategy. If it only explores, it never settles into strong performance. Good reinforcement learning requires a sensible balance between the two.
This section also highlights why bad rewards create bad results. If you reward the wrong thing, the agent may improve at the wrong task. That is not the machine being foolish; it is the machine being obedient to the signal it was given. The lesson is practical and important: rewards shape behavior. To build useful systems, designers must define rewards that match the real goal as closely as possible.
Let us end the chapter with a simple example. Imagine a small robot in a grid maze. The robot starts in one square and must reach a goal square. Some moves are safe, some hit walls, and some lead to longer paths. The robot can choose actions such as move up, down, left, or right. Each step costs a little reward, hitting a wall gives a negative reward, and reaching the goal gives a positive reward.
At the beginning, the robot does not know the best route. It tries moves and gets feedback. If it bumps into walls, those choices look worse. If a sequence of moves reaches the goal more efficiently, those choices start to look better. After many attempts, the robot begins to favor paths that lead to success with fewer penalties. This is reinforcement learning in one of its clearest forms.
Notice what makes this example powerful for beginners. We can name all the parts. The agent is the robot. The environment is the maze. The actions are the possible moves. The reward is the score given after each result. The goal is to reach the target efficiently. The learning loop is also visible: choose an action, see the result, receive reward, adjust behavior, and repeat.
Now consider how reward design changes behavior. If the robot gets a huge reward only at the end and no guidance along the way, learning may be slow. If each step has a small cost, the robot is encouraged to find shorter routes. But if the step cost is too harsh, it may avoid exploring. If bumping into walls is not penalized enough, it may waste time. This shows the engineering side of reinforcement learning: rewards are not just bookkeeping. They actively shape what the agent becomes.
The same pattern extends beyond mazes. In games, the agent learns moves that improve winning chances. In robot tasks, it learns actions that better achieve balance, movement, or object handling. In every case, the machine improves by trying, receiving feedback, and updating what it does next. That is the central idea of this chapter and the foundation for everything that follows in reinforcement learning.
1. What is the core idea of reinforcement learning in this chapter?
2. Why does reinforcement learning exist in AI?
3. In reinforcement learning, what role does feedback play?
4. Which sequence best describes the simple reinforcement learning loop introduced in the chapter?
5. What is one risk of badly designed rewards in a reinforcement learning system?
In reinforcement learning, the big idea is simple: an actor makes choices, the world responds, and learning happens from the results. This chapter introduces the core parts of that loop in plain language. If Chapter 1 explained reinforcement learning as learning by trial and error, this chapter names the parts that make trial and error possible. Those parts are the agent, the environment, the actions it can take, the rewards or penalties it receives, and the goal it is trying to reach.
A useful way to think about reinforcement learning is to imagine a beginner learning a new game. The learner does not start with perfect knowledge. Instead, it tries moves, sees what happens, notices what helps, and gradually changes its behavior. In machine terms, the learner is the agent. The game board, rules, obstacles, and changing situation are the environment. The possible moves are actions. Points gained or lost are rewards. The thing the learner is ultimately trying to achieve is the goal.
These words may sound simple, but they matter a lot. Many beginner mistakes in reinforcement learning come from describing the problem badly. If you define the agent incorrectly, the system may be trying to control the wrong thing. If you define the environment too loosely, the learning process becomes confusing. If the rewards are poorly chosen, the machine may learn behavior that looks smart to the score but foolish in the real world. Good reinforcement learning starts with clear problem framing.
Here is the basic workflow. First, the agent observes the current situation. Second, it chooses an action. Third, the environment changes in response. Fourth, the agent receives a reward, penalty, or no signal at all. Then the cycle repeats. Over many repeats, the agent learns which actions tend to lead to better outcomes. This is why rewards shape behavior so strongly: they are the feedback signal that tells the system what was helpful and what was harmful.
Engineering judgment matters here. In a toy maze, the setup is easy to see. In a real robot, delivery system, or recommendation engine, it is much harder. You must decide what counts as an action, what should be treated as part of the environment, when an episode starts and ends, and what success really means. This chapter will help you map simple tasks into clear reinforcement learning parts so you can recognize these patterns in games, mazes, and real machine tasks.
As you read, keep one practical question in mind: if you were building a learning system for a maze, a simple game, or a robot task, how would you divide the world into these pieces? That skill of splitting a problem into agent and environment parts is one of the foundations of reinforcement learning.
Practice note for Name the core parts of a reinforcement learning system: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Connect actions to rewards and consequences: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for See how goals guide learning behavior: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Map a simple task into agent and environment parts: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
The agent is the part of the system that makes decisions. If you imagine a mouse in a maze, the mouse is the agent. If you imagine a game-playing program, the software choosing moves is the agent. If you imagine a warehouse robot, the controller deciding how to move and what to pick up is the agent. The agent is not the whole system. It is the learner or decision-maker inside the system.
Beginners often think the agent is just a machine or robot body. In reinforcement learning, that is not quite right. The body may be visible, but the agent is really the decision process behind it. In other words, the wheels, sensors, and arms may be physical hardware, but the agent is the part that says, "Given what I know now, I will do this next." That distinction matters because reinforcement learning is about learning decisions, not just building devices.
A practical way to identify the agent is to ask: Who chooses the next action? Whatever chooses is the agent. In a video game, it may press left, right, jump, or wait. In a thermostat-like control task, it may increase heat, lower heat, or do nothing. In a recommendation task, it may choose which item to show next. If there is a choice, there is an agent role somewhere.
The agent usually does not know the best behavior at the beginning. It must improve over time. That improvement comes from experience. The agent tries actions, sees consequences, and adjusts. This is what makes reinforcement learning different from a fixed rule system. A fixed rule system always follows hand-written instructions. A reinforcement learning agent changes its behavior because of feedback from the environment.
Good engineering judgment means keeping the agent definition narrow and useful. If you define too much as part of the agent, the problem becomes vague. If you define too little, the agent may have no meaningful control. A clear agent has real choices and a real chance to improve. That is the foundation for every reinforcement learning system.
The environment is everything outside the agent that the agent interacts with. In a maze, the walls, paths, exit, and trap locations are part of the environment. In a board game, the game state and rules are part of the environment. In a robot task, the floor, objects, battery level, and even moving obstacles may be part of the environment. The environment responds to the agent's actions and creates the situations the agent must handle.
A simple test is this: if the agent acts, what changes in response? That changing world is the environment. The environment presents the current situation, often called the state or observation, and then updates after the agent acts. For example, if a robot turns left, the environment changes because the robot now faces a different direction. If a game agent moves onto a treasure square, the environment changes because the treasure may disappear and the score may increase.
For beginners, one common mistake is to treat the environment as passive background. In reinforcement learning, the environment is active in the sense that it produces consequences. It may be predictable, like a simple grid maze, or uncertain, like traffic, weather, or human behavior. This is why reinforcement learning often feels more like interaction than calculation. The agent is not solving one static problem. It is acting inside a world that keeps responding.
When designing a system, you must decide what belongs in the environment. If you are training a cleaning robot, room layout, furniture position, dirt spots, and charging stations belong there. If you leave out important parts, the learning task becomes unrealistic. If you include too much detail too early, training may become slow and difficult. Strong practical design usually starts with a simple environment that captures the key challenge, then adds complexity step by step.
Thinking clearly about the environment helps you see reinforcement learning in everyday language: the agent is learning how to behave in a world that answers back. That is the heart of the interaction loop.
Actions are the choices available to the agent at each step. In a maze, the actions might be move up, down, left, or right. In a simple game, they might be jump, duck, move, or wait. In a robot arm task, an action might be rotate slightly, open the gripper, or move forward. Actions are important because learning can only happen through choice. If there are no meaningful choices, there is nothing to learn.
Not every action is equally useful in every situation. Moving left may be smart in one part of a maze and terrible in another. This is where reinforcement learning becomes more than random trial and error. Over time, the agent learns to connect situations with better actions. It begins to understand consequences. That connection between action and consequence is one of the central lessons of this chapter.
In practice, action design is an engineering decision. If actions are too broad, the agent may not have enough control. If actions are too fine-grained, learning may become slow. For example, telling a robot only "go to target" may be too high-level for learning basic movement, while controlling every motor at every tiny time step may be too detailed for a beginner system. Good action spaces are simple enough to learn from but rich enough to solve the task.
A common beginner mistake is to assume an action has value by itself. It does not. An action matters because of what happens after it. The same action can be good, bad, or neutral depending on the environment and the goal. In a racing game, accelerating is often useful, but near a sharp turn it may cause a crash. In a maze, moving toward the exit is useful unless there is a hidden trap. Reinforcement learning teaches the agent to judge actions by results, not by labels.
This is also why repeated experience matters. One good outcome may be luck. Many repeated outcomes reveal a pattern. Through that pattern, the agent slowly improves its choices.
Rewards are the feedback signals that tell the agent how well it is doing. A positive reward means something good happened. A penalty, often represented as a negative reward, means something bad happened. Sometimes the agent gets zero reward, which means nothing especially helpful or harmful happened at that moment. These signals guide learning because the agent tries to increase rewards over time.
Consider a maze example. Reaching the exit might give +10. Hitting a trap might give -10. Taking each step might give -1 to encourage shorter paths. In a game, winning might give a large positive reward and losing a large negative one. In a robot task, successfully picking up an object might give a reward, while dropping it or colliding with a wall might cause a penalty. Rewards connect actions to consequences in a measurable way.
But reward design is also where many systems go wrong. The machine does exactly what the reward encourages, not what the designer vaguely hoped for. If you reward clicks in a recommendation system without caring about quality, the system may learn to show attention-grabbing but unhelpful content. If you reward a cleaning robot only for speed, it may race through the room and miss dirt. This is a key practical lesson: bad rewards create bad results.
Strong engineering judgment means designing rewards that reflect real success, not just a shortcut metric. Sometimes one reward is not enough. You may need a mix, such as rewarding task completion, penalizing wasted time, and penalizing unsafe behavior. Even then, trade-offs appear. Too much penalty can make the agent overly cautious. Too much reward for a single behavior can make it ignore everything else.
When beginners ask why reinforcement learning behavior can look strange, the answer is often simple: the reward system shaped that behavior. Rewards are powerful because they define what improvement means. If you want the agent to learn well, you must be very careful about what you reward.
The goal of a reinforcement learning system is the long-term outcome the agent is trying to achieve. Usually, that means collecting as much reward as possible over time, not just chasing the biggest immediate reward. This distinction is important. A short-term action may look attractive but hurt the final result. Good reinforcement learning behavior balances immediate consequences with future ones.
Take a simple game as an example. An agent may collect a small reward now by taking an easy path, but that path could block access to a larger reward later. In a robot navigation task, a shortcut may save time but increase collision risk. The true goal is not just "get something good right now." It is "act in a way that leads to the best overall outcome." That is why goals guide learning behavior so strongly.
Rules define what is allowed and how the environment works. In chess, pieces move in specific ways. In a maze, walls block movement. In a delivery task, a robot may need to stay in safe zones and finish before battery runs out. These rules matter because the agent is not learning in an empty space. It is learning inside boundaries. Ignoring the rules leads to a badly framed problem and unrealistic results.
End points, sometimes called terminal states, tell the system when one attempt is over. In a maze, the episode may end when the exit is reached or the agent falls into a trap. In a game, it may end when the player wins, loses, or time runs out. Clear end points help organize learning into complete experiences. They also make rewards easier to interpret because the agent can connect final outcomes to earlier decisions.
A common beginner mistake is to set a goal that sounds nice but cannot be measured. "Be smart" is not a usable goal. "Reach the exit safely in fewer steps" is much better. Good reinforcement learning depends on goals, rules, and stopping points that are concrete enough for a machine to learn from.
One of the most practical skills in reinforcement learning is taking a real situation and mapping it into agent, environment, actions, rewards, and goals. This is where theory becomes useful. If you can describe a problem in these parts, you can start thinking like a reinforcement learning engineer.
Start with a familiar example: a robot vacuum. The agent is the control system choosing what to do next. The environment is the room, furniture, dirt, walls, and charging dock. The actions are move forward, turn, dock, or change cleaning mode. The rewards might include positive points for cleaning dirt and negative points for bumping into obstacles or wasting battery. The goal is to clean efficiently and safely before power runs out. Once framed this way, the task becomes much easier to reason about.
Here is another example: a game character in a maze. The agent is the character controller. The environment is the maze layout, rewards, traps, and exit. Actions are movement directions. Rewards come from progress, treasure, or escaping. The goal is to reach the end with the best total outcome. This example shows how even simple tasks contain all the core parts of reinforcement learning.
When mapping real tasks, ask four practical questions. First, who is making decisions? Second, what world reacts to those decisions? Third, what choices are available? Fourth, what feedback tells us whether the choices were good? These questions help separate reinforcement learning from other AI approaches. In supervised learning, a model learns from labeled examples. In reinforcement learning, it learns by acting and receiving consequences.
Common mistakes include choosing rewards that are easy to count but unrelated to real success, giving the agent actions it cannot realistically perform, or forgetting to define clear end conditions. Start simple. Build a small version of the task. Check whether the rewards produce the behavior you actually want. Then expand carefully.
If you can take an everyday situation and identify the agent, environment, action, reward, and goal, you have taken a major step toward understanding reinforcement learning in a practical, usable way.
1. In reinforcement learning, what is the agent?
2. Which sequence best matches the basic reinforcement learning workflow described in the chapter?
3. Why are rewards so important in reinforcement learning?
4. What problem can happen if rewards are poorly chosen?
5. In a simple maze task, which description best shows correct problem framing?
One of the most important ideas in reinforcement learning is that better decisions usually do not appear all at once. They emerge slowly through repeated interaction. An agent tries something, the environment responds, and a reward signal gives a clue about whether that choice helped or hurt. Then the agent tries again. Over many rounds, patterns begin to form. Choices that often lead to better results become more likely in the future, while choices that lead to poor results become less attractive. This process is simple in spirit, but powerful in practice.
For a complete beginner, it helps to think of reinforcement learning as guided practice. A child learning to ride a bicycle, a person learning to park a car, or a pet learning a new trick all improve through repetition and feedback. Early attempts are clumsy. Some actions fail. A few work surprisingly well. What matters is not perfection on the first try, but the ability to learn from what happened. In reinforcement learning, a machine follows this same broad pattern. It does not magically know the best action. It gathers experience and gradually shapes its behavior.
This chapter focuses on how that improvement happens over time. We will connect repeated practice, memory of past results, and the difference between short-term and long-term reward. We will also look at how good and bad choices leave traces in future behavior. This matters because reinforcement learning is not just about acting. It is about updating. The update step is where experience becomes learning.
There is also an engineering side to this topic. In real systems, improvement depends on how rewards are designed, how stable the environment is, and whether the agent gets enough chances to explore. If feedback is noisy, delayed, or inconsistent, learning becomes slow or misleading. If rewards point in the wrong direction, the agent can become very good at the wrong task. So when we say that better decisions emerge over time, we do not mean that improvement is automatic. We mean that the learning loop, when designed well, can convert trial and error into useful behavior.
As you read the sections in this chapter, keep one practical image in mind: an agent standing at a decision point again and again. Each time it acts, it gains a little more evidence about what works. Over time, that evidence changes behavior. That is the heart of reinforcement learning.
Practice note for Understand repeated practice as a path to improvement: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Explain why memory of past results matters: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for See how good and bad choices shape future behavior: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Follow a beginner-friendly example of gradual learning: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand repeated practice as a path to improvement: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Reinforcement learning depends on a loop: act, observe, evaluate, and adjust. This loop repeats many times. A single action rarely teaches enough. But when the same type of decision appears again and again, the agent can collect evidence. That is why repeated practice is a path to improvement. Each round adds another example of what happened after a particular choice.
Imagine a robot trying to move across a room without hitting furniture. On one attempt it turns too sharply and bumps a chair. On another attempt it moves more slowly and gets farther. On a third attempt it chooses a safer path and reaches the goal. None of these trials alone creates mastery. But together, they build a picture. The robot starts to link actions with outcomes. Safe paths become more attractive because they repeatedly lead to better rewards.
This cycle is called a learning loop because the output of one round affects the next round. The agent is not simply acting randomly forever. It is using feedback to update future decisions. If a move often brings a positive result, the agent should be more willing to try it again in similar situations. If a move often causes trouble, the agent should reduce its preference for that move.
From an engineering perspective, the loop must be clear and measurable. The environment needs to respond in a way the agent can detect. The reward must be connected to the goal. The agent also needs enough repetitions to see patterns, because early results can be misleading. A good choice may fail once by bad luck, and a bad choice may succeed once by accident. Repetition smooths out these one-off events and reveals the real trend.
A common beginner mistake is expecting fast perfection. Reinforcement learning usually starts messy. The important question is not “Is the agent perfect yet?” but “Is the agent improving with experience?” If the answer is yes, the loop is working.
To improve, an agent must do more than repeat the same action. It has to try different actions and compare the results. This is how good and bad choices shape future behavior. If the agent never experiments, it may get stuck with a mediocre habit. If it experiments too much without learning, it wastes time. Reinforcement learning balances both needs: trying options and using outcomes to judge them.
Think of a simple maze. At one junction, the agent can go left, right, or forward. Going left leads to a dead end. Going right leads closer to the exit. Going forward loops back to the start. The agent does not know this in advance. It must discover it. After many attempts, the outcomes can be compared. Right begins to look better than left or forward because it more often produces progress and reward.
This comparison process is practical, not magical. The agent is collecting evidence about which action tends to work better in a given situation. In many systems, this means assigning higher estimated value to better actions. These estimates are not perfect truths. They are working beliefs based on experience. As new results arrive, the beliefs change.
Engineering judgment matters here because not all comparisons are fair. Maybe one action was tried only once while another was tried fifty times. Maybe one result was affected by noise in the environment. Maybe rewards were delayed and not immediately visible. A careful designer makes sure the agent has enough opportunities to sample actions and enough signal to compare them sensibly.
A common mistake is rewarding only obvious success and ignoring useful partial progress. In a maze, waiting until the final exit to give feedback can make learning very slow. Small signals for moving closer may help the agent compare actions sooner. But those signals must be chosen carefully, or the agent may optimize the shortcut reward instead of the real goal.
Improvement over time requires memory. If an agent forgot every past result, each step would be a fresh guess. Memory of past results matters because it lets the agent carry lessons forward. In reinforcement learning, this memory may be simple, such as stored values for actions in certain situations, or more complex, such as parameters inside a learned model. The exact form can vary, but the purpose is the same: preserve experience so future choices can benefit from it.
Consider a game where a character can pick up a key, open a door, and reach treasure. Early on, the agent may not understand why picking up the key matters. But if experience shows that key-related actions eventually lead to success, the learning system needs some way to remember that pattern. Without memory, the agent cannot connect past effort to future gain.
Memory also helps the agent become more stable. Once it has seen that a certain action is often useful in a certain state, it does not need to rediscover that fact from zero every time. This makes behavior more efficient. It also explains why trained agents can look more confident than untrained ones. They are acting on accumulated history, not isolated moments.
In practical systems, memory must be updated carefully. If the agent changes its beliefs too aggressively after one surprising outcome, it may become unstable. If it changes too slowly, learning becomes sluggish. This is a common design trade-off. Engineers often tune how strongly new experiences should influence existing knowledge.
Another common mistake is assuming memory means perfect recall. Reinforcement learning memory is usually approximate. It captures useful patterns, not every exact detail. What matters is whether the stored information helps future decisions become better on average. Good memory in reinforcement learning is not about remembering everything. It is about remembering what is useful for action.
One of the hardest and most important ideas in reinforcement learning is that the best immediate reward is not always the best overall choice. An agent may need to accept a small short-term cost to reach a larger long-term gain. This is where gradual learning becomes especially meaningful. Over repeated experience, the agent can discover that some decisions only make sense when their later consequences are included.
Imagine a robot vacuum deciding whether to go around a table leg or stop and turn back. Turning back may save effort right now, which seems like a short-term reward. But going around the obstacle may lead to cleaning the rest of the room, which creates more total reward over time. A beginner-friendly way to say this is simple: sometimes the smart choice does not feel best in the first second.
Games offer another clear example. In chess-like tasks, sacrificing a piece may look bad immediately, but it can create a winning position later. In a maze, taking a few extra steps to fetch a key may delay reward now, yet unlock the final goal. The agent must learn to judge actions by where they lead, not only by what they give instantly.
This is also where bad reward design causes bad results. If only immediate reward is emphasized, the agent may learn shortcuts that look successful at first but fail the real objective. For example, a delivery robot rewarded only for speed might drive unsafely. A game agent rewarded only for collecting items might ignore the actual win condition. The reward should reflect the full goal, not just an easy-to-measure piece of it.
Good engineering judgment means checking whether the reward encourages durable success. If the system is improving at the reward but not at the real task, the wrong lesson is being taught. Long-term behavior must be part of the design.
Feedback is the teacher in reinforcement learning, but it only works well when it is consistent. If the same action in the same kind of situation sometimes gets rewarded and sometimes gets punished for no clear reason, the agent struggles to form stable preferences. Learning becomes noisy and slow. Consistent feedback helps the agent trust the patterns it sees.
Suppose an agent is learning to keep a drone level in the air. If smooth flight is rewarded consistently, then the agent can gradually connect balancing actions with success. But if the sensor system is unreliable and occasionally reports smooth flight as failure, the agent receives mixed messages. It may stop trusting useful actions or overreact to random events. The result is confusion rather than steady improvement.
Consistency does not mean the world must be perfectly simple. Real environments often contain randomness. What matters is that the reward system still reflects the goal in a reliable way over time. An occasional surprise is acceptable. Constant contradiction is not. The agent needs enough signal to separate good choices from bad ones.
This has practical consequences in engineering. Reward definitions should be stable across episodes. Measurement systems should be checked for errors. If multiple rewards are combined, they should not pull the agent in opposite directions unless that trade-off is intentional and carefully designed. For example, rewarding both maximum speed and absolute safety may require thoughtful balancing so the agent does not receive a confusing objective.
A common mistake is changing the reward rules too often during training. Beginners sometimes keep adjusting feedback every time the agent behaves oddly. While iteration is sometimes necessary, constant reward changes can prevent the agent from settling into real learning. Consistency gives behavior a clear direction and makes progress easier to interpret.
Let us put the chapter ideas together with a simple example. Imagine a small agent in a grid maze. Its goal is to reach a charging station. Each move costs a tiny amount of reward, hitting a wall gives a bigger penalty, and reaching the charger gives a strong positive reward. At the start, the agent knows nothing. Its behavior looks random because it has not yet learned which moves help.
In the first few attempts, it bumps into walls, loops in circles, and rarely reaches the charger. This is normal. Repetition is building experience. After several episodes, the agent begins to notice that some moves from certain positions often end badly, while others occasionally lead forward. It updates its memory. Now its behavior is still imperfect, but slightly less random.
By the middle stage of learning, the agent has enough history to compare actions more clearly. It starts avoiding obvious dead ends. It may still make mistakes, especially when two choices seem similar, but it reaches the goal more often than before. This is an important beginner lesson: improvement often appears as fewer bad choices before it appears as consistently perfect choices.
Later, the agent begins to favor a route that is not just successful, but efficient. It has learned something about long-term reward. A path with one awkward turn may be better overall than a path with many small penalties. Because the reward is consistent, the agent can trust that this route is genuinely better, not a one-time accident.
From an engineering viewpoint, this step-by-step improvement is exactly what you want to observe. You are looking for trends: fewer collisions, more successful episodes, shorter paths, more stable behavior. If these measures improve over time, the learning process is healthy. If reward rises but real performance does not, you may have a reward design problem.
This example shows the full beginner-friendly story of reinforcement learning: try actions, receive feedback, remember outcomes, compare choices, and slowly shift toward better behavior. Better decisions emerge over time because the agent is not frozen. It is shaped by experience.
1. According to the chapter, how do better decisions usually develop in reinforcement learning?
2. Why is memory of past results important for an agent?
3. What role do rewards play in shaping behavior over time?
4. Which statement best matches the chapter’s point about short-term and long-term reward?
5. Why might improvement fail to happen automatically in a real reinforcement learning system?
In earlier chapters, you met the main parts of reinforcement learning: an agent, an environment, actions, rewards, and a goal. Now we move into one of the most important ideas in the whole subject: how an agent decides whether to keep doing what already seems to work, or to try something new that might work even better. This is the everyday problem of exploration versus exploitation. Even humans face it all the time. Should you order your favorite meal again, or try a new dish that could be better or worse? Should you take the usual route to work, or test a different road that may save time?
In reinforcement learning, this choice is not just a side detail. It is central to how learning happens. If an agent only repeats old choices, it may get stuck with a mediocre strategy and never discover a better one. If it explores too much, it wastes time, makes too many bad moves, and may fail to collect steady rewards. Good learning comes from managing both sides with care.
This chapter explains exploration and exploitation in plain language and shows why mistakes are not just allowed, but often necessary. We will look at the cost of exploring too little and too much, and we will connect the idea to simple examples like games, route finding, and everyday tasks. Along the way, we will also discuss engineering judgment: in real systems, the goal is not random behavior forever, but controlled learning that becomes smarter over time.
One helpful way to think about reinforcement learning is this: the agent starts out uncertain. It does not know the best action everywhere. It has to build that knowledge from experience. Experience comes from acting, and acting includes occasional wrong choices. Those wrong choices provide information. That information can improve future decisions, as long as rewards are designed well and the learning process keeps moving toward the goal.
So this chapter is about smarter choices, not perfect choices. A beginner agent is not expected to know the best move immediately. Instead, it learns by trying, observing results, and adjusting. The practical question is how to do that without becoming reckless or overly timid. That is the heart of this chapter.
Practice note for Define exploration and exploitation in plain language: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand why mistakes are useful for learning: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Recognize the cost of exploring too much or too little: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Apply the idea to games, routes, and simple tasks: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Define exploration and exploitation in plain language: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand why mistakes are useful for learning: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Imagine an agent in a maze that finds a path to the exit worth 5 reward points. If it always repeats that same path forever, it may look successful. But what if another path gives 10 points, is shorter, or is safer? By only repeating what it already knows, the agent never discovers that better option. This is the core problem with relying only on past choices.
For complete beginners, the easiest way to understand this is to think about limited knowledge. At the start, an agent does not know whether a choice is truly best. It only knows what it has experienced so far. If the first acceptable action gives a small reward, the agent may wrongly treat it like the best answer. This creates a trap: “good enough” blocks “possibly much better.”
In engineering terms, repeating only old successful actions can cause the agent to settle too early. It becomes predictable and stable, but not necessarily smart. Early rewards can be misleading, especially when the environment is large or uncertain. A game-playing agent might find a move that wins against weak opponents, yet lose badly against stronger ones because it never tested alternatives.
This matters in practical systems. A delivery robot that always uses the same corridor may ignore a faster route. A recommendation system that keeps showing the same popular item may miss items users would like even more. A route-planning system that never tests a slightly different pattern may fail to adapt when traffic changes.
The lesson is simple: repeating old choices feels safe, but safety without learning can become stagnation. Reinforcement learning needs room to discover. An agent must sometimes step beyond its current habits so it can improve its understanding of the environment and find better long-term rewards.
Exploration means trying actions that the agent does not fully understand yet. In plain language, it is curiosity in action. But in reinforcement learning, good exploration is not just random chaos. It is better thought of as safe curiosity: testing unknown options in a way that increases learning without causing unnecessary damage.
Suppose a robot is learning to move across a room. If it always repeats one movement pattern, it learns very little. If it occasionally tries a new direction or speed, it gathers useful information. Some attempts will be worse than others. That is expected. The purpose is to learn how the environment reacts. Exploration creates the raw experience the agent needs.
There is an important practical point here. Beginners often imagine exploration as “do anything at all.” Real systems rarely work that way. Engineers usually put boundaries around exploration. A robot may be allowed to test different movements, but not at dangerous speeds. A game agent may try unusual moves, but still stay within the game rules. A route system may test alternate roads, but avoid roads known to be closed or highly unsafe.
That is why the phrase safe curiosity is useful. Exploration is valuable when it teaches the agent something new while respecting practical limits. In many reinforcement learning setups, especially in real-world tasks, exploration must be controlled. You want enough variety to learn, but not so much that the system becomes reckless.
Exploration is also how agents discover hidden opportunities. A new route might save time. A different strategy in a game might produce higher rewards. A change in machine settings might improve efficiency. Without exploration, these gains remain invisible. So mistakes during exploration are not signs that learning failed. Often, they are exactly how learning begins.
Exploitation means choosing the action that currently seems to give the best result. If exploration is trying new options, exploitation is making practical use of what has already been learned. In everyday life, this is like taking your usual fast route home because past experience suggests it works well.
Exploitation is important because reinforcement learning is not only about discovering information. It is also about earning rewards. If an agent explores forever and never uses what it has learned, it may gather many experiences but perform poorly. At some point, the agent should take advantage of successful patterns.
Notice the phrase “seems best.” That phrase matters. The agent does not have perfect knowledge. It only has estimates based on past rewards. So exploitation is not guaranteed to be truly optimal. It is simply the best action according to current understanding. This is why exploitation alone can sometimes lock in a mistaken belief if the agent learned from too little experience.
In practical tasks, exploitation is what makes a system useful. A warehouse robot that has learned a reliable path should usually use it. A game agent that has found a strong move should often choose it. A thermostat-like controller that has identified an efficient setting should apply it most of the time. Exploitation turns learning into performance.
Still, good engineering judgment reminds us that exploitation should not happen blindly. Environments can change. Traffic patterns shift. Opponents adapt. User preferences move over time. If a system only exploits and never checks whether conditions changed, yesterday’s best action may become today’s poor choice. So exploitation is necessary, but it works best when paired with occasional continued learning.
The real challenge in reinforcement learning is not understanding exploration and exploitation separately. It is learning how to balance them. Too much exploration means the agent keeps testing weak actions and collects lower rewards than necessary. Too little exploration means the agent may never discover better actions and stays stuck with an average strategy.
A useful beginner-friendly example is choosing a lunch spot. If you always go to the same place, you may miss a better restaurant nearby. If you try a different place every day, you may waste money and end up disappointed often. A smart strategy is to explore sometimes, especially early on, then gradually rely more on the places that proved good. Reinforcement learning often follows this exact logic.
From an engineering point of view, a common pattern is to explore more at the beginning and reduce exploration later. Early in learning, the agent knows little, so trying many options makes sense. Later, after collecting enough experience, it should exploit more often because it has stronger evidence about what works. This is a practical workflow used in many systems: start broad, then become more selective.
The balance also depends on cost. In a simple video game, exploration may be cheap because mistakes are easy to recover from. In a robot controlling physical equipment, exploration can be expensive or risky, so it must be more cautious. This is where judgment matters. There is no single perfect amount of exploration for all tasks.
Good reinforcement learning is therefore a balancing act. The agent must learn enough to improve, but also choose well enough to make progress toward the goal. Smarter choices come from managing both needs together, not from maximizing only one.
Mistakes are a normal part of reinforcement learning. In fact, they are often one of the main sources of useful information. If an agent tries an action and receives a poor reward, that result teaches it something: this choice may be unhelpful in this situation. Over time, many such experiences help shape better behavior.
For beginners, this can feel strange because we often think success alone drives learning. But trial and error means both parts matter. Reward tells the agent what worked well. Low reward or penalty tells it what worked badly. Together, these signals gradually push the agent toward better decisions.
Consider a game agent that repeatedly loses when it attacks too early. Those losses are not wasted if the learning system updates its strategy. The agent may begin to wait, gather resources, and attack at a better time. A route-planning agent may discover that a road often causes delays. A cleaning robot may learn that entering a cluttered corner in a certain way causes it to get stuck. In each case, failure provides direction.
The practical danger is not failure itself, but failure without adjustment. If rewards are badly designed, the agent may learn the wrong lesson. If the system never updates enough, the same mistakes may repeat. If exploration is too aggressive, the agent may fail so often that it struggles to make steady progress. This is why reinforcement learning is not just about allowing mistakes. It is about turning mistakes into improved choices.
Good engineering practice treats errors as data. Watch what failed, ask why it failed, and connect the outcome back to the reward signal and policy updates. The goal is not to avoid every wrong move. The goal is to make wrong moves less common and less costly over time. That is what real learning looks like.
These ideas become clearer when we connect them to everyday reinforcement learning examples. In games, an agent may first try many moves, including poor ones, to discover which strategies lead to winning rewards. As learning improves, it uses the strongest moves more often, while still occasionally testing alternatives in case a better strategy exists.
In route selection, an agent choosing roads between two points must decide whether to keep taking the current best route or sample another path. If traffic conditions change, a route that used to be best may no longer be ideal. Occasional exploration helps the system stay updated instead of becoming outdated. This is a strong example of why exploitation alone is not enough in changing environments.
In simple robot tasks, such as picking up objects or moving around a room, exploration helps the robot discover efficient motions. Exploitation helps it repeat the smoother, faster patterns that earn better rewards. If the robot bumps into objects during learning, those mistakes can guide future adjustments, especially if penalties are designed clearly and safely.
Recommendation systems also show this pattern. If a system only recommends what has worked before, users may see the same narrow set of choices. Some exploration allows the system to test other items and possibly discover stronger matches. Too much exploration, however, can annoy users by showing weak suggestions. So practical systems aim for measured experimentation.
The broader outcome is better decision making under uncertainty. Reinforcement learning teaches agents to improve not by being told every correct answer, but by interacting, receiving rewards, making mistakes, and adjusting. Exploration opens the door to discovery. Exploitation captures the value of what has been learned. The best results come when these are combined thoughtfully. That is how agents move from random trial and error toward purposeful, smarter behavior.
1. What is the main difference between exploration and exploitation in reinforcement learning?
2. Why can mistakes be useful for a learning agent?
3. What is a likely result if an agent explores too little?
4. According to the chapter, what is the goal in real systems?
5. Which example best shows the exploration-versus-exploitation tradeoff?
Reinforcement learning, or RL, becomes easier to understand when you stop thinking of it as a mysterious AI technique and start seeing it as a way to make decisions through experience. An RL system tries actions, notices what happens, and slowly learns which choices lead to better results over time. In simple terms, it is like training by practice. The agent is the decision-maker, the environment is the world it operates in, actions are the choices it can make, rewards are the signals that say “good” or “bad,” and the goal is to collect as much useful reward as possible.
In real life, reinforcement learning is most useful when a system must make a sequence of decisions, not just one. A single prediction is often better handled by other machine learning methods. But when each choice changes what happens next, RL becomes interesting. A robot deciding how to move, a traffic controller changing signal timing, or a recommendation system choosing what to show next can all be viewed as decision problems that unfold step by step.
This chapter focuses on where RL is actually used, what makes those uses a good fit, and where the method struggles. You will compare examples from games, robots, recommendations, and large operational systems such as routing and resource allocation. You will also learn an important engineering lesson: just because RL can be applied to a problem does not mean it should be. Good practitioners look at benefits, limits, safety, cost, and available data before choosing an approach.
A common beginner mistake is to think RL is mainly for game-playing because many famous demos involve chess, Go, or video games. Games are only the easiest place to see the idea clearly. The bigger lesson from games is that RL works best when the agent can try many actions, receive feedback, and improve from repeated experience. In the real world, repeated experience may be expensive, risky, or slow, so engineers often use simulations, careful reward design, and strong safety constraints.
As you read this chapter, keep asking four practical questions. What is the agent trying to optimize? What feedback signal tells it whether it is doing well? How expensive is trial and error? And what could go wrong if the reward is badly designed? Those questions matter more than the buzzword. They help you recognize practical uses of reinforcement learning, compare different application areas, understand the benefits and limits, and decide when RL is not the best tool.
In the sections that follow, you will see the same basic RL pattern appear in different settings. The details change, but the core idea stays the same: act, observe, reward, adjust, and improve over time.
Practice note for Identify practical uses of reinforcement learning: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Compare game, robot, and recommendation examples: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand benefits and limits of the approach: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Recognize when reinforcement learning is not the best choice: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Games are the clearest starting point for seeing reinforcement learning in action. In a game, the agent chooses moves, the environment responds according to the rules, and rewards are easy to define. Winning might give a large reward, losing a penalty, and intermediate points can encourage progress. This setup is useful because it creates a full learning loop with clear goals and repeatable practice.
Why do researchers love games so much? Because games are safe and fast compared with the physical world. An AI can play thousands or millions of rounds without breaking equipment or risking human safety. That makes trial and error practical. It also allows engineers to test many reward designs and training settings. If a reward causes odd behavior, they can inspect the results and change it. This is one reason game environments became training grounds for RL methods long before many business applications were ready.
Simulations extend this idea beyond entertainment. A simulation is a digital model of a real system, such as a warehouse, a factory line, or a driving scenario. Instead of learning directly in traffic or on expensive machines, the agent can practice in a virtual version first. This lowers cost and risk. For example, an autonomous driving system can try lane changes, braking strategies, and route decisions in simulation before touching a real car.
Still, there is an important engineering challenge called the simulation-to-real gap. A policy that works perfectly in a simulator may fail in the real world if the simulator is too simple or unrealistic. Engineers reduce this problem by making simulations varied and noisy, not perfectly clean. They add random weather, delays, imperfect sensors, or unexpected obstacles so the agent learns robust behavior rather than memorizing a narrow virtual world.
A practical workflow often looks like this:
The main benefit of games and simulations is cheap practice. The main limit is realism. This example teaches a broader lesson: RL works best when experience can be gathered safely and repeatedly. If practice is too slow or dangerous, then even a strong RL method may be the wrong choice.
Robotics is one of the most natural examples of reinforcement learning because robots must make ongoing decisions in changing environments. A robot arm may need to grasp objects, a mobile robot may need to navigate a room, and a warehouse robot may need to choose efficient movement paths while avoiding collisions. These are not one-time predictions. They are sequences of actions where each movement affects what comes next.
In simple RL terms, the robot is the agent, the physical world is the environment, motor commands are actions, and rewards reflect success. A reward might increase when the robot picks up an object correctly, moves closer to a target, or completes a task faster. But designing those rewards is harder than it sounds. If you reward only speed, the robot may move dangerously. If you reward only success at the end, learning may be too slow because useful feedback comes too late.
That is why robot training often uses shaped rewards, where smaller rewards guide progress toward the final goal. For example, a grasping robot may get partial reward for reaching the object, more for making contact, and a larger reward for lifting it securely. This can speed up learning, but engineers must be careful. Too much shaping can accidentally teach the robot to chase the reward signal instead of the real task.
Another practical issue is data collection. Real robots wear out, break, and operate slowly. You cannot always afford endless physical experiments. So many teams train partly in simulation, then fine-tune on the real robot. Others use imitation learning first, where the robot copies examples from humans, and then apply RL to improve performance further. This combined approach is often more practical than pure RL from scratch.
Common mistakes in robotics RL include ignoring safety boundaries, using unrealistic rewards, and testing in conditions that are too clean. Good engineering judgment means adding limits: safe speed caps, stop conditions, human oversight, and fallback controls. In real deployments, practical outcomes matter more than elegant theory. A slightly less optimal policy that is reliable and safe is usually better than a high-scoring one that behaves unpredictably. Robotics shows both the promise and the challenge of RL: experience can create skill, but real-world learning must be carefully managed.
Many beginners are surprised to learn that reinforcement learning can be used in recommendation systems. At first glance, recommending a movie, a song, or a product seems like a simple prediction task. Sometimes it is. But when a system chooses what to show now in order to improve long-term user satisfaction later, the problem becomes sequential. That makes RL relevant.
Imagine a video platform deciding which clip to recommend next. If it only optimizes for the next click, it may show sensational content that wins attention briefly but hurts user trust over time. An RL view asks a bigger question: what sequence of recommendations leads to a better long-term outcome, such as satisfaction, retention, learning, or healthy engagement? In that setup, the platform is the agent, the user context is part of the environment, displayed items are actions, and rewards may include clicks, watch time, completion, return visits, or explicit ratings.
This is powerful, but also risky. Rewards in recommendation systems can easily be badly designed. If watch time is the only reward, the system may learn to promote addictive or low-quality content. If purchases are over-rewarded, it may push items that maximize short-term sales while damaging customer trust. This is a direct real-life example of why rewards shape behavior and why bad rewards create bad results.
Adaptive systems go beyond media recommendations. Educational apps can choose the next exercise based on a learner’s progress. Customer support tools can decide what help step to show next. Marketing systems can choose which message to send and when. In each case, the best current action depends on how it affects future behavior, not just the immediate response.
In practice, many production systems use a mix of methods. Supervised learning may predict user preferences, while RL handles the longer-term decision policy. Engineers often start with small, constrained experiments because online trial and error affects real people. Careful evaluation, fairness checks, and user protections are essential. The benefit of RL here is adaptability over time. The limit is that human behavior is complex, noisy, and ethically sensitive. Good systems optimize not only for business outcomes, but also for user well-being and trust.
Reinforcement learning is also used in operational decision problems where resources must be allocated over time. These are settings such as traffic signal control, network routing, delivery scheduling, energy management, and inventory decisions. What these problems share is that choices made now affect future congestion, waiting time, cost, and system performance.
Take traffic lights as an example. A controller can be treated as the agent. The environment includes cars, road conditions, and intersections. Actions are signal changes, such as extending a green light or switching phases. Rewards may reflect reduced waiting time, smoother traffic flow, shorter queues, or lower fuel waste. Unlike a fixed timing plan, an RL-based system can adapt to changing conditions such as rush hour, special events, or accidents.
Routing problems work similarly. In a delivery network, actions include assigning vehicles, selecting routes, or changing priorities. Rewards may include faster deliveries, lower fuel cost, or better use of available drivers. In computer networks, RL may help route data to reduce delay or avoid overloaded paths. In energy systems, it may decide when to store, release, or shift power usage to balance demand and cost.
These applications show an important strength of RL: it can learn strategies in dynamic systems with delayed consequences. A decision that looks good right now may create congestion later. RL is designed to consider that long-term effect. However, operational systems are rarely simple. They involve many constraints, incomplete information, and large action spaces. As a result, successful projects usually combine RL with rules, forecasts, optimization tools, or human oversight.
A practical engineering approach is to begin with a simulator or historical replay environment, compare the RL policy against baseline methods, and only deploy gradually. Teams monitor not just average improvement but also rare failure cases. A routing policy that is efficient most days but collapses during disruptions may be unacceptable. In these domains, practical outcomes mean robustness, predictability, and measurable value, not just better reward during training.
Reinforcement learning sounds exciting because it promises improvement through trial and error, but real-life deployment brings serious limits. The first is sample efficiency. Many RL systems need huge amounts of experience before they perform well. In a video game that may be fine. In medicine, finance, robotics, or public systems, trial and error can be too expensive or too risky. If every mistake harms people, damages equipment, or loses money, random exploration is not acceptable.
The second limit is reward design. Beginners often think rewards are simple, but they are one of the hardest parts of RL. A badly chosen reward can produce clever but unwanted behavior. A warehouse robot might learn to block sensors if that falsely improves its reward. A recommendation system might maximize clicks while reducing user well-being. A traffic system might improve one intersection while making another much worse. The agent does not understand your intention. It follows the signal you provide.
Another concern is stability. RL training can be unpredictable. Performance may improve, then collapse, then recover. Small changes in settings can produce very different results. This is frustrating in safety-critical applications where consistency matters more than raw performance. It is one reason many organizations avoid RL unless they truly need sequential optimization.
Safety requires more than a clever algorithm. Good teams add safeguards such as:
There is also a business cost. RL projects often require simulation, infrastructure, monitoring, and specialized expertise. If a simpler method solves 90% of the problem with far less effort, that may be the better choice. A practical engineer asks not “Can RL be used here?” but “Is RL worth the cost, risk, and complexity here?” Understanding these limits is part of becoming realistic about AI, not less excited by it.
One of the most valuable skills in AI is knowing when not to use reinforcement learning. RL is not a general replacement for all machine learning. It is best for problems with repeated decisions, delayed consequences, and a need to optimize long-term outcomes. If your task is simply to classify emails, detect spam, recognize images, or predict a number from historical examples, supervised learning is usually the better fit. If you want to group similar customers without labels, unsupervised methods may be more appropriate.
Ask a few practical questions before choosing RL. First, is this a sequential decision problem? If each action changes the next situation, RL may help. Second, do you have a meaningful reward signal? If success cannot be measured clearly, RL will struggle. Third, can the system safely gather experience, either in reality or in simulation? If not, training may be impractical. Fourth, do you need adaptation over time, or is a fixed predictive model enough?
For example, recommending one product based on past purchases might be handled well by supervised learning. But choosing a sequence of recommendations to improve long-term satisfaction might justify RL. Predicting travel demand may use forecasting models. Deciding how to change traffic lights in response to that demand may involve RL. In robotics, imitation learning can teach a robot from demonstrations, while RL can refine performance through additional practice.
A common mistake is forcing RL onto a problem because it sounds advanced. That often leads to unnecessary complexity, poor results, and hard-to-maintain systems. A better approach is to compare methods honestly. Build a baseline. Measure whether sequential decision-making really matters. Consider hybrid systems, where RL handles only the part of the problem that truly requires planning over time.
The final lesson of this chapter is simple: reinforcement learning is powerful when actions today affect rewards tomorrow. It shines in games, robots, adaptive recommendations, and resource decisions. But it demands careful reward design, safe training, and strong engineering judgment. The smartest use of RL is not the most dramatic use. It is the one where trial and error can be guided safely toward a clear, useful goal.
1. What kind of problem is reinforcement learning strongest at solving, according to the chapter?
2. Why are games often used to explain reinforcement learning?
3. Why do engineers often use simulation in real-world reinforcement learning?
4. What is a major risk of badly designed rewards in reinforcement learning?
5. According to the chapter, when might reinforcement learning not be the best choice?
By this point, you have seen the main parts of reinforcement learning: an agent takes actions in an environment, receives rewards, and slowly improves through trial and error. In this chapter, we shift from understanding reinforcement learning as a student to thinking like a beginner designer. That means asking a new kind of question: if you wanted a machine to learn a task, how would you set that task up clearly enough for learning to happen?
This is where reinforcement learning becomes both practical and surprisingly human. A designer must decide what the agent can observe, what choices it is allowed to make, what counts as success, and how progress will be measured over time. A small change in any of these decisions can completely change the behavior that emerges. In other words, reinforcement learning is not only about algorithms. It is also about careful problem framing and good judgment.
A useful mental model is to imagine that you are writing the rules for a training game. You are not telling the agent exactly what to do step by step. Instead, you are building a world where useful behavior is more rewarding than unhelpful behavior. If the world is designed well, the agent can discover a good strategy. If the world is designed poorly, the agent may learn something strange, wasteful, unsafe, or unfair.
Throughout this chapter, we will practice breaking beginner problems into states, actions, and rewards. We will look at common design mistakes in simple learning setups, including reward choices that accidentally encourage bad behavior. We will also discuss practical and ethical concerns, because in real systems, the goal is not just to make something learn. The goal is to make it learn in a way that is reliable, understandable, and aligned with human intentions.
Think of this chapter as your complete beginner mental model for reinforcement learning design. You do not need advanced math to benefit from it. What you need is the ability to describe a task clearly, notice when a reward is misleading, and ask whether improved scores actually mean improved behavior. Those are the habits that separate passive understanding from real design thinking.
As you read, keep one idea in mind: in reinforcement learning, behavior follows incentives. Good incentives can produce helpful skill. Bad incentives can produce impressive-looking but unwanted results. A beginner who understands that principle already has a strong foundation for future study and practical experimentation.
Practice note for Break a beginner problem into states, actions, and rewards: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Spot common design mistakes in simple learning setups: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Describe ethical and practical concerns clearly: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Finish with a complete mental model of beginner RL: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Break a beginner problem into states, actions, and rewards: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
The first job of a reinforcement learning designer is to turn a vague goal into a simple learning task. Beginners often start with a sentence like, “I want the robot to clean the room,” or “I want the game character to reach the exit.” That is a good starting point, but it is not yet a training setup. To create a learning task, you must identify the state, the actions, the reward, and the goal condition. This process is how you make the problem concrete enough for a learning system to interact with it.
Start with state. Ask: what information does the agent need at each moment? In a maze, the state might include the agent’s current location and maybe nearby walls. In a simple robot task, the state might include position, battery level, and whether an object is being carried. A common beginner mistake is giving too little state information, which makes the task confusing, or too much irrelevant information, which makes learning harder than necessary.
Next define the actions. These are the choices available to the agent. In a grid maze, the actions may be move up, down, left, or right. In a balancing task, the actions may be push left, push right, or do nothing. Good action design keeps the task manageable. If the action set is unrealistic or overly large, the agent may struggle. If it is too limited, the agent may never be able to solve the problem at all.
Then define the reward and the goal. The goal is what success looks like overall. The reward is the feedback given along the way. For example, in a maze, the goal is to reach the exit. The reward might be +10 for reaching the exit and -1 for each step, encouraging shorter paths. Notice that the goal and the reward are related but not identical. The goal is your intention. The reward is the signal the agent actually learns from.
A practical workflow is:
Engineering judgment matters here. A clean beginner task should be small, testable, and easy to explain. If you cannot describe the task clearly to another person, the learning setup is probably still too fuzzy. Good reinforcement learning design begins with sharp definitions, not with code.
Rewards are the steering wheel of reinforcement learning. They do not directly tell the agent what action to take, but they shape what patterns become attractive over time. Choosing useful rewards is one of the most important and difficult design decisions. If the reward matches the behavior you truly want, learning can be efficient and meaningful. If the reward is weak, delayed, or misleading, the agent may drift into poor strategies.
Beginners should first ask a basic question: what behavior do I want to encourage? In a navigation task, you may want the agent to reach a destination quickly and safely. That suggests rewarding success, giving a small penalty for each time step, and possibly giving a larger penalty for collisions. In a game, you may reward points scored and penalize losing. In a warehouse robot example, you may reward successful deliveries but penalize dropping items or running out of battery.
A useful reward often has three qualities. First, it is aligned with the real goal. Second, it is informative, meaning it gives enough feedback for the agent to learn. Third, it is balanced, so one part of the reward does not overwhelm everything else. If a robot gets huge reward for speed and only tiny penalty for crashes, you should expect reckless behavior. That is not a bug in learning. It is the agent following the incentives you created.
There are also timing choices. Sometimes rewards only appear at the end, such as winning or losing a game. That can work, but it may make learning slow because the agent gets very little feedback during the episode. In simple tasks, designers often add small intermediate rewards to help guide progress. For example, a maze agent might get a tiny positive reward for moving closer to the exit. This can speed learning, but it must be done carefully so the agent does not learn to chase the shaping reward instead of truly finishing the task.
Practical reward design usually includes iteration:
The key lesson is simple: rewards shape behavior. They are not just scores on a screen. They are the agent’s training signal. A designer should treat reward choices with the same care that a teacher gives to grading rules or a manager gives to performance incentives. What you reward is what you are likely to get.
One of the most important beginner lessons in reinforcement learning is that badly designed rewards can create badly designed behavior. This is not rare. It is one of the central practical challenges of the field. An agent does not understand your intention in a human way. It only responds to the reward structure and the environment you give it. That means it may find shortcuts, loopholes, or strange tricks that raise reward without solving the real problem properly.
Imagine a cleaning robot rewarded for “amount of movement” because the designer thinks active robots clean more. The robot may learn to move constantly without actually cleaning anything. Imagine a game agent rewarded for staying alive, but not strongly rewarded for winning. It may learn to hide forever. Imagine a warehouse robot rewarded only for deliveries completed. It may rush, damage items, or block other robots if those costs are not penalized. These are classic examples of unintended behavior caused by incomplete incentives.
Common design mistakes include:
A practical way to spot mistakes is to watch the learned behavior, not just the final numbers. Ask, “If I saw a human doing this, would I say they understood the task?” If the answer is no, the reward may be wrong even if the score looks impressive. This is a powerful designer habit: inspect behavior qualitatively, then compare it with the stated goal.
Another useful method is stress testing. Put the agent in slightly different starting conditions. Change the map. Add a new obstacle. See whether it still behaves sensibly. If performance collapses or behavior becomes odd, the policy may have learned a brittle trick rather than a general solution.
Good reinforcement learning design requires humility. Expect that the agent will exploit weak spots in the setup. That expectation is healthy, not pessimistic. It pushes you to build better environments, clearer rewards, and stronger evaluation methods. The practical outcome is a safer and more reliable system, even at the beginner level.
In reinforcement learning, improvement is not always obvious. A single good episode may happen by luck. A single bad episode may happen even when the agent has learned something useful. That is why designers need a measurement mindset. Instead of asking, “Did it work once?” ask, “Is performance getting better over many trials, and is that improvement meaningful?”
The most common measurement is average reward over time. If the average reward rises across many episodes, that often suggests the agent is learning. But average reward alone is not enough. You should also measure task-specific outcomes. In a maze, track success rate, average number of steps to the goal, and number of collisions with walls if relevant. In a robot task, track successful completions, safety violations, time used, and wasted energy. Good evaluation includes more than one number.
Another important concept is separating training performance from evaluation performance. During training, the agent often explores random actions. That means rewards may look noisy. For evaluation, you test the current policy more cleanly to see what it can do. This helps you understand whether the agent truly improved or whether recent results were caused by randomness.
Practical measurement habits include:
A beginner-friendly mental model is this: reward tells the agent what to chase, but evaluation tells the designer what is actually happening. Those are not the same thing. Sometimes reward goes up while useful behavior does not. Sometimes a small drop in reward is acceptable if safety improves. Engineering judgment means deciding what “better” really means for your task.
When you measure carefully, you avoid fooling yourself. You can see whether the learning setup is helping, whether reward design is causing distortions, and whether the agent is becoming more reliable over time. That makes reinforcement learning more than trial and error. It becomes disciplined experimentation.
Even simple reinforcement learning examples raise ethical and practical questions. Once a system learns from rewards, the designer has real influence over what behavior is encouraged. That means responsibility matters. A reward setup can unintentionally promote unsafe, unfair, or harmful behavior if it ignores important human values.
Start with safety. If an agent controls something in the physical world, such as a robot, a drone, or a vehicle, unsafe exploration can be costly. A beginner should understand that not every task is appropriate for unrestricted trial and error. Many real systems need simulations, safety limits, emergency stop rules, and human review before deployment. The more powerful the system, the more important these protections become.
Fairness also matters. Suppose an RL system is used to allocate limited resources, recommend opportunities, or make decisions affecting different groups of people. If the reward is based only on efficiency or profit, the system may develop patterns that disadvantage some users. The learning process itself is not morally aware. It follows the objective given. This is why people must decide what trade-offs are acceptable and what outcomes are not.
Human oversight is the practical answer. Designers, testers, and stakeholders should review both the reward design and the observed behavior. Ask questions like:
For beginners, the key takeaway is not that reinforcement learning is dangerous by itself. The key takeaway is that learned behavior reflects the setup created by humans. Therefore, responsible design includes technical performance, but it also includes values, constraints, and accountability. A good RL designer thinks not only, “Can the agent learn this?” but also, “Should it learn this in this way, under these conditions?” That mindset is part of maturity in AI practice.
You now have a complete beginner mental model of reinforcement learning. You can describe the agent, environment, actions, rewards, and goals in everyday language. You understand that machines improve by trial and error over time. You can also explain why reinforcement learning differs from approaches that learn from labeled examples or simply follow fixed rules. Most importantly, you have started to think like a designer: someone who frames the task, shapes incentives, checks results, and watches for unintended behavior.
If you continue learning, your next step should not be to chase the most advanced algorithm names. Start by practicing on small environments. Take simple examples such as mazes, grid worlds, toy games, or basic robot simulators. For each one, write down the state, action set, episode rules, reward design, and evaluation metrics before thinking about implementation details. This habit will strengthen your intuition faster than memorizing formulas alone.
A practical beginner roadmap looks like this:
As you move forward, keep your judgment sharp. When you see an RL success story, ask what the reward was, what the agent could observe, what mistakes were possible, and how improvement was measured. Those questions will help you read examples more intelligently and build your own with more confidence.
This chapter closes the beginner journey with a design perspective. Reinforcement learning is not magic. It is a structured way to create feedback-driven behavior. When the task is clear, the rewards are thoughtful, the evaluation is honest, and human oversight is present, reinforcement learning becomes easier to understand and far more practical to use. That is the mindset to carry beyond this course.
1. According to the chapter, what is a reinforcement learning designer mainly responsible for?
2. Which idea best matches the chapter’s "training game" mental model?
3. What is a common design mistake highlighted in the chapter?
4. Why does the chapter include ethical and practical concerns in reinforcement learning design?
5. What core principle does the chapter say beginners should keep in mind?
- Learning Evolved.
- Intelligence Amplified.


