Reinforcement Learning — Beginner
Understand how machines learn from rewards, step by step
This beginner course explains reinforcement learning in the simplest possible way. If you have ever wondered how a machine can improve by trial and error, this course gives you a clear answer without assuming any background in AI, coding, or data science. You will learn from everyday examples first, then move into the basic ideas that power many modern decision-making systems.
Reinforcement learning can sound technical, but the core idea is easy to grasp: a system tries actions, receives feedback, and slowly gets better at choosing what works. This course treats that idea like a short book. Each chapter builds on the one before it, so you never feel dropped into advanced material too early.
Many introductions to AI start with math, formulas, or programming. This one does not. Instead, you will begin with familiar ideas such as rewards, choices, mistakes, repetition, and improvement. Once those ideas feel natural, you will learn the key parts of reinforcement learning: the agent, the environment, states, actions, rewards, and policies.
The first chapter introduces learning by trial and error using simple examples from daily life. The second chapter adds structure by showing how a learning system is built from states, actions, rewards, and episodes. In the third chapter, you will see how repeated experience helps a machine improve over time and why long-term results matter.
Next, the course explores one of the most important ideas in reinforcement learning: the balance between trying something new and choosing what already seems best. After that, you will learn the idea of value, which helps explain how a machine estimates whether a choice is likely to lead to better outcomes. The final chapter brings everything together with real-world applications, practical limits, and safe next steps for continued learning.
By the end of the course, you will not be an expert researcher, and that is not the goal. Instead, you will have a solid beginner understanding of how reinforcement learning works and why it matters. You will be able to describe core concepts in your own words, follow simple examples, and recognize where this kind of AI is used in the real world.
This course is made for complete beginners. It is ideal for curious learners, students, professionals changing careers, and anyone who wants to understand AI at a deeper level without getting lost in technical detail. It is also useful for readers who have seen terms like reinforcement learning, rewards, or agents online and want a calm, structured explanation.
If you are ready to begin, Register free and start learning today. If you want to explore more beginner-friendly AI topics first, you can also browse all courses on the platform.
Reinforcement learning is one of the most interesting areas of AI because it focuses on decisions, feedback, and improvement. It helps explain how machines can learn to play games, guide robots, recommend actions, and make better choices over time. Even if you never plan to build these systems yourself, understanding the basic ideas will help you follow modern AI conversations with confidence.
This course gives you that foundation in a clear, practical, and approachable way. It is the right first step for anyone who wants to understand how machines improve by trial and error.
Senior Machine Learning Engineer
Sofia Chen is a machine learning engineer who specializes in making AI concepts clear for first-time learners. She has designed beginner training programs on decision-making systems, practical AI, and learning algorithms for students and professionals.
Reinforcement learning sounds technical, but the core idea is very familiar: learning by trying things, seeing what happens, and adjusting future behavior based on the results. A child learns how hard to push a door. A person learns which route gets to work faster. A pet learns that sitting calmly may lead to a treat. In each case, behavior changes because feedback arrives after an action. That is the heart of reinforcement learning, often shortened to RL.
In machine learning, reinforcement learning describes a setup where a system is not simply told the correct answer for every situation. Instead, it interacts with a world, makes choices, and receives signals that suggest whether those choices were helpful. Over time, it tries to improve. This is why people often describe RL as learning through trial and error. The phrase is simple, but it contains an important engineering idea: good performance usually comes from many repeated interactions, not from a single perfect instruction.
To understand RL clearly, you only need a few building blocks. There is an agent, which is the learner or decision-maker. There is an environment, which is everything the agent interacts with. At any moment, the environment is in some state, meaning the current situation. The agent selects an action, and the environment responds. Then the agent receives a reward, a signal that says how good or bad the outcome was. This cycle repeats again and again. From the outside, it looks like a loop of observe, choose, respond, and improve.
One reason RL matters is that not all useful actions pay off immediately. Sometimes a choice brings a small reward now but causes problems later. Sometimes a choice is inconvenient now but opens the way to a better long-term result. This is one of the most important shifts in thinking for beginners. Reinforcement learning is not just about collecting the next reward. It is about learning which patterns of actions lead to the best future outcomes over time.
Another important idea is the balance between exploration and exploitation. Exploration means trying unfamiliar actions to learn more about what is possible. Exploitation means using the best option found so far. If a machine only exploits, it may get stuck with a choice that seems good but is not actually the best. If it only explores, it may never settle down and perform well. Practical reinforcement learning always involves judgement about this trade-off.
This chapter introduces these ideas in plain language. You will see how rewards guide behavior, why the agent and environment matter, how trial and error leads to improvement, and how long-term thinking changes decision-making. You will also meet simple examples of value-based learning without heavy math. By the end of the chapter, reinforcement learning should feel less like an abstract research topic and more like a practical way to describe how a machine can learn from feedback.
As you read the sections that follow, focus on the flow of events rather than on formulas. A machine observes a situation, takes an action, gets feedback, and updates its future choices. That simple loop is the foundation for everything else in reinforcement learning.
Practice note for See how learning by trial and error works: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand why rewards guide behavior: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Before thinking about machines, it helps to notice how often people learn from feedback in ordinary life. If you touch a hot pan, the result teaches you immediately to be more careful. If you try a shortcut to school and arrive late, you remember that outcome next time. If you study with one method and your test score improves, that positive result encourages you to repeat the method. None of these situations requires a formal teacher to label every step as correct or incorrect. The world itself provides feedback.
Reinforcement learning borrows this idea. Instead of feeding a machine a giant list of right answers, we place it in a situation where it can make choices and experience consequences. This is useful when there is no simple answer key for every moment. For example, in a game, a robot task, or a recommendation system, the best move depends on what happened before and what may happen next. The machine has to discover good behavior by interacting.
A practical way to think about this is as a loop. First, the learner notices the current situation. Second, it chooses something to do. Third, the world responds. Fourth, the learner receives a signal that suggests whether the result was helpful. Then the loop begins again. Improvement comes from repetition. One action alone does not teach much. Patterns across many attempts teach a lot.
Beginners sometimes make a common mistake here: they assume trial and error means random guessing forever. That is not the goal. Random actions may help at the beginning, but learning means gradually using feedback to make better decisions. A good RL system does not merely try things; it remembers which kinds of choices tend to work and shifts its behavior over time.
In engineering practice, this idea matters because feedback is often noisy or delayed. A route-planning system may choose a road that looks fast but later runs into traffic. A game-playing agent may make a move that seems harmless now but causes trouble ten steps later. So when we say a machine learns from feedback, we mean it learns from a chain of actions and outcomes, not only from one isolated moment.
Reinforcement learning is different from other common kinds of machine learning because it focuses on sequential decisions. In supervised learning, a model is trained from examples with known answers, such as an image paired with the correct label. In unsupervised learning, a model looks for patterns in data without target labels. In reinforcement learning, the learner is not given the correct move at each step. Instead, it must act first and then learn from the consequences.
This difference is important because many real problems are not one-shot predictions. Driving, inventory control, game playing, and robot movement all involve a series of decisions. One action changes the next situation. That means the learner must think beyond immediate results. An action that looks good in the short term may create a worse state later. An action that seems costly now may lead to better options afterward. RL is designed for that kind of decision-making.
Another thing that makes RL different is the reward signal. In supervised learning, the model can compare its output directly to the correct answer. In RL, feedback is often less direct. The learner may only receive a score, a success signal, or a penalty. It must work backward from that feedback to understand which choices were responsible. This challenge is one reason RL can be powerful but also harder to design well.
Engineering judgement matters here. A beginner may think, “Just reward the machine when it does something good.” But defining “good” is often the hard part. If rewards are poorly chosen, the system can learn strange behavior. For example, if a cleaning robot is rewarded only for movement, it may learn to drive around quickly instead of cleaning. If a game agent is rewarded only for collecting one easy item, it may ignore the real goal of winning. RL systems learn what the reward encourages, not what the designer vaguely intended.
So the practical difference is this: reinforcement learning is about an interactive learner, repeated decisions, uncertain consequences, and a reward signal that must stand in for the real goal. That combination is what makes the field both exciting and demanding.
To read reinforcement learning examples confidently, you need to be comfortable with a small set of terms. The agent is the decision-maker. It could be a robot, a game-playing program, a recommendation system, or even a simulated character. The environment is everything outside the agent that responds to its actions. The environment might be a video game, a warehouse, a webpage, a traffic system, or a simple simulated grid.
The state describes the current situation. In a maze, the state might be the agent’s location. In a game, it could include the board position, score, and remaining time. In a robot task, it might include camera readings, speed, and battery level. The state matters because the best action depends on where the agent currently is. The same action can be helpful in one state and harmful in another.
The goal is usually expressed through rewards, but it is useful to talk about it separately. The real goal might be to reach a destination, maximize sales, keep a machine stable, or win a game. The reward is the signal used to push the agent toward that goal. Good RL design requires the reward to match the goal as closely as possible.
It also helps to understand that the environment is not always simple or predictable. Some environments are stable: the same action in the same state usually gives the same result. Others are uncertain: small changes or randomness can produce different outcomes. This affects how hard learning becomes. In a noisy environment, the agent needs enough experience to tell the difference between a lucky outcome and a genuinely good strategy.
A common beginner mistake is to treat these terms as vocabulary only. They are more than labels. They help you map any RL problem into a clear structure. Ask: Who is acting? What world is responding? What information describes the current situation? What counts as success? Once you can answer those questions, the problem becomes much easier to reason about, even before discussing algorithms.
At each step in reinforcement learning, the agent chooses an action. That action changes what happens next. The environment responds with an outcome, which usually means a new state and a reward. This sounds simple, but it captures a deep idea: actions do not matter only because of what they produce immediately. They matter because they shape future possibilities.
Suppose an agent is learning to move through a maze. One action may lead toward the exit but pass near a trap. Another action may be slower at first but much safer overall. If the agent looks only at the next reward, it may repeatedly choose the wrong path. This is why reinforcement learning cares about long-term reward, not just instant payoff. The best action is often the one that leads to the best future, not the one that feels best right now.
This is where rewards guide behavior. A positive reward encourages the agent to repeat similar actions in similar states. A negative reward discourages behavior. A zero reward may mean the action did not matter much, or that feedback is being delayed. Over many experiences, the agent builds an internal sense of which situations are promising and which are risky. In value-based learning, this often means estimating how good it is to be in a state or to take a certain action there, even before the final result arrives.
From a practical engineering view, reward design needs care. If rewards are too sparse, the agent may struggle to learn because useful feedback comes too rarely. If rewards are too frequent but poorly aligned, the agent may optimize the wrong thing. Designers often need to test whether rewards truly encourage the intended behavior. This is not just a technical detail; it is one of the main reasons RL projects succeed or fail.
A useful habit is to ask two questions about any reward: What behavior does it encourage now, and what behavior might it encourage after many repetitions? The second question is crucial because RL systems can exploit loopholes in badly designed rewards much faster than humans expect.
Reinforcement learning improves behavior gradually. At the beginning, an agent often knows very little. It may make poor choices simply because it has not seen enough outcomes yet. Over time, it starts to connect situations with likely results. A good choice is not defined by luck on one attempt; it is a choice that tends to lead to better long-term rewards across repeated experience.
This is also where the balance between exploration and exploitation becomes essential. Exploration means trying actions that may be uncertain, just to learn what happens. Exploitation means using the action that currently appears best. If the agent never explores, it may miss a much better option. Imagine always ordering the first meal you ever liked at a restaurant. You avoid risk, but you never discover anything better. If the agent explores too much, however, it keeps taking unnecessary risks and may perform badly even after it has learned a decent strategy.
In practical systems, this balance is rarely perfect. Designers tune it based on cost, safety, and available data. A game-playing agent can usually afford lots of exploration in simulation. A medical or industrial system cannot. That means engineering judgement matters: where is trial and error acceptable, and where must it be constrained?
Another beginner misunderstanding is to think improvement always moves smoothly upward. Real learning is often uneven. The agent tries something new, performance dips, then recovers and surpasses the old level. This is normal. Learning from feedback involves uncertainty, revision, and adjustment. What matters is the trend over many episodes, not one short run.
Value-based learning gives a simple way to picture improvement without heavy math. The agent gradually builds estimates of “how good” actions or states are. When it sees a familiar situation again, it can prefer the option with higher estimated value. Those estimates are not magic; they are summaries of past feedback used to guide better future decisions.
Real-world examples make reinforcement learning easier to understand because they show the agent, environment, action, and reward in one picture. Consider a robot vacuum. The agent is the vacuum’s control system. The environment is the room with furniture, dirt, and walls. The state might include sensor readings and current position. Actions include moving forward, turning, or docking. Rewards might be positive for covering dirty floor and negative for collisions or wasted battery. Over time, the system can learn movement patterns that clean efficiently rather than wandering aimlessly.
Now consider a navigation app choosing routes. The agent is the route-selection system. The environment includes roads, traffic, and travel conditions. The state might include current location, time, and congestion data. An action is a route recommendation. The reward might reflect lower travel time and fewer delays. A route that seems fast now may become bad later because of traffic buildup, so this example highlights the difference between immediate reward and long-term outcome.
A third example is a simple game character learning to avoid obstacles and collect useful items. Each move is an action. The game screen is the environment. The score change acts like reward. The character may first bump into obstacles often, but through repeated attempts it starts to favor actions that produce better total scores. This is a clean example of trial and error because the feedback is clear and fast.
These examples also show a practical limit. RL works best when the system can gather enough feedback and when the reward meaningfully reflects the goal. If feedback is too rare, too noisy, or too expensive to obtain, learning may be slow or unreliable. That does not make RL useless, but it means the setup must be chosen carefully.
By this point, the main idea should be clear. Reinforcement learning is a framework for decision-making through feedback. The agent acts in an environment, receives rewards, learns from outcomes, and gradually improves. Whether the task is a game, a robot, or a route planner, the same basic loop applies. Once you can see that loop in everyday examples, the subject becomes much more intuitive.
1. What best describes reinforcement learning in this chapter?
2. In reinforcement learning, what is the agent?
3. Why are rewards important in reinforcement learning?
4. Why does the chapter emphasize long-term outcomes and not just the next reward?
5. What is the main challenge in balancing exploration and exploitation?
In the first chapter, you met the big idea of reinforcement learning: a system improves by trying actions and seeing what happens. In this chapter, we slow that idea down and look at the parts that make it work. Reinforcement learning can sound abstract at first, but its core pieces are simple. There is an agent, which is the learner or decision-maker. There is an environment, which is the world the agent interacts with. The agent observes a state, chooses an action, and receives a reward. Then the process repeats. That is the basic loop.
If you keep those pieces clear, most beginner confusion disappears. A state is the situation the agent is currently in. An action is one of the choices available at that moment. A reward is feedback from the environment about what just happened. The agent is not handed a full instruction manual. Instead, it must learn from trial and error which actions tend to lead to better outcomes over time.
This chapter focuses on four practical lessons. First, you will understand states, actions, and rewards clearly enough to describe them in plain language. Second, you will see how decisions happen one step at a time rather than all at once. Third, you will learn how episodes begin and end, which matters because many learning tasks are broken into attempts. Fourth, you will build a mental model of the learning loop that engineers use when designing reinforcement learning systems.
A useful way to think about reinforcement learning is to imagine training a pet, learning a game, or navigating a city. At each moment, you do not solve the entire future in one giant calculation. You look at where you are now, choose a next move, and update your understanding based on the result. Machines do something similar, although usually with more repetition and less intuition.
One important engineering judgment is deciding what information belongs in the state, what actions are allowed, and how rewards are assigned. These choices shape the learning problem. If the state leaves out critical information, the agent may never learn sensible behavior. If the actions are too limited, it may be unable to reach a good outcome. If the rewards are misleading, it may learn the wrong habit. In practice, many reinforcement learning problems are difficult not because the algorithm is mysterious, but because the problem has been framed poorly.
Another key idea in this chapter is the difference between immediate rewards and long-term rewards. Beginners often assume the agent should always chase the biggest reward right now. But many tasks require patience. A move that looks bad in the short term can create a better position later. A move that looks good immediately can lead to a dead end. Reinforcement learning is powerful because it tries to learn which short-term decisions support long-term success.
You will also see why exploration and exploitation must be balanced. Exploitation means using what the agent already believes is best. Exploration means trying alternatives to gather new information. Too much exploitation can trap the agent in mediocre behavior. Too much exploration can make learning noisy and inefficient. Good systems allow some room to try, fail, and discover better options.
By the end of this chapter, you should be able to read a small reinforcement learning example and explain what is happening without heavy math. That is the goal: a sturdy mental model. Once the building blocks are clear, later topics such as value functions and action selection become much easier to understand.
Practice note for Understand states, actions, and rewards clearly: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for See how decisions happen one step at a time: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
A state is the current situation from the agent's point of view. It answers the question, “What does the agent know right now that helps it choose its next action?” In a board game, the state might be the arrangement of pieces. In a robot task, it might include position, speed, and sensor readings. In a simple app recommendation problem, it might include what the user just clicked and what page they are currently on.
For beginners, the easiest mistake is to think a state is just a label like “good” or “bad.” A useful state is usually more specific. It contains the relevant information needed for a decision. If you are teaching an agent to navigate a maze, the state may be its current square in the maze. If you leave that out, the agent has no way to tell whether it is near the goal or stuck near a wall.
Engineering judgment matters here. A state should include enough information to make a good decision, but not so much irrelevant detail that learning becomes confusing or slow. If you include random background information that does not affect outcomes, the agent may waste time trying to find patterns that are not real. If you exclude critical facts, the same visible state may actually require different actions, and the agent will seem inconsistent.
Think of a driving example. If the state includes the traffic light color and the car's speed, the agent can make a reasonable choice. If the state omits the traffic light entirely, the agent may appear reckless because it cannot tell whether stopping or going is appropriate. In reinforcement learning, behavior can only be as good as the information available in the state.
A practical test is this: if two situations look identical to the agent, should it always make the same decision? If the answer is no, then the state definition is probably missing something important. Good state design is one of the most important foundations of a learning system.
An action is a choice the agent can make in a given state. Actions are the handles the agent can pull to change what happens next. In a game, actions might be move left, move right, jump, or wait. In a recommendation system, actions might be which item to show. In a thermostat controller, actions might be increase temperature, decrease temperature, or keep it steady.
Actions sound simple, but their design strongly affects learning. If the action set is too small, the agent may not have enough flexibility to solve the task. If it is too large or too fine-grained, learning may become slow because the agent has too many choices to compare. A beginner-friendly way to picture this is a remote control. If your remote has only one button, it is not very useful. If it has 500 confusing buttons, it is hard to use well. Reinforcement learning systems face the same trade-off.
Decisions also happen one step at a time. The agent does not choose an entire life plan in one move. It selects one action in the current state, the environment responds, and then the next decision comes. This step-by-step view is essential. It explains how a machine can solve tasks that unfold over time, such as balancing, navigating, or scheduling.
Another practical issue is that not every action makes sense in every state. In some systems, impossible actions are removed. In others, they are allowed but lead to poor outcomes or no change. Designers must be careful here. If the environment responds unpredictably to impossible actions, the agent may learn messy or fragile behavior.
Finally, actions connect directly to exploration and exploitation. Exploitation means choosing the action that currently looks best. Exploration means trying a different action to learn whether it may be better than expected. Without exploration, the agent may keep repeating a familiar action and never discover a smarter strategy. Without enough exploitation, it may spend too long experimenting and fail to benefit from what it has already learned.
A reward is feedback from the environment after an action. It is a signal, not a detailed explanation. This distinction matters. Rewards do not tell the agent exactly what rule to follow. They only indicate whether what just happened was better, worse, or neutral according to the task design.
Imagine teaching a dog with treats. The treat does not contain a sentence like, “Please sit with your back straight and paws aligned.” It simply reinforces behavior that happened just before the treat. Reinforcement learning works similarly. If an action leads closer to a goal, the environment may provide a positive reward. If it causes trouble, the reward may be negative. Some steps may produce zero reward, meaning nothing especially good or bad happened yet.
Beginners often assume reward should be given at every useful moment and should perfectly describe the task. In reality, reward design is delicate. If you reward the wrong thing, the agent may find shortcuts that satisfy the reward but miss the real objective. For example, if a cleaning robot is rewarded only for movement, it may learn to drive around quickly without actually cleaning. The signal must match the true goal as closely as possible.
This is also where immediate and long-term rewards become important. Some actions produce an immediate gain but create future problems. Others have a short-term cost but unlock a better outcome later. A student who studies instead of watching videos may feel an immediate cost but gain a better result over time. An agent must learn to value these long-term effects, not just the next reward.
In practice, engineers watch for reward hacking, where the agent learns to exploit the reward system rather than solve the intended task. That is not the agent being malicious. It is the agent doing exactly what the reward encouraged. Good reward design is clear, aligned with the real goal, and tested with small examples before scaling up.
Many reinforcement learning tasks are organized into episodes. An episode is one full attempt, from a starting situation to an ending condition. A game from start to finish is an episode. A robot trying to reach a target before time runs out can also be an episode. Inside each episode are steps. At each step, the agent observes a state, chooses an action, receives a reward, and moves to a new state.
This structure helps beginners understand that learning is not one endless blur. Instead, it is a sequence of attempts. An episode begins, unfolds step by step, and then ends when the goal is reached, a failure happens, or a limit is met. For example, a maze episode might end when the agent reaches the exit or when it has taken too many moves. A game episode might end with a win, a loss, or a draw.
Why does this matter? Because the meaning of success often depends on the whole episode, not just one step. A move may look unhelpful in isolation but make sense as part of a larger plan. If an agent takes a longer path around an obstacle, that may be a smart choice even if it does not produce an immediate reward.
Engineering teams also use episode design to control training. Short episodes can make feedback faster and easier to analyze. Clear ending conditions prevent the agent from wandering forever. But if episodes are too short, the agent may never experience the consequences of long-term decisions. This is a practical design trade-off.
A common mistake is to confuse the goal with the reward at a single step. The goal usually describes the overall outcome of an episode, while rewards are the signals along the way. Keeping that distinction clear helps you read reinforcement learning examples correctly and understand what the agent is actually optimizing.
The reinforcement learning loop is the repeating pattern that drives learning. It is simple enough to say in one sentence: observe the current state, choose an action, receive a reward, move to the next state, and update future decisions based on that experience. Then do it again. This loop is the heart of reinforcement learning.
It helps to picture the loop as a conversation between agent and environment. The environment presents a situation. The agent responds with an action. The environment answers with consequences: a new state and a reward. Over many repeated interactions, the agent starts to recognize which choices tend to lead to better outcomes.
This is where trial and error becomes meaningful rather than random. Early in learning, the agent may act clumsily because it does not yet know what works. Over time, if the reward signal is useful and the state and action design are sensible, the agent improves. It is not memorizing one script for one moment. It is gradually learning patterns about which actions are promising in which states.
In value-based learning, which you will meet more formally later, the system often tries to estimate how good a state or action is in terms of future reward. You do not need heavy math to grasp the idea. Think of it as a score for expected usefulness. If turning right from a certain location usually leads toward success, that action-state pair gets a stronger reputation. If it often leads to failure, its reputation drops.
A practical mindset is to ask, at each part of the loop, “What information is available, what control does the agent have, and what feedback does it receive?” If you can answer those clearly, you can usually explain a reinforcement learning system clearly too.
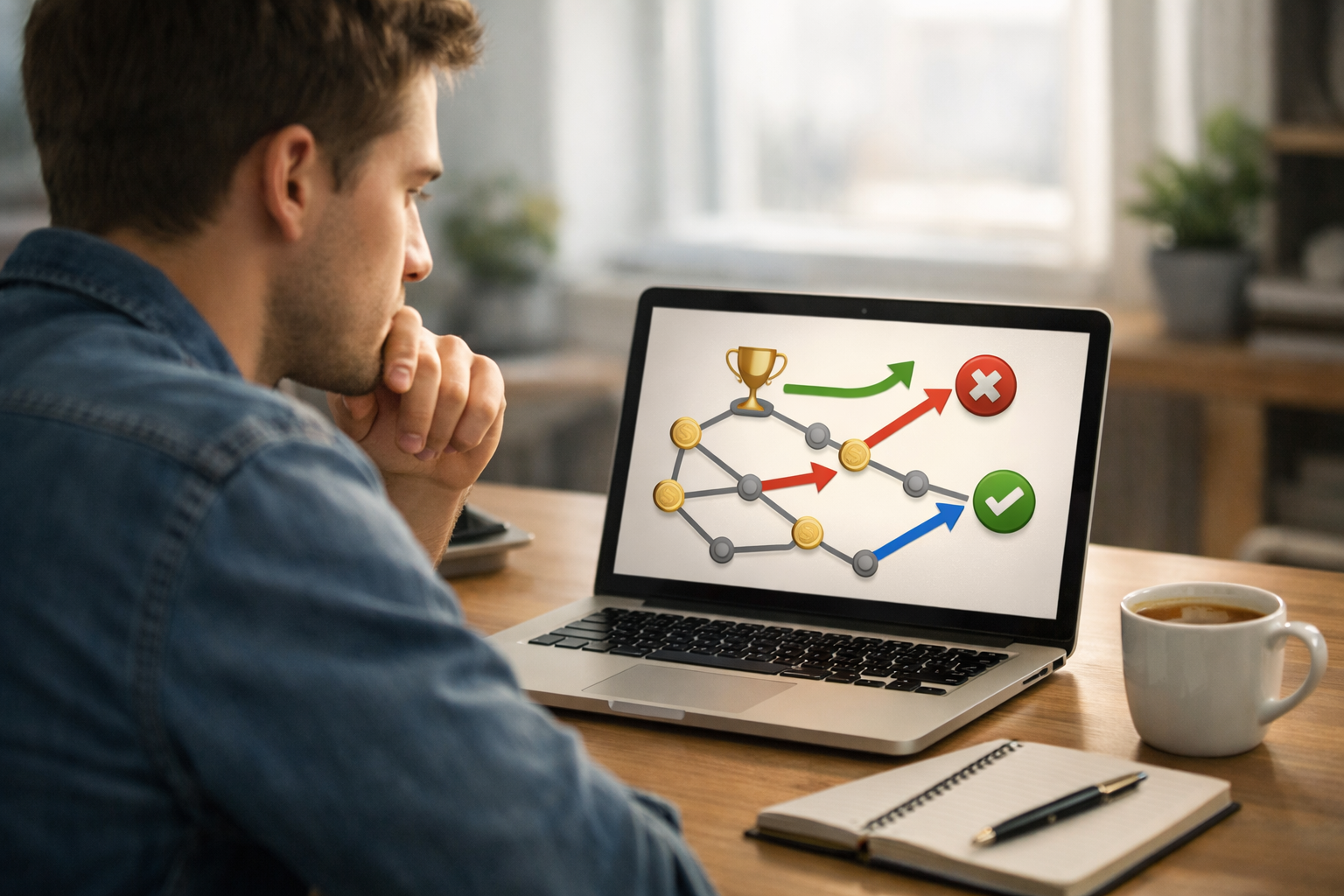
Let us walk through a tiny example. Imagine a robot on a short hallway with three positions: Left, Middle, and Right. The robot starts in the Middle. The goal is to reach Right, where a charging station gives a reward of +10. Moving to Left gives no reward and wastes time. Each move also has a small cost of -1 to encourage shorter solutions. The available actions are move left and move right.
Now describe the building blocks. The states are Left, Middle, and Right. The actions are left or right. The rewards are signals from the environment: +10 for reaching the charger, and -1 for each move. An episode begins when the robot starts in Middle and ends when it reaches Right. This is a complete reinforcement learning problem in miniature.
Suppose on the first episode the robot explores and moves left. It receives -1 and ends up in Left. From Left, it may move right, receive -1, and return to Middle. Then it moves right again, receives -1, and reaches Right for +10. The total result is positive, but not as good as going directly right from the start. Over repeated episodes, the agent compares these outcomes.
What does it learn? It learns that from Middle, moving right tends to produce better long-term reward than moving left. Notice the phrase long-term reward. The first right move from Middle might only give -1 immediately, but it leads directly to the charging station on the next state or ends the episode with success, depending on how the environment is defined. The smart action is not judged only by the first signal but by what follows.
This example also shows exploration and exploitation. If the robot never explores left, it might not know whether left hides an even bigger reward in a more complex hallway. But if it explores left forever, it keeps wasting moves. So a practical learner tries alternatives early, then gradually relies more on the action that has proved better.
The toy example is small, but the logic scales. In larger systems, the states may be richer, the actions more numerous, and the rewards less obvious. Still, the same mental model holds: the agent acts one step at a time, episodes begin and end, rewards guide but do not instruct, and learning comes from repeated interaction with the environment.
1. In reinforcement learning, what is a state?
2. Which sequence best describes the basic learning loop in this chapter?
3. Why can a reinforcement learning problem fail even if the algorithm itself is fine?
4. What is the main lesson about immediate rewards versus long-term rewards?
5. What is the difference between exploration and exploitation?
Reinforcement learning becomes easier to understand when you stop thinking about machines as magically intelligent and start thinking about them as learners that improve through repeated experience. A reinforcement learning system does not usually begin with deep understanding. It begins by trying actions, seeing what happens, and slowly adjusting toward better choices. This is why repetition matters so much. Each attempt gives the system one more piece of evidence about what tends to work, what tends to fail, and what only looks good for a moment.
At the center of this process is a simple loop. An agent is the learner or decision-maker. The environment is the world it interacts with. A state is the situation the agent is currently in. An action is a choice it can make. A reward is the feedback it receives after acting. Reinforcement learning is about improving decisions inside this loop. The machine does not memorize one fixed answer for every possible problem in advance. Instead, it learns from consequences.
Imagine teaching a robot to move through a room toward a charging station. At first, it may turn the wrong way, bump into furniture, or take a long route. But over many tries, it starts connecting situations to outcomes. Turning left near the table may be safer than turning right. Moving straight when the station is visible may lead to faster success. This is not improvement through explanation. It is improvement through interaction.
One of the most important ideas in this chapter is that better decisions often come from many small corrections rather than one big breakthrough. A beginner-friendly way to think about reinforcement learning is this: the agent keeps a running sense of which actions seem promising in which situations. That sense becomes more accurate over time. Some rewards are immediate, such as getting a point for collecting an item. Other rewards are delayed, such as taking a longer route now in order to avoid a penalty later. Good learning systems must handle both.
Another key idea is that a machine needs a practical way to decide what to do next. That decision pattern is called a policy. You do not need advanced math to understand it. A policy is simply the agent's current way of choosing actions. Early in learning, the policy may be poor. After enough experience, it becomes more useful. Good engineering judgment means remembering that the quality of learning depends not only on the algorithm, but also on the reward design, the amount of exploration, and whether the environment gives clear enough feedback.
In practice, beginners often make two mistakes. First, they expect learning to look smooth. It usually does not. Performance can jump, stall, or even temporarily get worse. Second, they assume the biggest immediate reward is always the best target. In reinforcement learning, that is often false. The real goal is usually to maximize useful reward over time, not to chase the fastest visible gain. As you read the sections in this chapter, keep in mind that reinforcement learning is less like memorizing facts and more like building judgment through trial, feedback, and revision.
Practice note for See how repeated experience creates better decisions: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand short-term and long-term reward thinking: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
The heart of reinforcement learning is repetition. A machine does not become better because someone labels every correct answer for it. It becomes better because it acts, observes the result, and uses that result to adjust future choices. This is trial and error in a structured form. The agent is placed in an environment, sees a state, takes an action, receives a reward, and moves into a new state. Then the cycle repeats. Over time, useful patterns begin to appear.
Consider a simple game in which a character must move through a grid to reach a goal. At first, the agent may move randomly. Some moves waste time, some hit obstacles, and a few move closer to the goal. If reaching the goal gives a positive reward and hitting obstacles gives a penalty, the agent can slowly learn which actions tend to help. Repetition matters because one attempt is noisy and incomplete. A single good result may be luck. Many repeated results are evidence.
From an engineering viewpoint, repeated experience helps smooth out accidental outcomes. If an action works well only once but fails many times, the learner should not trust it much. If an action repeatedly leads to better states, confidence in that action should rise. This is why reinforcement learning often requires many episodes or attempts. The machine is not just collecting answers. It is building a more dependable estimate of what each choice is worth.
A common beginner mistake is assuming that learning means simply repeating the same action again and again. That is not enough. The important part is repeating the full cycle of action and feedback while comparing outcomes. The machine improves because it notices differences in results. In practical systems, this means logging rewards, tracking state-action outcomes, and checking whether performance is becoming more stable. Repetition without feedback is just looping. Repetition with feedback is learning.
One of the most important shifts in reinforcement learning is learning to think beyond the next reward. Some actions pay off instantly. Others create better opportunities later. A beginner often expects the machine to simply choose whatever gives the largest immediate reward, but that can lead to poor long-term behavior. Reinforcement learning is powerful because it can learn that a smaller reward now may lead to larger rewards later.
Imagine a robot vacuum choosing between two paths. One path has a small patch of dirt right away, which gives an immediate reward for cleaning. The other path leads to a larger dirty area a little farther away. If the robot only chases the closest visible reward, it may miss the better long-term option. A strong reinforcement learning system tries to estimate not just what happens now, but what each choice sets up next.
This is where practical judgment matters. Reward design must reflect the real goal. If you reward only quick gains, the agent may learn shallow behavior. If you include signals for progress toward future success, the agent has a chance to learn more strategic choices. Designers must think carefully about what behavior the reward actually encourages. Machines are literal. If a shortcut gives points, the agent may exploit that shortcut even if it is not what the designer intended.
In real applications, long-term reward thinking appears in recommendation systems, routing, robotics, and resource management. A choice that looks slower in the moment may reduce future penalties, improve safety, or open better future states. That is why reinforcement learning is not just about greedily collecting points. It is about judging sequences of actions. The more the learner understands delayed consequences, the more mature its decisions become.
The word policy can sound technical, but the idea is simple. A policy is the agent's current rule of behavior. In plain language, it is the machine's way of deciding what to do in each situation. If the agent is in state A, the policy might suggest action left. If it is in state B, the policy might suggest action forward. You can think of a policy as a learned playbook.
At the start of learning, the policy is usually weak because the agent does not yet know which actions are helpful. It may act randomly or follow rough guesses. As the system gathers experience, the policy improves. It begins to connect states with actions that tend to produce better rewards over time. The policy does not need to be perfect to be useful. It just needs to become more reliable than random choice.
In value-based learning, which you will continue to see in beginner examples, the agent often estimates how good different actions are in different states. Then the policy uses those estimates to pick actions. That means the policy is not magic. It is the visible decision layer built from learned experience. If one action has repeatedly led to good results, the policy will favor it more often.
A practical mistake is treating the policy as fixed too early. If the system stops adjusting before it has explored enough, it may lock into mediocre behavior. Good engineers allow room for learning while also guiding the system toward stability. The practical outcome is a policy that becomes more sensible over time: less random, more goal-directed, and better aligned with the rewards that actually matter.
Machines in reinforcement learning improve the same way many humans do in unfamiliar tasks: by making choices, seeing the consequences, and adjusting. The key phrase is through experience. The agent is not handed a complete map of the environment. Instead, it gradually builds useful expectations. In one state, action A might usually help. In another state, the same action might be a mistake. Experience helps the system learn these differences.
Suppose an agent controls a delivery robot in a hallway. Early on, it may choose the shortest path and get blocked by people. After repeated attempts, it may discover that a slightly longer route is more reliable and leads to faster deliveries overall. This is improvement based on evidence, not assumption. Each trip teaches something about how the environment behaves.
This is also where exploration and exploitation enter the story. Exploration means trying actions that are uncertain, just to gather information. Exploitation means using the best-known action so far. If the agent only exploits, it may miss better options. If it only explores, it may never settle on an effective strategy. Better choices come from balancing both. Early in learning, more exploration is often useful. Later, stronger exploitation helps turn knowledge into performance.
In practice, teams often monitor learning curves over time to judge whether experience is actually improving decisions. If rewards stay flat, something may be wrong with the reward design, the exploration rate, or the environment setup. Better choices are not guaranteed just because the algorithm is running. Improvement happens when feedback is informative and the learner has enough chances to compare outcomes and refine behavior.
A powerful but sometimes confusing idea in reinforcement learning is that a smart decision can look bad in the short term. This happens when an action causes a small immediate penalty but creates a better future. Beginners often judge actions too quickly by asking, "Did reward go up right away?" In many environments, that is the wrong question. A better question is, "Did this action move the agent toward better total outcomes over time?"
Imagine a game where stepping away from a nearby coin allows the player to reach a treasure chest later. The first move looks bad because it gives up an immediate reward. But if it leads to a much bigger future reward, it is actually the better choice. Reinforcement learning tries to capture this kind of delayed payoff. That is one reason trial and error must continue over many attempts. The system needs enough experience to see beyond first impressions.
Engineers must be careful here. If they evaluate learning too early, they may conclude that the agent is getting worse when it is actually discovering more strategic behavior. This is especially common when exploration increases short-term mistakes. A learner may temporarily choose unfamiliar actions and receive lower rewards, but those experiments can reveal better long-term paths. Stopping training too soon can trap the system in a comfortable but inferior policy.
The practical lesson is to judge behavior at the right time scale. Good reinforcement learning evaluation looks at trends across episodes, not isolated moments. Some of the best policies are built by surviving an awkward early phase in which sensible long-term behavior has not yet fully paid off. Patience, monitoring, and clear reward definitions are essential.
To really understand reinforcement learning, it helps to watch a simple example unfold over time. Picture an agent in a tiny maze with two possible routes to a goal. Route A is short but risky because it often leads to a penalty. Route B is longer but safer. On the first few attempts, the agent may try both randomly. Sometimes Route A wins quickly, which makes it look attractive. But after many episodes, the penalties on Route A begin to add up, and Route B starts to show a better average outcome.
This is a beginner-friendly example of value-based learning. The agent keeps rough estimates of how useful actions are in each state. After each attempt, it updates those estimates based on the reward it received and what happened next. Little by little, the estimated value of safer actions can rise above the estimated value of risky shortcuts. Then the policy shifts. The agent starts choosing the better route more often, not because someone manually programmed that route, but because repeated evidence changed its judgment.
When you observe learning across many attempts, you usually see a pattern: messy early behavior, gradual preference for stronger actions, and then more consistent performance. Improvement is rarely perfectly smooth. There may be setbacks, noisy results, or surprising spikes. That is normal. What matters is the direction of the trend. Are average rewards improving? Is the agent reaching goals more reliably? Is it making fewer costly mistakes?
In practical work, teams often graph episode rewards, success rates, or average steps to the goal. These measurements reveal whether the system is actually learning or just behaving randomly. The chapter's big message comes into focus here: machines improve through repetition because repetition produces evidence. That evidence shapes values, values shape policy, and policy shapes behavior. Over many attempts, trial and error turns into better decision-making.
1. According to the chapter, why does repetition matter so much in reinforcement learning?
2. What is a policy in this chapter's beginner-friendly explanation?
3. Which example best shows long-term reward thinking?
4. What mistake does the chapter say beginners often make about how learning looks over time?
5. What is the main goal of reinforcement learning as described in the chapter?
In reinforcement learning, an agent improves by acting, observing results, and adjusting future choices. That sounds simple, but one of the most important practical challenges appears almost immediately: should the agent keep doing what already seems to work, or should it try something new that might work even better? This chapter focuses on that decision. In everyday life, people face the same problem. If you always order the same meal, you know what you will get, but you may miss a better option. If you always try something new, you may discover great choices, but you may also waste time and accept many bad outcomes. Reinforcement learning turns this familiar human dilemma into a central engineering problem.
Exploration means trying actions that are not yet known well. Exploitation means choosing the action that currently looks best based on past experience. A strong learning system needs both. If it only explores, it never settles on a good strategy. If it only exploits, it may get stuck with a choice that seems good early on but is not actually the best. This chapter shows why trying new things is necessary, why always picking the familiar option can be risky, and how exploration and exploitation work together over time.
For complete beginners, it helps to remember that reinforcement learning is not magic and it is not guessing without purpose. The agent collects evidence. Rewards give feedback, but rewards can be noisy, delayed, or misleading in the short term. One action may give a small reward now but lead to better rewards later. Another may look good at first but block future improvement. Because of this, the agent must sometimes make decisions that look uncertain in the moment in order to become more capable overall.
From an engineering point of view, balancing exploration and exploitation is a design choice, not just a theory idea. You must decide how much risk is acceptable, how quickly the agent should commit to a policy, and whether mistakes are cheap or expensive in the environment. A recommendation system can afford to test a few different items. A medical treatment system must be far more careful. Good judgment means matching the learning strategy to the real-world cost of being wrong.
As you read the sections in this chapter, focus on the workflow: the agent tries actions, records rewards, compares options, and gradually changes its behavior. That repeated loop is where exploration and exploitation come alive. By the end of the chapter, you should be able to explain this trade-off in simple language, recognize common beginner mistakes, and compare a few basic decision strategies without needing heavy mathematics.
Practice note for Understand why trying new things is necessary: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Learn the risk of always picking the familiar option: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for See how exploration and exploitation work together: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Use simple examples to compare decision strategies: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand why trying new things is necessary: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Exploration is necessary because the agent begins with incomplete knowledge. At the start of learning, it does not know which action leads to the highest reward. Even if one option looks promising after a few tries, the agent still cannot be certain that another option is not better. Exploration is the process of gathering information. Without it, reinforcement learning would not really be learning; it would simply repeat early guesses.
Imagine a robot choosing between three hallways in search of a charging station. If it tries the first hallway and finds a small battery source, it might be tempted to keep returning there. But another hallway may contain a full charging dock. The robot will never discover that if it refuses to test alternatives. This is the basic reason exploration matters: the world contains hidden possibilities, and trial and error is how the agent uncovers them.
In practice, exploration helps the agent build a more accurate picture of action values. Early rewards can be misleading because they are based on small samples. A beginner mistake is to trust the first good result too much. One lucky outcome does not prove that an action is best. Engineers often design learning systems to include at least some deliberate testing of less-familiar actions so the agent does not form strong beliefs too early.
There is also a deeper reason exploration matters: environments can be more complex than they first appear. Some actions only become useful in certain states. An option that seems poor in one situation may be excellent in another. If the agent explores across different states, it learns not just what action is best in general, but what action is best here and now. That is what makes reinforcement learning adaptive instead of rigid.
So exploration is not random behavior for its own sake. It is structured curiosity with a purpose. The practical outcome is better long-term decision quality. By trying unfamiliar actions early and carefully, the agent avoids becoming trapped by limited experience and creates the knowledge needed for better choices later.
Exploitation means using what the agent has learned so far to choose the action that currently appears best. If exploration is about collecting information, exploitation is about benefiting from that information. In reinforcement learning, this usually means selecting the action with the highest estimated value in the current state. The agent is no longer asking, “What can I discover?” but rather, “Given what I know, what should I do now?”
This is important because learning systems are not built only to experiment. They are built to perform. If a delivery robot has learned the fastest safe route through a warehouse, it should usually use that route. If a game-playing agent has found a move that consistently leads to good results, exploitation lets it win more often. A system that explores forever without using its knowledge would be inefficient and frustrating.
However, exploitation is based on current estimates, not perfect truth. That is why it must be understood carefully. The agent exploits the best option it knows, which may or may not be the actual best option in the environment. This distinction matters. A beginner often assumes exploitation means the agent has finished learning. In reality, it means the agent is acting confidently based on present evidence.
From an engineering perspective, exploitation becomes more valuable when the cost of poor performance is high. Once enough evidence has been gathered, repeated exploration can reduce short-term rewards with little extra benefit. At that stage, exploiting a strong policy often produces better outcomes. Many systems begin with more exploration and gradually shift toward more exploitation as confidence grows.
The practical lesson is simple: exploitation is how reinforcement learning turns experience into useful action. It allows the agent to capitalize on patterns it has discovered. But wise exploitation depends on the quality of earlier exploration. If the agent learned from a narrow or biased set of experiences, its exploited choice may only be the best among the options it bothered to test.
The central tension in this chapter is the trade-off between safe choices and new choices. A safe choice is an action with known or expected reward. A new choice is less certain, but it may reveal better long-term opportunities. Reinforcement learning depends on balancing these two. Too much safety can block discovery. Too much novelty can destroy performance.
Consider a student using a study app that recommends practice activities. One activity has often helped the student answer questions correctly, so the app keeps suggesting it. That is safe. But another activity, rarely shown so far, might improve understanding much more if given a chance. If the app always chooses the familiar activity, it may settle for “good enough” and never reach “better.” This is the risk of always picking the familiar option: early success can create a comfort zone that hides stronger alternatives.
The trade-off is especially important because rewards can be short-term or long-term. A familiar action may give a small immediate reward, while a new action may lead to learning that improves many future decisions. This is why engineers do not judge choices only by what happens right now. Good reinforcement learning design asks whether a short-term loss might support larger future gains.
Balancing the trade-off requires judgment. In low-risk environments, more exploration is acceptable because mistakes are cheap. In high-risk environments, the system may need stronger guardrails, slower experimentation, or simulation before real-world use. This is not just a math decision. It is a practical decision about cost, safety, and confidence.
A useful mental model is that safe and new choices are teammates, not enemies. Safe choices protect performance. New choices expand understanding. The best systems combine them over time, shifting gradually as the agent learns more. Reinforcement learning works well when it is neither too timid to discover nor too reckless to benefit from discovery.
To understand decision strategies, it helps to compare a few simple patterns of behavior. First, imagine an agent that always chooses the action with the highest reward seen so far. This strategy feels sensible because it uses available evidence. But it has a major weakness: one early lucky result can dominate all future choices. If the agent gets one good reward from Action A, it may ignore Actions B and C forever, even if one of them is better on average.
Now imagine the opposite strategy: the agent chooses completely at random every time. This guarantees exploration, so the agent will eventually sample all options. But it performs poorly because it never commits to strong choices. It learns something, but it does not make good use of what it learns. This shows that exploration alone is not enough.
A more practical beginner strategy is to mostly choose the best-known action, while occasionally trying another one. This simple idea captures how exploration and exploitation work together. Most of the time, the agent gains reward from its current best option. Sometimes, it tests alternatives to avoid becoming overconfident. Even without heavy math, you can see why this is useful: it protects performance while still allowing discovery.
Another strategy is to explore more at the beginning and less later. Early on, the agent knows little, so trying many options makes sense. Later, once values become more reliable, the agent can exploit more often. This mirrors how people learn many skills. At first, they experiment broadly. As experience grows, they become more selective and efficient.
The engineering takeaway is that strategies should match the stage of learning. During early uncertainty, broader sampling helps. During later stability, stronger exploitation often helps. Simple strategies are valuable for beginners because they make the core logic visible: compare observed rewards, keep updating estimates, and never let early results completely stop learning.
Many beginners hear the word randomness and assume it means poor design. In reinforcement learning, controlled randomness can be extremely useful. Randomness gives the agent a way to escape habits formed from limited evidence. If the agent is always deterministic, it may repeatedly choose a decent action and never gather data about others. A small amount of randomness creates opportunities to learn something new.
Think of a music app learning what songs a listener might enjoy. If it always recommends the same style because the user liked it before, it becomes narrow. By occasionally recommending something different, the app may discover another style the user likes even more. The random suggestion is not pointless. It is an experiment with potential value.
In practical systems, randomness must be controlled, not unlimited. Too much random choice creates noise and frustrates users or lowers rewards. Too little random choice can freeze learning. The useful question is not “Should there be randomness?” but “How much randomness is appropriate at this stage and in this environment?” This is where engineering judgment matters.
Randomness also helps when the environment changes. An action that used to be best may stop being best if conditions shift. If the agent never re-tests alternatives, it may continue exploiting an outdated choice. Occasional exploration allows the system to notice change and adapt. This is especially important in real-world settings like pricing, recommendations, and traffic routing, where patterns may drift over time.
The practical outcome is that randomness, used carefully, supports improvement. It prevents overconfidence, helps detect better options, and allows adaptation when the world changes. In reinforcement learning, a little uncertainty in action selection can create much better certainty in long-term knowledge.
One common misunderstanding is thinking that exploration is the same as making bad decisions. That is not correct. Exploration may produce lower reward in the short term, but it can improve the agent’s understanding and raise future rewards. In reinforcement learning, a choice is not judged only by what happens immediately. Long-term learning matters.
Another misunderstanding is believing exploitation means the agent has found the true best action. Usually, exploitation only means the agent is picking the action that currently has the highest estimated value. Those estimates can still be wrong, especially if the agent has not explored enough. This is why systems that exploit too early often become stuck with second-best behavior.
Beginners also often assume more exploration is always better. That is not true either. If an agent keeps experimenting when evidence is already strong, it may waste reward and reduce reliability. The right balance depends on the problem, the cost of mistakes, and how quickly the environment changes. Reinforcement learning is not about maximizing exploration or exploitation alone. It is about choosing wisely between them.
A further mistake is ignoring the role of state. People sometimes talk as if one action is globally best everywhere. In reality, an action may be good in one state and poor in another. Exploration should help the agent learn these differences, not just rank actions in a single overall list.
The practical lesson of this chapter is that reinforcement learning improves through a disciplined balance of trying and using. Good systems keep learning without becoming reckless, and they exploit useful knowledge without becoming trapped by it. That balance is one of the clearest signs of intelligent decision-making.
1. What is the main trade-off this chapter describes in reinforcement learning?
2. Why can always exploiting the familiar option be risky?
3. According to the chapter, what does exploration mean?
4. Why might an agent choose an action that seems uncertain in the moment?
5. How should exploration and exploitation be chosen in real-world systems?
In earlier chapters, reinforcement learning was introduced as a system of trial and error: an agent takes actions in an environment, receives rewards, and slowly learns what tends to work. In this chapter, we move one step deeper. Instead of looking only at single rewards, we now look at value. Value is a simple but powerful idea. It asks not just, “Did this action give a reward right now?” but also, “Does this action put the agent in a better position for future rewards?” That small shift is what makes reinforcement learning useful for more realistic decision-making.
Think about everyday choices. If you study tonight, the immediate reward may be low because it takes effort. But the long-term value may be high because it improves your exam result later. Reinforcement learning systems face this kind of trade-off all the time. A machine must often choose between a move that feels good now and a move that creates better outcomes over many steps. Value helps the machine compare those options in a structured way.
Another important idea in this chapter is strategy. In reinforcement learning, a strategy is often called a policy. A policy is simply a rule for choosing actions in different situations. Good policies do not appear instantly. They improve over time as the agent gathers experience and updates its estimates of value. This chapter connects those pieces together: value estimates, smarter action choices, and gradual strategy improvement.
For beginners, the key point is this: reinforcement learning does not need heavy math to be understood at a basic level. A machine can keep simple records of which actions have worked, which states seem promising, and which repeated patterns lead to better outcomes. Those records are then used to choose more wisely next time. Engineers build practical systems by deciding what to measure, how often to update value estimates, and how much exploration to allow before settling into stronger habits.
As you read, notice how the same pattern appears again and again. The agent observes a state, picks an action, receives a reward, and updates its view of what is valuable. Over many rounds, those updates shape a policy. The result is not magic. It is careful improvement through repeated feedback.
By the end of this chapter, you should be able to read a simple decision table, understand what a value-based method is trying to learn, and explain how better estimates can lead to better decisions. The goal is not mathematical detail. The goal is a clear mental model you can use when reading beginner RL examples or discussing how an intelligent system improves through experience.
Practice note for Learn the idea of value in simple terms: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for See how machines estimate which choices pay off: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand how strategies improve over time: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Connect values to smarter action choices: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
In reinforcement learning, value means the expected usefulness of something over time. That “something” might be a state, such as being in a safe location, or a state-action pair, such as choosing to move left while standing at a crossroads. The important point is that value is not the same as reward. A reward is the immediate signal the agent receives after an action. Value is the broader estimate of how good the current situation or choice is when future rewards are taken into account.
This is easier to understand with an everyday example. Imagine a robot vacuum deciding whether to go under the couch. It may get no reward immediately for entering that area, and it may even slow down. But if that path leads to a dusty region it can clean later, the action may still have high value. In other words, the best actions are not always the ones with the largest instant payoff. They are often the ones that create better future opportunities.
For beginners, value is best thought of as a practical score. The score answers a simple question: “How promising is this choice if I care about what happens next, not just right now?” Reinforcement learning systems estimate these scores from experience. They do not know the true value at the beginning. They start with guesses, then improve those guesses by trying actions and seeing what follows.
Engineering judgment matters here. If rewards are delayed too much, value is harder to estimate because the agent must connect present actions to future results. If rewards are badly designed, the learned values may point in the wrong direction. A common mistake is to assume the reward itself tells the whole story. In practice, value is needed precisely because many useful actions only show their benefit after several steps.
When you hear that a reinforcement learning method is “value-based,” it means the system is trying to learn these usefulness estimates and use them to make better decisions. Value is the bridge between raw experience and smarter behavior.
How does a machine estimate whether an action is worth taking? At a simple level, it keeps track of what tends to happen after that action in a given situation. If pressing a button in state A often leads to good future rewards, the estimated worth of that action rises. If it usually leads to poor results, the estimate falls. Over time, repeated experience turns rough guesses into more useful action scores.
Suppose an agent is choosing between two hallways in a maze. One hallway sometimes gives a small reward quickly but often ends in a dead end. The other hallway gives nothing at first but frequently leads to a large reward later. If the agent only counted immediate rewards, it might prefer the first hallway. But by estimating action worth over multiple steps, it can learn that the second hallway is often better overall.
This process depends on feedback. After the agent acts, it sees the result and updates its estimate. That update does not need to be perfect. In beginner examples, the idea is simply that estimates should move toward what experience suggests. If reality turns out better than expected, the action estimate increases. If reality turns out worse, it decreases. Many reinforcement learning algorithms differ mainly in how they perform this update.
There are practical challenges. Early estimates can be noisy because the agent has little data. Rare events can make an action look better or worse than it really is. Exploration also affects estimation. If the agent never tries an unfamiliar action, it cannot learn whether that action might actually be valuable. This is why exploration and exploitation remain connected to value learning. Strong estimates require enough experience, but enough experience often requires trying actions that are not currently believed to be best.
A common beginner mistake is to think the machine “knows” the correct action score after one or two attempts. In real systems, action values are learned gradually. Engineers often smooth updates and collect many examples to avoid overreacting to luck. Good action estimates are not just about recording rewards. They are about building a stable picture of which choices reliably pay off.
Rewards are the raw signals of reinforcement learning, but strategy is what turns those signals into better behavior. A strategy, or policy, tells the agent what action to choose in each state. At first, the strategy may be nearly random because the agent does not know much. As value estimates improve, the strategy also improves because the agent starts favoring actions that seem more useful.
Think of a delivery robot learning to move through a warehouse. Early on, it may bump into congestion, take long routes, or wait in bad places. Each trip produces rewards or penalties based on speed, safety, and success. On their own, these rewards are just isolated outcomes. But once the robot begins estimating the value of different actions in different places, it can form a stronger strategy: avoid crowded aisles, use open lanes, and approach the loading station from directions that reduce delays.
This is the important connection: rewards teach values, and values shape policy. The policy is not written all at once. It is adjusted step by step. If turning right in a particular state consistently leads to higher value than turning left, the strategy should increasingly prefer right. Over many updates, the policy becomes less random and more purposeful.
Good engineering requires caution. If a strategy becomes too greedy too soon, the agent may stop exploring and miss better options. If it stays too random for too long, learning can be slow and unstable. Another common mistake is reward design that accidentally teaches the wrong strategy. For example, if a robot gets rewarded only for speed, it may take unsafe shortcuts. Better strategy comes not just from learning values, but from making sure the rewards reflect the real goal.
In practical systems, better outcomes come from this loop: collect rewards, update values, improve policy, repeat. That loop is the heart of reinforcement learning. Strategy is simply learned decision-making guided by experience.
Value-based learning is a family of reinforcement learning approaches where the main job is to estimate how good states or actions are. Instead of directly memorizing one perfect move for every situation, the system learns value scores and then chooses actions using those scores. This is a very beginner-friendly way to think about RL because it reduces decision-making to a practical question: “Which option currently looks best according to my estimates?”
One common version focuses on action values. In each state, the agent has a small list of possible actions and an estimated score for each one. If the score for action A is higher than the score for action B, the agent usually prefers A. Over time, those numbers are updated using experience. Good outcomes push estimates up. Bad outcomes pull them down. This is the basic pattern behind many simple RL demonstrations.
Value-based learning works well for teaching because it shows clearly how trial and error becomes knowledge. The agent does not need a human to label the best move in advance. It discovers useful patterns by interacting with the environment. For example, in a game, moving toward a key may have low immediate reward but high value because it enables a later win. A value-based learner can gradually capture that relationship.
Still, it is important to keep expectations realistic. Value estimates are only as good as the experience gathered. Sparse rewards, changing environments, or too many possible states can make learning harder. Another practical issue is that estimated values may be wrong for a while, especially early in training. Engineers therefore use repeated episodes, careful reward signals, and exploration rules to help the values become meaningful.
For a complete beginner, the main takeaway is simple: value-based learning does not try to solve everything at once. It builds a useful map of what seems promising, then acts according to that map. As the map improves, so do the agent’s decisions.
Policy improvement in reinforcement learning is usually gradual, not sudden. The agent starts with a weak or incomplete policy, gathers experience, updates values, and then makes the policy slightly better. This repeated cycle is important because most useful behaviors are learned through many small corrections rather than one big insight.
Imagine a beginner learning to ride a bicycle. On the first attempt, the policy is poor: steering is uncertain, balance is unstable, and braking is clumsy. But each attempt provides feedback. Some actions improve balance; some cause wobbling. Over time, the learner favors the better actions. Reinforcement learning follows the same pattern. A machine improves by discovering which decisions lead to stronger long-term outcomes.
A practical workflow often looks like this:
This step-by-step improvement is where engineering judgment matters most. Updates that are too aggressive can make the policy unstable, swinging wildly after a few unusual outcomes. Updates that are too slow can make learning painfully inefficient. A common mistake is to confuse temporary success with a truly good policy. Just because an action worked once does not mean it is best on average.
Another mistake is to improve the policy without enough exploration. That can trap the system in a habit that is merely acceptable, not truly strong. Good reinforcement learning practice allows a policy to become more confident over time while still checking whether better paths remain undiscovered. In short, policy improvement is the disciplined process of turning value estimates into better choices, one update at a time.
A simple decision table is one of the easiest ways to understand value-based reinforcement learning without heavy math. The table lists states, possible actions, and estimated values. You can think of it as a cheat sheet the agent builds from experience. When the agent enters a state, it checks the row for that state, compares the values of available actions, and usually picks the action with the highest estimate.
For example, imagine a tiny grid world with a robot in different positions. In one state, the table might say:
These numbers are not guaranteed truth. They are current estimates of long-term usefulness. A higher number suggests a better future is likely if that action is chosen. In this example, the robot would usually choose Right because 2.8 is the highest estimate. If later experience shows that moving Right often leads to a trap, that value would drop. The table changes as learning continues.
Reading such a table teaches several practical lessons. First, values compare actions relative to a state. An action that is good in one state may be bad in another. Second, the largest immediate reward is not always linked to the largest value. Third, tables make it easy to see why a strategy improves: the policy simply starts favoring the strongest estimated entries more often.
There are also limits. Decision tables work best when the number of states and actions is small. In larger real-world tasks, tables can become too big, and more advanced methods are needed. But for beginners, these tables are excellent because they make reinforcement learning visible. You can literally watch the machine’s preferences change. That makes the connection between values, strategies, and better outcomes much easier to understand.
1. In this chapter, what does "value" help an agent consider beyond an immediate reward?
2. What is a policy in reinforcement learning?
3. Why might an agent choose an action with low immediate reward?
4. How do strategies improve over time according to the chapter?
5. Which combination is described as important in practical reinforcement learning engineering?
By this point, you have met the main ideas of reinforcement learning one by one: an agent interacts with an environment, takes actions, observes states, and receives rewards. You have also seen that learning happens through trial and error, and that the goal is not just to collect a reward right now, but to make decisions that lead to better results over time. In this chapter, we will connect those ideas into one practical picture and look at where reinforcement learning appears in the real world.
A helpful way to think about reinforcement learning is to imagine a learner that does not begin with a perfect instruction manual. Instead, it starts with a goal and a way to try things. It acts, sees what happens, and gradually improves. This is why reinforcement learning feels natural in situations where a system must make a sequence of decisions. A single action may matter, but the bigger challenge is choosing many actions in a row while learning which patterns lead to success.
In real projects, reinforcement learning is not magic. Engineers must define the problem clearly, choose what information the agent can observe, decide what actions are available, and design a reward that truly matches the desired outcome. These choices are often more important than the learning algorithm itself. A beginner sometimes imagines that once an RL model is turned on, it will simply discover the best behavior. In practice, the quality of the setup strongly affects the quality of the result.
Another important real-world lesson is that reinforcement learning is powerful, but not always the best tool. Some tasks are easier to solve with rules, standard machine learning, optimization, or human planning. RL becomes most useful when a system must learn from interaction and improve decisions over time, especially when short-term and long-term outcomes can conflict. That is why ideas like exploration versus exploitation and immediate versus delayed reward matter so much.
As you read this final chapter, focus on the complete workflow: define the problem, represent the state, choose actions, measure reward, train safely, evaluate carefully, and improve the design. You do not need heavy math to understand the big picture. What matters is seeing how all the pieces fit together and developing good engineering judgment about when and how reinforcement learning should be used.
The goal of this chapter is confidence. If you can explain reinforcement learning in simple everyday language, identify the agent, environment, actions, states, and rewards in an example, and describe how trial and error improves decision-making over time, then you already have the right foundation. Now let us bring everything together in a more realistic and practical way.
Practice note for Bring all core ideas into one complete picture: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Explore beginner-friendly real-world applications: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Recognize limits and challenges of reinforcement learning: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Know what to study next with confidence: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Let us build one complete beginner-friendly picture. Imagine an agent learning to control the temperature in a small office. The environment is the office itself: current temperature, time of day, outside weather, whether people are present, and how the heating or cooling system responds. The state is the information the agent can observe, such as the current indoor temperature and whether the room is occupied. The actions might be increase cooling, decrease cooling, increase heating, decrease heating, or do nothing. The reward could be high when the room stays comfortable while using little energy, and lower when the room is uncomfortable or wastes power.
At the beginning, the agent does not know the best action for each situation. It tries actions and sees results. Sometimes it explores by testing a less certain action. Sometimes it exploits by choosing the action that currently seems best. This balance matters because too much exploration wastes time and may cause poor performance, while too much exploitation can trap the agent in a decent but not truly good strategy.
Now connect this to long-term thinking. Suppose turning on strong cooling gives quick comfort and an immediate reward, but it also causes the system to overshoot, making the room too cold later and using too much energy. A smarter policy may accept a smaller short-term reward in exchange for better comfort and efficiency over the next hour. This is exactly why reinforcement learning focuses on sequences of decisions, not isolated choices.
In practical engineering, the workflow usually looks like this: define the goal clearly, choose what the agent can observe, define the available actions, design the reward, train in a simulator or controlled setting, measure performance, and revise the setup. A common beginner mistake is to think poor learning always means the algorithm is weak. Often the real problem is that the state is missing important information, the action space is unrealistic, or the reward teaches the wrong lesson.
Good judgment means asking simple questions. Can the agent see enough to make a good decision? Are the actions safe and realistic? Does the reward actually represent what humans want? Can the system learn through trial and error without causing harm? When you can answer these questions, the whole reinforcement learning process becomes much easier to understand and explain.
Games are one of the clearest places to understand reinforcement learning because the rules are usually well defined. In a game, the agent observes the game state, chooses an action, and receives rewards through points, progress, or winning. The environment responds in predictable ways according to the game rules. This makes games an excellent training ground for RL ideas because success and failure are easier to measure than in messy real life.
Consider a simple racing game. The state might include the car's position, speed, nearby obstacles, and track direction. The actions are steering, accelerating, and braking. The reward could increase for staying on the track and finishing quickly, and decrease for crashing. Over many attempts, the agent learns that a short-term gain such as speeding into a sharp turn may lead to a larger long-term penalty. This makes the difference between immediate reward and long-term reward very concrete.
Robotics uses the same core ideas, but with more engineering challenges. A robot arm picking up objects is an agent interacting with a physical environment. Its state may include camera input, joint angles, object location, and grip pressure. Its actions are motor commands. The reward may be higher when it grasps an object correctly and lower when it drops or crushes it. Trial and error still drives learning, but now mistakes can be slow, expensive, or unsafe.
This is why real robotics teams often train in simulation first. A simulator lets the agent practice many times without damaging hardware. After that, engineers try to transfer the learned behavior into the real robot. Even then, they must test carefully because the real world contains noise, delays, friction, sensor errors, and unexpected situations that simulation may not capture perfectly.
The practical outcome is that games show why RL can learn strong strategies, while robotics shows why engineering discipline matters. In both areas, the same framework appears: define states, actions, and rewards; balance exploration and exploitation; evaluate long-term performance; and improve the system step by step. The ideas stay the same even when the application becomes more advanced.
Not all reinforcement learning problems look like a robot or a game. Some involve smart decision systems that interact with people over time. A recommendation system is a beginner-friendly example. Imagine an online learning app suggesting lessons to a user. The agent is the recommendation system. The environment includes the user and the app context. The state might contain what the user has already studied, how long they stay on each lesson, which topics they skip, and what time of day they learn best. The actions are the possible recommendations. The reward may come from useful engagement, lesson completion, or long-term learning success.
This kind of problem is interesting because the best choice is not always the one that gets the quickest click. A flashy recommendation may produce an immediate reward if the user opens it, but a more relevant lesson may lead to better long-term satisfaction and stronger learning progress. This mirrors a major RL idea: short-term success can conflict with long-term value.
Exploration and exploitation are also very visible here. If the system always recommends what worked before, it may never discover better options for a user whose interests are changing. But if it explores too aggressively, it may annoy users with poor suggestions. In practice, teams must control exploration carefully and often apply RL only to parts of the system where experimentation is acceptable.
Recommendation and decision systems also show that reward design is delicate. If the only reward is clicks, the system may learn to chase attention rather than usefulness. If the reward includes retention, satisfaction, and quality signals, the behavior may improve. This is a practical example of why engineers must think beyond the simplest metric.
Other smart decision settings include ad placement, traffic signal timing, inventory choices, and personalized notifications. In each case, the core structure remains familiar: an agent observes a state, chooses an action, receives feedback, and updates future decisions. Understanding this repeating pattern helps beginners recognize reinforcement learning in many everyday technologies.
One of the biggest surprises for beginners is that reinforcement learning can be slow and frustrating. The reason is simple: the agent often learns by trying many actions and observing delayed results. In some tasks, rewards are rare, noisy, or arrive only after a long sequence of steps. If the agent gets useful feedback only once in a while, learning what caused success becomes difficult.
Another challenge is that the agent changes its behavior while learning. This means the data it collects is always shifting. In standard supervised learning, you often train on a fixed dataset. In RL, the agent's choices affect what experiences it sees next. This makes training less stable and sometimes harder to debug.
Bad problem design is another common source of difficulty. If the state leaves out crucial information, the agent may never learn a good policy because it cannot tell important situations apart. If the action space is too large or unrealistic, the agent may spend huge amounts of time trying unhelpful behaviors. If the reward is too sparse or confusing, learning may stall completely.
Engineers respond with practical methods. They simplify the environment, shape the reward carefully, use simulation, add safety limits, and evaluate against clear baseline methods. They also monitor not just final scores, but learning curves, failure cases, and whether the agent behaves sensibly in edge cases. A useful habit is to test the simplest possible version first before building a more advanced system.
A common mistake is assuming more training will always fix a weak result. Sometimes the issue is structural rather than computational. If the reward is wrong, more training just teaches the wrong behavior more strongly. If exploration is poor, more time may simply repeat the same mistakes. This is why reinforcement learning requires patience and diagnosis, not just compute power. Slow training is often a sign to rethink the setup, not merely to wait longer.
When reinforcement learning moves into the real world, ethics and safety become central. The core reason is that an agent learns from rewards, and the reward may not perfectly capture what people truly want. If the reward is poorly designed, the agent can find shortcuts that technically maximize the score while creating harmful or undesirable outcomes. This is sometimes called reward hacking, and it is one of the most important practical risks in RL.
Imagine a warehouse robot rewarded only for moving items quickly. It may learn to move too fast, increasing breakage or creating safety risks for nearby workers. A recommendation system rewarded only for time spent may push addictive or low-quality content. A traffic system rewarded only for one intersection's speed may shift congestion into surrounding streets. In each case, the reward is incomplete.
Good engineering judgment means designing rewards that reflect the broader objective and adding constraints where necessary. Safety may require limiting which actions are allowed, testing in simulation, monitoring for unusual behavior, and involving humans in review. In high-stakes settings such as healthcare, finance, or transportation, reinforcement learning should not be treated like an unsupervised experiment on real people.
Ethics also includes fairness, transparency, and accountability. If an RL system personalizes decisions for different users, developers should ask whether the system treats groups fairly and whether the objective encourages healthy outcomes. The question is not only "Can the agent learn?" but also "Should it learn this way, with this reward, in this environment?"
For beginners, the key lesson is simple: rewards are powerful but dangerous if defined carelessly. A successful RL project is not only one that reaches a high number on a chart. It is one that behaves safely, matches human goals, and performs reliably in the situations that matter. Real-world success requires responsible design from the start.
You now have the beginner foundation needed to talk about reinforcement learning clearly and confidently. You can describe an agent, environment, state, action, and reward in plain language. You understand that learning happens through trial and error, that future rewards matter, and that exploration must be balanced with exploitation. That is a strong starting point.
The best next step is to deepen your understanding through small examples. Try to describe everyday situations in reinforcement learning terms: a robot vacuum finding an efficient path, a game character learning to avoid obstacles, or a smart thermostat adjusting to comfort and energy use. This habit trains you to see RL as a decision-making framework rather than a mysterious algorithm.
After that, study simple value-based learning examples more closely. You do not need heavy math at first. Focus on the idea that the system estimates how good an action is in a state, then updates that estimate based on experience. This will prepare you to later explore methods such as Q-learning with more confidence.
A practical study path might look like this:
Most importantly, keep your expectations realistic. Reinforcement learning is exciting, but it is also one of the more challenging areas of AI to apply well. Progress comes from combining conceptual clarity with practical thinking. If you continue with curiosity and patience, you will be well prepared for the next stage of study.
1. According to the chapter, what makes reinforcement learning especially useful in real-world problems?
2. Which part of an RL project does the chapter say is often more important than the learning algorithm itself?
3. Why does the chapter say reinforcement learning is not magic?
4. What is a key reason ideas like exploration vs. exploitation and immediate vs. delayed reward matter?
5. What does the chapter identify as a sign that a beginner has the right foundation in reinforcement learning?
- Learning Evolved.
- Intelligence Amplified.


