AI Engineering & MLOps — Beginner
Monitor quality, uptime, and cost so your AI app stays trustworthy.
AI features can feel magical when they work and frustrating when they don’t. A chatbot may answer incorrectly, slow down at peak times, or quietly run up a bill. Monitoring is how you catch these problems early, understand what happened, and prevent the same issue from returning. This course is a short, book-style guide built for absolute beginners—no coding, AI, or data background required.
You’ll learn monitoring from first principles, using plain language and practical examples. Instead of starting with complex tools, you’ll start with the questions that matter: Is the AI feature available? Is it fast enough? Are answers still good? Is cost under control? By the end, you’ll know what to measure, what to record, and what to do when something goes wrong.
Throughout the six chapters, you’ll create a simple monitoring plan you can apply to almost any AI app—customer support chat, document summarization, internal search, or an AI assistant. You will define clear goals, pick a small set of signals to track, and design a lightweight dashboard and alerting approach that helps you act quickly.
Chapter 1 explains what AI monitoring is and why AI apps fail in real-life use. You’ll learn the main types of signals (logs, metrics, traces) in simple terms and set your first monitoring goal.
Chapter 2 turns that goal into measurable targets. You’ll learn beginner-friendly reliability metrics like uptime, error rate, and latency, and you’ll practice choosing what should trigger an alert versus what should simply be watched.
Chapter 3 focuses on logging—how to record the minimum useful information to troubleshoot issues while protecting privacy. You’ll learn how to connect events using request IDs and how to keep logs manageable.
Chapter 4 tackles output quality. You’ll learn how quality problems differ from outages, how to collect user feedback, and how to set up basic checks and a small test set to catch regressions after changes.
Chapter 5 makes cost visible and controllable. You’ll learn what drives AI cost (tokens, time, retries), how to track spend per request and per feature, and how to add guardrails like caching, limits, and fallbacks.
Chapter 6 brings everything together with alerts, incident response, and continuous improvement. You’ll learn how to write actionable alerts, triage problems quickly, and run simple reviews that prevent repeat incidents.
This course is for anyone who needs an AI feature to be dependable—students, product managers, founders, analysts, support leaders, and new engineers. If you’ve ever asked “Why did the AI get worse?” or “Why did our bill spike?” this course gives you a clear, practical starting point.
If you’re ready to keep your AI app reliable and low cost with a beginner-friendly approach, join now. Register free to get started, or browse all courses to compare learning paths.
Machine Learning Engineer, AI Reliability & Monitoring
Sofia Chen is a machine learning engineer who helps teams ship AI features that stay stable in production. She specializes in monitoring, incident response, and cost control for LLM and ML-powered apps. She has built practical dashboards and alerting systems for customer-facing products used at scale.
AI monitoring is the practical discipline of keeping an AI feature dependable after you ship it. It answers simple, high-stakes questions: Is the feature working right now? Is it fast enough for users? Are the answers still good? Is it costing more than you planned? Unlike a demo, a real AI app runs all day, for many users, across changing inputs, model updates, and upstream outages. Monitoring is how you notice trouble early, diagnose it quickly, and learn what to improve.
In this course, “AI app” usually means a product workflow that sends a request to an AI model (often an LLM) and returns an output to a user—possibly with tools, retrieval, or multiple calls in the middle. Beginners often focus on prompt quality and forget that reliability is a system property. Monitoring is the set of lightweight practices—logs, metrics, traces, feedback, and alerts—that turns an AI feature into a dependable service.
This chapter starts with the most common ways AI apps break, in categories you can recognize without advanced MLOps tools. Then you’ll learn the three core signals (logs, metrics, traces) in plain language, and how to separate reliability problems from quality and cost problems. You’ll finish by writing your first one-sentence monitoring goal for a simple AI feature and mapping who needs which information: users, support, engineers, and leaders.
Practice note for Milestone: Spot the most common ways AI apps break: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Learn the three core signals (logs, metrics, traces) in plain language: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Identify reliability vs quality vs cost problems: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Create your first monitoring goal for a simple AI feature: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Map who needs what (users, support, engineers, leaders): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Spot the most common ways AI apps break: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Learn the three core signals (logs, metrics, traces) in plain language: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Identify reliability vs quality vs cost problems: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Create your first monitoring goal for a simple AI feature: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
In production, an AI feature is not “a model.” It’s a pipeline: a user action becomes a request, the system enriches that request (context, user profile, retrieved documents), calls one or more models, applies guardrails and formatting, and returns an answer. Even a “simple” chatbot involves multiple moving parts: network calls, authentication, rate limits, timeouts, and sometimes a database lookup or retrieval step. Monitoring starts by treating this as a service with inputs and outputs, not as a prompt.
Think in terms of an AI request and an AI response. A request has metadata (user, feature, environment), content (the prompt), and configuration (model, temperature, max tokens). A response has content (the text), structure (JSON, citations), and side effects (tool calls, saved notes). Monitoring becomes easier when you standardize what “one request” means in your code. For example: “One summarization request equals one user document plus one model call, returning a 3-bullet summary.”
To make monitoring practical, add a unique request_id at the boundary of your AI feature and carry it through every step. This single habit enables you to connect user complaints (“it was slow”) to system evidence (which step was slow, which model call retried, which document triggered it). Beginners often skip this and end up with scattered logs that can’t be tied together. You don’t need heavy tooling—just consistent identifiers and a clear definition of the unit you’re monitoring.
Most AI incidents fall into four buckets that anyone can spot: wrong, slow, down, or expensive. This milestone—spotting common breakages—matters because it helps you choose the right signals. If users say “it’s wrong,” you need quality evidence. If they say “it’s slow,” you need latency breakdowns. If it’s “down,” you need error rates and availability. If it’s “expensive,” you need cost and token accounting.
Wrong can mean hallucinations, missing key facts, unsafe content, formatting failures (invalid JSON), or incorrect tool usage. A frequent beginner mistake is to treat every wrong answer as a prompt problem. In practice, wrong answers often come from missing context (retrieval returned irrelevant docs), silent truncation (max tokens too low), or a changed upstream schema (tool output changed).
Slow usually comes from network latency, model queueing, retries after timeouts, large prompts (too many tokens), or multi-step agent loops. Users experience this as “spinning,” not as a measurable number—so you need to measure it for them.
Down includes hard failures (500s), rate limits (429s), auth errors, and dependency outages (vector database, storage, feature flags). A subtle “down” is when your service returns a fallback message so the UI looks okay but the feature is effectively broken.
Expensive can appear suddenly after a prompt change, a new feature launch, or an accidental loop that calls the model multiple times. Token spikes, high retry counts, and cache misses are common drivers. Early monitoring should make these four categories visible so you can label incidents correctly and avoid guessing.
Monitoring is not “collecting data.” It’s a loop: detect a problem, understand the cause, fix it, and prevent it from recurring. Beginners often stop at detection (“we got an alert”) and then scramble manually. A good monitoring setup makes the next step—understanding—fast by preserving the right context.
Detect means you can quickly see when the AI feature violates expectations. This starts with simple reliability goals: uptime (is it available), speed (is it responsive), and accuracy/quality (are outputs acceptable). You don’t need perfect goals on day one, but you do need a baseline and a threshold that triggers attention.
Understand means you can answer: what changed, who is affected, and where in the pipeline it broke. This is where request_id, structured logs, and basic traces pay off. Common mistakes: logging only the final output (no prompt or config), not recording model name/version, and not capturing retries or timeouts.
Fix is the short-term action: roll back a prompt, reduce max tokens, add caching, adjust timeouts, or disable a tool call. Here, engineers need evidence, not anecdotes. Support needs a user-facing explanation and workaround.
Prevent is where monitoring becomes engineering judgment. You add a guardrail check (e.g., “must output valid JSON”), create an alert on token spikes, or add a canary rollout for prompt changes. You also write a basic incident playbook: what to check first, who to notify, and how to mitigate. Prevention is often small, cumulative improvements that turn unknown failures into known patterns.
To monitor effectively without heavy tooling, you need to understand three core signal types in plain language: logs, metrics, and traces. This milestone helps you pick the right signal for each question, instead of logging everything and still being blind.
Logs are detailed records of events. In AI apps, good logs are structured (JSON), tied to request_id, and include key fields: feature name, user segment (not raw PII), model, prompt version, token counts, retry count, and a small snippet or hash of input/output. Logs answer “what happened on this specific request?” They are essential for debugging wrong answers and investigating incidents.
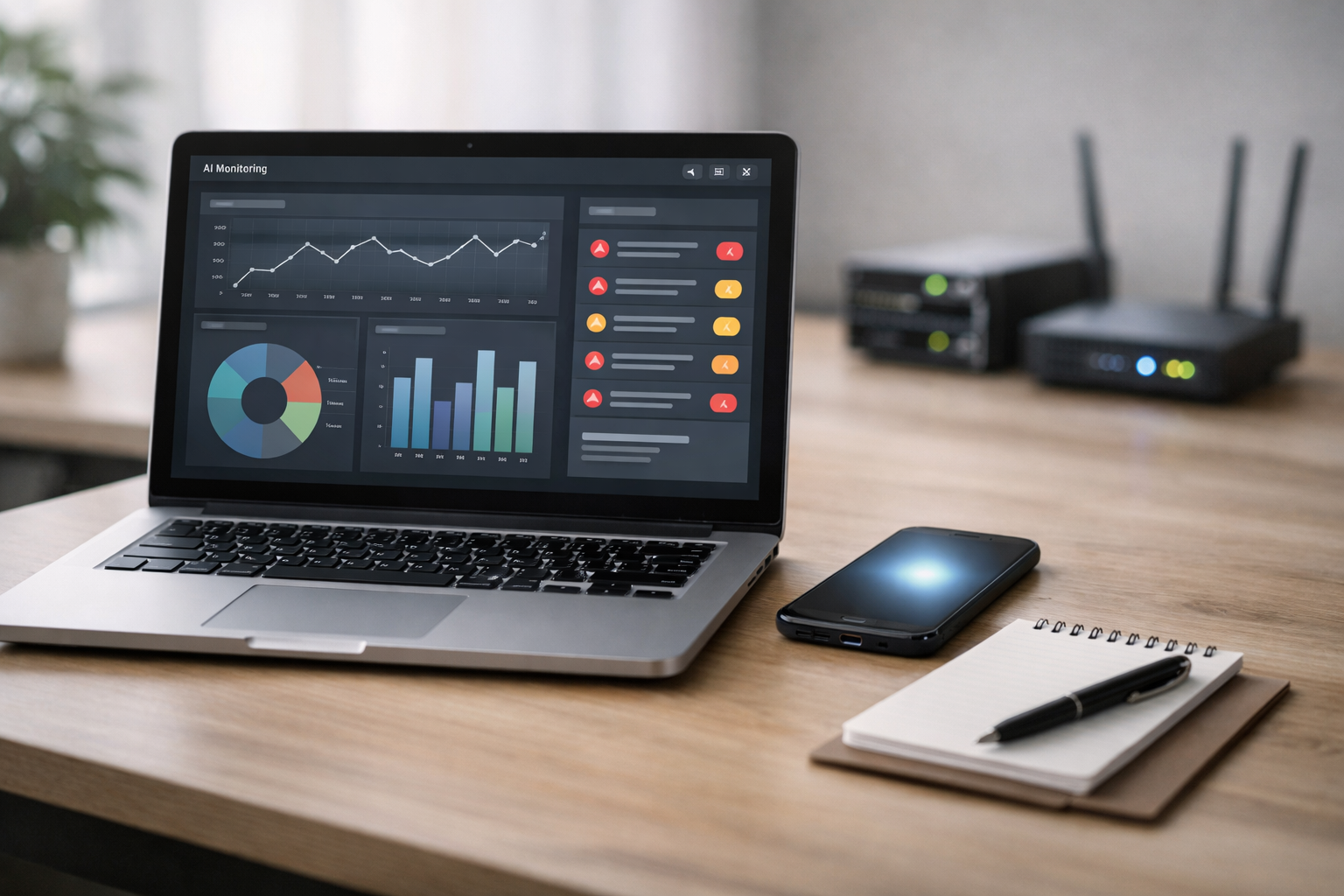
Metrics are numbers aggregated over time: counts, rates, and distributions. Examples: requests per minute, error rate, p95 latency, average tokens per request, cache hit rate, and cost per day. Metrics answer “is the system healthy overall?” and power alerts. A beginner-friendly approach is to start with a small dashboard: traffic, errors, latency, and cost.
Traces show the path of one request through multiple steps (spans). In an AI pipeline, a trace might include: retrieval, prompt assembly, model call #1, tool call, model call #2, post-processing. Traces answer “where did the time go?” and “which dependency failed?” If you can’t adopt full tracing yet, simulate it by logging timestamps for each step and computing durations.
Use all three together: metrics tell you there is a fire, traces show where the fire is, and logs tell you what fueled it. That combination is the foundation for reliable, low-cost AI apps.
To separate reliability vs quality vs cost problems, you need a shared vocabulary. Four terms come up constantly in monitoring conversations: latency, errors, outages, and drift. When stakeholders use these words differently, teams waste time debating symptoms instead of fixing causes.
Latency is the time from request start to response delivered. Track it as a distribution (p50, p95, p99), not just an average. In AI apps, latency often has “lumps”: retrieval time, model time, and post-processing time. High latency might be a reliability problem (timeouts) and a cost problem (retries, long outputs), not just a UX issue.
Errors are failed requests. Define what counts: HTTP 5xx, explicit model API errors, malformed outputs (e.g., invalid JSON), safety blocks, or “successful” responses that contain a fallback message. If you only count server exceptions, you will miss silent failures that users experience as wrong or useless answers.
Outages are periods when the feature is unavailable or effectively unusable. An outage can be total (no responses) or partial (one region, one model, one user segment). Beginners often forget partial outages, like rate limiting that affects only peak hours. Your monitoring should show impact: percent of requests failing and which users are affected.
Drift means the world changed: inputs, user behavior, or context distribution shifts so the model’s performance changes over time. In LLM apps, drift can show up as new slang, new product policies, new document formats, or prompt changes. You may not have a labeled dataset, so start with proxy checks: rising “user thumbs down,” more regenerations, more escalations to humans, or a spike in “I don’t know” responses. Drift is usually a quality problem, but it can cause cost issues too if users retry more often.
Your first monitoring goal should be small enough to implement in a day, but meaningful enough to protect users and budgets. Choose one AI feature with a clear boundary and a measurable outcome—like “support ticket summarization,” “product Q&A,” or “meeting notes draft.” Avoid starting with a broad “chatbot platform” goal; you’ll struggle to define success and won’t know what to alert on.
Then write a one-sentence goal that combines reliability, quality, and cost in beginner-friendly terms. A practical template is: “For <feature>, 99% of requests succeed in under <time>, and <quality check> passes, while average cost stays under <budget>.” Example: “For ticket summarization, 99% of requests return a summary in under 4 seconds, the output is valid JSON with 3 bullets, and average model cost stays under $0.01 per ticket.” This forces you to decide what you will measure.
Finally, map who needs what—this milestone prevents you from building dashboards nobody uses:
Common mistake: writing goals that aren’t actionable, like “make answers accurate.” Instead, define checks you can run and thresholds you can alert on. With a clear goal and the right audience mapping, monitoring becomes a practical habit: you’ll know what to collect, what to review, and how to respond when the real world pushes back.
1. What best describes AI monitoring in this chapter?
2. Why does a real AI app need monitoring more than a demo does?
3. Which set lists the three core monitoring signals emphasized in the chapter?
4. A team notices the AI feature’s responses are still correct, but users complain it feels slow. Which category of problem is this?
5. What is the main purpose of writing a one-sentence monitoring goal and mapping who needs what (users, support, engineers, leaders)?
Monitoring only works when you know what you’re trying to protect. “The bot feels slow” or “answers are getting worse” are valid human signals, but they’re not actionable until you translate them into measurable targets. This chapter is about building that translation layer—simple reliability goals that a beginner can implement without expensive tooling.
You’ll practice turning vague expectations into numbers, picking a small set of KPIs for an AI endpoint, and establishing a baseline so you can tell “normal” from “abnormal.” You’ll also sketch a dashboard layout on paper, because a clear mental model is often more valuable than a fancy charting system. Finally, you’ll decide what should page you (alerts) versus what you simply review (watch items). The goal is not perfection; it’s a practical, low-cost system that catches real failures early.
As you read, keep one concrete AI feature in mind—an email summarizer, customer support assistant, document extractor, or RAG search endpoint. You’ll define what “good” means for that feature, then attach lightweight signals to verify it stays good.
Practice note for Milestone: Turn a vague goal into measurable targets: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Choose 5 beginner KPIs for an AI endpoint: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Set a baseline and recognize normal vs abnormal: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Design a simple dashboard layout on paper: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Decide what to alert on vs what to just watch: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Turn a vague goal into measurable targets: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Choose 5 beginner KPIs for an AI endpoint: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Set a baseline and recognize normal vs abnormal: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Design a simple dashboard layout on paper: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Decide what to alert on vs what to just watch: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
The first milestone is turning a vague goal into measurable targets. Start by writing the “feeling” in plain language, then convert it into an observable outcome with a unit and a time window. For example: “Users trust the answer” becomes “in 90% of sessions, users do not hit ‘regenerate’ more than once” or “human review marks the answer acceptable in at least 4 out of 5 cases.” “It’s fast” becomes “p95 latency under 2.5 seconds during business hours.”
A useful template is: metric + threshold + scope + window. Scope answers “for which endpoint/users/regions?” Window answers “over what time period?” Reliability targets without a window are ambiguous: 99% uptime per month is very different from 99% per day. For beginners, a monthly window is easiest for uptime, and a rolling 1-hour window is easiest for latency and errors.
Common mistakes: choosing targets you can’t measure, choosing targets you can’t influence, or choosing targets that fight each other. Token-heavy prompts may improve quality but slow responses and increase cost. Your job is to pick a compromise that supports the product. Write down one primary objective (e.g., “help users resolve support tickets faster”) and accept that some metrics are guardrails, not goals.
By the end of this section, you should have 2–3 measurable targets written as sentences, not just numbers. This becomes the “contract” your monitoring will enforce.
The second milestone is choosing 5 beginner KPIs for an AI endpoint. Two of them should almost always be uptime (availability) and error rate. Availability answers: “Can users get a response at all?” Error rate answers: “How often do requests fail?” In AI apps, failures come from your app (bugs), your data layer (timeouts, missing documents), and the model provider (rate limits, transient errors).
Define uptime in terms of successful requests, not server health. A server can be “up” while returning 500s. A simple definition: Availability = 1 - (failed_requests / total_requests), where “failed” includes HTTP 5xx, explicit model errors, and requests exceeding a timeout (because users experience them as failures).
Error rate needs categories. If everything is just “error,” you’ll struggle to fix incidents quickly. Track at least:
Engineering judgement: be strict about what counts as success. A 200 response with an empty answer might be “success” from an HTTP perspective but still a user-visible failure. Consider adding a semantic success flag in your logs (e.g., output_nonempty=true, citations_present=true, json_valid=true). This keeps your reliability metrics aligned with real outcomes.
Common mistake: treating all errors equally in alerts. Some errors are noisy (e.g., occasional client timeouts on mobile networks). Start by alerting on sustained 5xx/provider error spikes and watch 4xx trends in dashboards.
Latency is the “felt” performance of your AI feature, and it’s often the first thing users complain about. Track it using percentiles, not averages. Averages hide pain: one slow request in ten can ruin trust even if the mean looks fine. For beginners, start with p50 (typical) and p95 (worst common case). The p95 is what you optimize for reliability.
Break latency into parts if you can, even with simple timestamps in logs. A basic request might include: request received → retrieval/query → prompt build → model call → post-processing → response sent. If p95 jumps, this breakdown tells you whether the issue is your database, your vector search, or the model provider.
Timeouts are a reliability decision, not just a technical setting. If your endpoint times out at 10 seconds, then any request beyond 10 seconds is effectively an error. Pick a timeout that matches user tolerance and product context. For chat, 5–15 seconds might be acceptable; for an autocomplete feature, it’s not. If you don’t set timeouts intentionally, you’ll get “hanging” requests that clog your servers and amplify incidents.
Common mistakes: retrying blindly (which increases latency and cost), or measuring only server time while ignoring the model call. A good starting policy is a single retry on known transient provider errors with exponential backoff, then fail fast with a clear message or a fallback model. Monitoring should show whether retries help (lower error rate) or harm (higher latency and cost).
AI features often fail under load in surprising ways: queues build up, rate limits trigger, and latency climbs until timeouts cascade. Monitoring load is how you avoid being surprised by a product launch, a new integration, or a Monday-morning spike.
Throughput is usually measured as requests per minute (RPM) or per second (RPS). For beginners, RPM is easier. Watch concurrency too if your stack makes it visible (number of in-flight requests). High concurrency with rising p95 latency suggests a queue somewhere—often the model provider or your own worker pool.
Load monitoring connects directly to cost control. More requests means more tokens. If you don’t track throughput alongside token usage, you won’t know whether a cost spike is “more users” (good) or “worse prompts / looping retries” (bad). A simple cost-related KPI that fits beginners is tokens per request (or approximate it via prompt/response character counts if you can’t measure tokens).
Engineering judgement: decide your overload behavior. When you’re saturated, do you reject quickly (429 with a helpful message), degrade gracefully (use a smaller model, fewer retrieved documents), or queue requests (slower but fewer outright errors)? Each choice has a monitoring implication. If you queue, you must monitor queue length and age. If you reject, you must monitor 429s and user impact. “Do nothing” usually means latency climbs until users abandon—harder to see and harder to recover from.
The third milestone is setting a baseline and recognizing normal vs abnormal. Before you set alerts, run the system long enough to learn its natural variability. Even simple AI endpoints have daily patterns: mornings busier than evenings, weekdays busier than weekends, and certain prompts triggering longer generations.
A baseline can be as simple as “the last 7 days” and a few reference numbers: typical p50/p95 latency, typical error rate, and typical request volume. Write them down. Your goal is not statistical perfection; it’s operational clarity. If p95 latency is normally 2.0–2.8 seconds, then 3.0 seconds isn’t an emergency, but 8.0 seconds probably is.
Now decide what to alert on versus what to just watch (the fifth milestone). Alerts should be reserved for conditions that require timely action and have a clear owner. Watching is for trends you review daily/weekly.
Common mistake: alerting on single-point spikes. Use “for N minutes” rules, and combine signals when possible (e.g., alert only if latency is high and error rate is rising). Also decide your incident playbook basics: where the runbook lives, who is on call (even if it’s “the developer who last changed it”), and the first three checks (recent deploy, provider status page, logs for top error).
The fourth milestone is designing a simple dashboard layout on paper. One screen is a forcing function: you must choose what matters. A beginner dashboard should answer, in under a minute: “Is it up? Is it fast? Is it getting worse? Is it costing more? Are users unhappy?”
Here is a practical one-screen blueprint you can sketch and then implement in any tool (even a spreadsheet plus logs):
This layout naturally integrates logs, metrics, and user feedback without heavy tooling: logs provide error categories and timing breakdowns; metrics provide aggregates like p95; feedback events provide a quality proxy. If you can only implement one thing this week, implement structured logs that include request ID, endpoint, latency, model name, tokens in/out (or size), status/error type, and a user-feedback field when available.
Finally, write down what “good” looks like on the dashboard—your targets from Section 2.1—so the team shares a definition of normal. When the inevitable incident happens, you’ll spend less time debating symptoms and more time executing fixes.
1. Why does monitoring often fail when goals are described as “the bot feels slow” or “answers are getting worse”?
2. What is the main purpose of establishing a baseline for an AI endpoint?
3. What is the chapter’s recommended approach to KPIs for a beginner monitoring setup?
4. Why does the chapter suggest sketching a dashboard layout on paper?
5. How should you decide what to alert on versus what to just watch?
Monitoring starts with visibility, and visibility starts with logging. Beginners often avoid logs because they sound messy (too much data), risky (privacy), or expensive (storage and tooling). In practice, you can keep logging small, safe, and useful by treating each log entry as a tiny, structured story of a single AI request. When something goes wrong in production—slow responses, weird answers, higher token bills—logs are the fastest way to understand what actually happened without guessing.
This chapter’s milestones are simple: know what to log for AI inputs, outputs, and context; create a safe logging plan; add request IDs so you can trace events end-to-end; store and search logs for troubleshooting; and create a “minimum useful log” template you can reuse across features. You do not need heavy observability platforms to begin. You need consistency, good judgement, and a few carefully chosen fields.
As you read, keep one principle in mind: logs are for debugging and learning. Metrics tell you “something is wrong,” but logs help you answer “what changed, for whom, and why.” Done well, logs also become your foundation for later quality checks, human review workflows, and cost controls—without having to retro-fit your app after incidents.
Practice note for Milestone: Know what to log for AI inputs, outputs, and context: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Create a safe logging plan that protects privacy: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Add request IDs to connect events end-to-end: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Store and search logs for troubleshooting: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Build a “minimum useful log” template you can reuse: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Know what to log for AI inputs, outputs, and context: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Create a safe logging plan that protects privacy: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Add request IDs to connect events end-to-end: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Store and search logs for troubleshooting: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
A log entry is a snapshot of one event in your system. For AI apps, your most important event is a single user request traveling through your app and returning an AI-generated result. Think of a log entry as a short story with a beginning (what the user asked), a middle (what your system decided to do), and an ending (what the model returned and how it performed).
Beginners commonly log either too little (“Error: failed”) or too much (entire prompts, full user profiles, raw documents). The goal is “minimum useful”: enough to reproduce or explain the behavior, but not so much that you leak sensitive data or drown in noise. The most useful logs are structured (JSON fields), not just free-form text. Structured logs let you filter, group, and search quickly when something breaks at 2 a.m.
For AI monitoring, a single request often produces multiple log events: a request received, a retrieval step, a model call, a post-processing step, and a response delivered. You can log each step separately, but keep a shared identifier so they link together (you will do this in Section 3.4). Your first milestone—knowing what to log for inputs, outputs, and context—starts here: you are telling the story of the request in a way a future you can understand.
Practical outcome: you can open your logs and answer basic questions like “Which requests are slow?”, “What model version was used?”, and “Did retrieval return anything?” without re-running production traffic.
When an AI output looks wrong, you need to know what the model actually saw and how it was configured. That does not always mean logging the full raw prompt. It means capturing the reproducible parts: model name, parameters, prompt template version, and the key pieces of context that influence the answer.
At minimum, log the model identifier (e.g., provider + model), your application version (git SHA or build version), and the prompt template version. Prompt templates evolve quickly; if you do not version them, you will struggle to explain why the same user question produced different answers over time.
Next, log the settings that materially change behavior and cost:
For prompts and context, use a layered approach. Log a prompt template ID and rendered prompt hash by default. Then optionally log a redacted preview (first N characters) in non-production environments, or behind a “safe logging” gate. For retrieved documents, log document IDs, scores, and snippet hashes rather than full content. This gives you a reliable breadcrumb trail without copying large or sensitive text into logs.
Practical outcome: you can recreate the exact configuration of a model call later, compare behavior across versions, and identify regressions caused by prompt edits, retrieval changes, or model upgrades.
Logging without fear requires a privacy-first plan. AI apps often touch the most sensitive data: user messages, uploaded files, customer records, and internal documents. If you log raw inputs by default, you can accidentally store passwords, API keys, addresses, medical info, or confidential business content. The safest log is the one that never collected sensitive data in the first place.
Start with a written “safe logging plan” that answers three questions: (1) What fields are allowed in logs? (2) What fields are forbidden? (3) Who can access logs and for how long? Even in a small team, this prevents accidental creep where one developer adds a debug print and it becomes permanent.
Use concrete techniques to protect privacy and secrets:
A common mistake is relying on “we’ll be careful” instead of building guardrails. Another is logging tool-call arguments or retrieved text verbatim; those often contain the most sensitive payloads. Treat “logging” like “data storage”: apply least privilege, retention limits, and access controls.
Practical outcome: you can troubleshoot effectively while reducing breach risk and keeping compliance conversations simple: your logs contain operational signals, not user content.
AI requests are multi-step. Without correlation, logs become a pile of disconnected lines. Correlation means you can start from a user report (“the answer was wrong”) and trace everything that happened across your web server, retrieval service, model provider call, and post-processing.
The simplest technique is a request ID. Generate a unique ID at the edge (first service receiving the request). Include it in every log line and propagate it to downstream services via headers (e.g., X-Request-ID). If you make external model calls, include the request ID in your own logs around those calls, and store the provider’s response ID too (if available) for support cases.
Timestamps matter just as much. Use a consistent format (ISO 8601 in UTC) and log durations in milliseconds. Capture both start time and latency per step when possible. For AI apps, a single slow step—like retrieval, a retry loop, or a large output—often dominates total latency and cost.
Recommended correlation fields:
Common mistake: generating new IDs in each service. That defeats end-to-end tracing. Another mistake: logging only “total time,” which hides where the time went. With request IDs and consistent timestamps, you can reconstruct the full timeline of a single request and connect user feedback to the exact run that produced it.
“Log everything” is expensive and noisy, especially for AI apps where prompts and outputs can be large. Manageability is part of reliability: when an incident happens, you need to find the right events quickly, and you need your logging bill to stay predictable. The trick is to be selective by design.
Use sampling. Log 100% of errors and policy violations, but only a small percentage of successful requests. For example: 100% of failed model calls, 100% of requests over a latency threshold, and 1–5% of normal successes. Sampling works best with structured fields so you can still compute distributions from metrics, while logs give you examples to inspect.
Use tiered verbosity. Keep a default “minimum useful log” for every request (IDs, timings, model, token counts). Store deeper debug details only when you explicitly enable it, for a limited time window, or for a limited set of request IDs. This is safer and cheaper than permanent verbose logging.
Set retention with purpose. A common beginner mistake is keeping logs forever “just in case.” Instead:
Practical outcome: you can store and search logs for troubleshooting without runaway costs. Your storage stays small, your searches are fast, and you still retain the “interesting” requests that reveal real failures.
Logs earn their keep when you can reproduce a bad answer. Reproduction does not always mean re-running the exact user content; it means reconstructing enough context to understand the failure mode and verify the fix. With the fields from earlier sections, you can take a user complaint and turn it into an engineering workflow.
Start from the symptom: “The assistant gave incorrect billing guidance.” Find the request by time window, user session, or feedback event. Then follow the request ID through the steps. Look for obvious causes: wrong model, changed prompt template, retrieval returned zero documents, tool call failed, output was truncated, or retries occurred.
A practical troubleshooting checklist using logs:
When you identify a likely root cause, create a “replay packet”: prompt template version, model/settings, retrieval doc IDs, and the final output. Store it in your bug tracker, not in raw logs, and redact content. Then validate the fix by running the same configuration in a safe environment.
This is where a reusable “minimum useful log” template pays off. Every AI feature you build can emit the same core fields, making incidents feel familiar instead of chaotic. Practical outcome: you shorten time-to-diagnosis, reduce guesswork, and build confidence that your monitoring is grounded in real production evidence.
1. Why does the chapter recommend treating each log entry as “a tiny, structured story” of a single AI request?
2. How do logs and metrics differ in the chapter’s framing?
3. A beginner worries that logging is messy, risky, and expensive. What is the chapter’s core response?
4. What is the main purpose of adding request IDs to your logging plan?
5. Why does the chapter suggest creating a reusable “minimum useful log” template?
Most beginner teams start monitoring with uptime and latency because those are visible and familiar. But in AI apps, the bigger risk is often quieter: the system is “up,” requests are fast, and yet the outputs are wrong, unsafe, off-brand, or simply unhelpful. This chapter shows how to monitor output quality without needing a full data science org, expensive evaluation platforms, or complex statistical pipelines.
The first move is to separate quality issues from reliability issues. Reliability covers whether the app runs (errors, timeouts, rate limits). Quality covers whether the app is doing the right thing when it runs. If you mix these, you’ll chase the wrong fixes: tweaking prompts when the real problem is rate limiting, or adding retries when the model is confidently hallucinating. Treat them as two dashboards and two incident categories, even if the same person owns both.
Next, accept a practical truth: you cannot measure “quality” perfectly. Instead, you build a small set of signals that are cheap to collect, easy to review, and strongly predictive of user experience. You start with human review and feedback capture, add simple automated checks (format, safety, relevance proxies), and then maintain a small test set to catch regressions. Finally, you decide what actions you’ll take when quality drops: rollback, route to another model, temporarily restrict features, or apply a targeted fix.
By the end, you’ll have a beginner-friendly workflow that protects users and reduces firefighting—even if you’re a small engineering team shipping fast.
Practice note for Milestone: Separate “quality” issues from “reliability” issues: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Set up basic human review and feedback capture: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Track simple quality checks (format, safety, relevance): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Create a small test set to catch regressions: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Choose actions when quality drops (rollback, route, fix): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Separate “quality” issues from “reliability” issues: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Set up basic human review and feedback capture: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Quality monitoring starts with a definition you can actually apply. For beginner teams, the most workable definition is: usefulness (did it help the user accomplish the task?) and correctness (is it accurate enough and aligned with policy?). You don’t need a single numeric “quality score” to begin; you need a small set of checks that map directly to user pain.
Usefulness is contextual. A chatbot answer can be factually correct but still useless if it’s too long, missing the next step, or ignores the user’s constraints. Correctness is also contextual: in a creative writing app, “correctness” might mean following style guidelines; in a customer support assistant, it might mean quoting policy accurately and not inventing refund terms.
Write a one-page Quality Contract for your feature. Keep it concrete and testable. Example:
This contract helps you separate quality from reliability. A timeout is reliability. A valid JSON response with the wrong policy is quality. A malformed JSON response is often both (quality symptom with reliability-like handling). In your monitoring, tag incidents accordingly. The practical outcome is faster debugging: reliability problems get engineering fixes (timeouts, retries, caching); quality problems get prompt/model/config fixes and review workflow improvements.
Common mistake: defining quality as “no hallucinations.” That’s too broad and hard to enforce. Instead, define what counts as a harmful hallucination in your product (e.g., invented pricing, fabricated citations, or made-up user data) and monitor for those.
To monitor quality effectively, learn the failure patterns you’ll see repeatedly. Two of the most common are hallucinations (confidently incorrect content) and refusal issues (the model declines when it shouldn’t, or complies when it must refuse). Treat these as trackable categories, not mysterious “AI weirdness.”
Hallucinations often show up in predictable places:
Refusal issues split into two types. Over-refusal is when the model declines safe requests (“I can’t help with that”) and harms the user experience. Under-refusal is when the model provides disallowed content (privacy leaks, unsafe instructions, disallowed categories). Both are quality problems with high user impact and potential compliance risk.
Monitoring implication: you need fields in your logs that let you diagnose these quickly. At minimum capture: prompt version, model name, safety mode/config, retrieval on/off, top-k results IDs, and the final output. When you see an over-refusal spike, you can correlate it with a safety config change or a prompt tweak. When hallucinations spike, you can correlate with retrieval failures, missing context, or a model swap.
Common mistake: treating every hallucination as a reason to “just add more instructions.” Often the real fix is structural: require citations, restrict outputs to a schema, or route high-risk queries to retrieval + grounded answering. Another mistake is ignoring refusals because “at least it’s safe.” Over-refusal is a quality regression; track it like any other.
You can get meaningful quality monitoring with extremely simple human feedback, as long as it’s captured consistently. The baseline is thumbs up/down plus an optional comment. This is your “low-cost evaluation harness” that works without a data science team.
Implementation guidance:
To set up basic human review, create a small weekly review queue. Sample 20–50 interactions across key use cases (or 1–2% of traffic). Include both thumbs-down items (high signal) and a random sample of thumbs-up (to detect “silent” issues users didn’t notice). Assign two people when possible for calibration; if not, rotate ownership weekly and keep a short rubric.
The rubric should map to your Quality Contract from Section 4.1. For each reviewed item, record a quick label:
Practical outcome: you can chart “Bad rate” over time and set a threshold that triggers action (for example, Bad rate > 5% on high-traffic flows). This is the milestone of tracking quality without heavy tooling: your signals are small but actionable.
Common mistake: collecting feedback but never closing the loop. Every week, pick the top 1–2 recurring failure types and fix them (prompt change, formatting constraint, routing). Then note the change in a simple changelog so you can correlate quality shifts later.
Human review is powerful but limited. Automated checks catch issues at scale, especially those that are easy to verify: format, length, and policy constraints. Think of these as “unit tests for outputs,” not full semantic grading.
Start with structure checks. If your downstream code expects JSON, validate JSON. If you require specific fields, validate presence and type. If you require a bulleted list, check for list markers. Fail closed for machine-to-machine integrations: if parsing fails, return a safe fallback message and log the event as a quality failure.
Next add length checks. Length is a proxy for usefulness and cost. Very short answers may be non-responsive; very long answers may be rambling, slow, and expensive. Set guardrails per endpoint (e.g., 50–300 tokens for a summary). When outside bounds, either re-ask with a tighter instruction (one controlled retry) or route to a “compress” step.
Then add blocked content checks. Use a basic keyword/regex layer for obvious sensitive patterns (credentials, SSNs, credit card patterns), plus your provider’s moderation endpoint if available. Log the reason for blocking so you can see patterns (e.g., users attempting disallowed requests, or false positives caused by your own prompts).
These checks support the milestone of “track simple quality checks (format, safety, relevance).” For relevance, use lightweight proxies: does the response contain at least one of the user’s key nouns, or one retrieved source ID when retrieval is enabled? These are imperfect, but they surface obvious off-topic failures cheaply.
Common mistake: adding too many checks too early. Start with 2–3 that map to real incidents you’ve already seen. Each check should have a defined action: block, retry once, or escalate to review. Otherwise you’ll generate noise without improving quality.
Once you start improving prompts and swapping models, you need a way to prevent accidental regressions. The beginner-friendly method is a small golden set: a curated list of representative inputs with expected properties of good outputs. This is not a research-grade benchmark; it’s a practical safety net.
Build your golden set from real traffic and incidents:
For each example, store the input, any required context (retrieved docs or tool outputs), and the evaluation criteria. Avoid writing a single “expected text” because LLM outputs vary. Instead, use assertions: must include certain fields, must cite sources, must not mention prohibited content, must not exceed a length, must answer in the required language. If you do store a reference answer, treat it as guidance for reviewers, not an exact match.
Run the golden set whenever you change: prompt templates, system instructions, safety settings, retrieval configuration, or model version. Compare metrics like schema pass rate, refusal rate, and presence of citations. For a small team, a simple script plus a spreadsheet is enough.
This milestone (“create a small test set to catch regressions”) pays off during fast iteration. Without it, you’ll ship a prompt improvement for one scenario that silently breaks another. With it, you’ll catch failures before users do.
Common mistake: letting the golden set go stale. Refresh it monthly: retire examples no longer relevant, add new edge cases from recent thumbs-down feedback, and keep the set small enough that it runs in minutes, not hours.
Quality monitoring only works if you can connect a quality shift to a specific change. That requires basic versioning of three things: prompts, models, and configuration (retrieval settings, tool availability, safety thresholds, temperature/top-p, max tokens). You don’t need a fancy platform—just consistent identifiers and a changelog.
Practical setup:
prompt.support.v3.Every request log should include these identifiers. When your “Bad rate” rises, you can answer: did it start right after prompt.support.v3 shipped? Did it correlate with turning retrieval off? Did a new safety filter increase over-refusals?
Now connect this to the milestone of choosing actions when quality drops. Pre-decide your options:
Common mistake: changing multiple things at once (new prompt + new model + new retrieval settings). That makes causality impossible. Make one change, measure, then proceed. When you must bundle changes, label the release as a single versioned “bundle” and test it against the golden set before rollout.
The practical outcome is control: when output quality drops, you don’t guess. You identify the change, pick an action, and restore acceptable behavior quickly—without needing a large specialized team.
1. Why does Chapter 4 recommend separating “quality” issues from “reliability” issues into different dashboards and incident categories?
2. What is the chapter’s practical approach to measuring output quality without a data science team?
3. Which combination best reflects the core components of the chapter’s quality monitoring loop?
4. What is the main purpose of maintaining a small “golden” test set in this chapter’s approach?
5. If you detect a drop in output quality, which action aligns with the chapter’s recommended response options?
Reliability without cost control is fragile. A feature that “works” but silently burns money will eventually get throttled, turned off, or replaced—often during an incident, when you can least afford change. This chapter gives you a beginner-friendly way to identify your biggest cost drivers, track spend at the level that matters (feature, user, request), and apply simple guardrails so your AI app remains predictable in production.
Most teams underestimate how quickly small inefficiencies compound: one extra retry per request, an overly large prompt template, a cache that never hits, or a long-running tool call that blocks the model. The goal is not to chase the lowest possible cost. The goal is to buy reliability and user value with an amount of spend you can explain, forecast, and defend.
We’ll treat costs as first-class monitoring signals, just like latency and error rate. You’ll learn to balance cost vs quality with rules you can implement in a weekend: “use the small model unless confidence is low,” “cap maximum tokens per request,” “fallback to retrieval-only when tools fail,” and “review the top 10 costliest traces each week.” Finally, you’ll draft a monthly cost review checklist that keeps surprises out of invoices.
Practice note for Milestone: Identify the biggest cost drivers in an AI app: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Track spend per feature, user, and request: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Use guardrails (limits, caching, fallbacks) to prevent bill shocks: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Balance cost vs quality with simple rules: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Draft a monthly cost review checklist: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Identify the biggest cost drivers in an AI app: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Track spend per feature, user, and request: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Use guardrails (limits, caching, fallbacks) to prevent bill shocks: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Balance cost vs quality with simple rules: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
To control cost, you need to understand what you are actually paying for. In most AI apps, spend comes from three buckets: per request (API calls), per token (input and output text), and per minute (tooling and infrastructure time). An “AI request” is rarely a single call; it’s a chain: prompt assembly, retrieval, one or more model calls, tool calls (search, database, browser, code execution), and sometimes follow-up calls for formatting or self-checks.
Per request costs show up when you call paid services: embeddings, rerankers, moderation endpoints, speech-to-text, or multiple model invocations. Even if token prices are low, a high number of calls per user action can dominate your bill. Count calls explicitly: “one chat turn uses 1 embedding call + 1 rerank + 2 LLM calls.” That count is your baseline.
Per token costs are the most visible. Tokens are charged on both input (system prompt, instructions, conversation history, retrieved documents) and output (the model’s response). Beginners often focus only on the user’s question, but the expensive part is frequently your own prompt template and the retrieved context you attach. A small change like adding verbose instructions, logging the entire chat history, or stuffing in five documents instead of two can double token usage immediately.
Per minute costs come from latency: long tool calls, slow model responses, and idle compute waiting on network requests. If you host any part yourself—vector DB, reranking, crawling, or batch jobs—then runtime becomes real money. Even in serverless setups, long execution can increase spend and reduce throughput, which may trigger more retries and further cost.
Milestone: Identify the biggest cost drivers in an AI app. Start by drawing a simple request diagram: boxes for each call (LLM, embeddings, search, DB) and arrows for sequence/parallelism. Add “how often” (per user action) and “how big” (tokens, seconds). The biggest driver is usually the product of frequency × size. This diagram becomes the map you’ll use in the rest of the chapter.
Monitoring cost is not the same as reading a provider invoice. Invoices are delayed and aggregated; engineers need near-real-time numbers tied to product behavior. The most useful unit is cost per request (or cost per “user action,” like “generate summary” or “answer support ticket”). Compute it by logging: model name, input tokens, output tokens, number of calls, and tool runtimes. Multiply tokens by your provider’s rates, add per-call fees, and store the estimated cost alongside your trace or request ID.
Cost per request answers: “What does this feature cost when it runs?” But it doesn’t answer: “Is it worth it?” For that you need cost per outcome. Define the outcome in product terms: “ticket resolved,” “draft accepted,” “user saved time,” “answer marked helpful.” Then track how many requests it takes to produce that outcome and what they cost.
Milestone: Track spend per feature, user, and request. Add three tags to every logged request: feature_name (e.g., “invoice_extraction”), user_id (or account ID), and request_id. Aggregate daily: total cost by feature, cost per active user, and p95 cost per request. The p95 matters because tail cases (huge documents, long chats) often drive a disproportionate amount of spend.
Common mistake: tracking only “total daily spend.” Total spend can look stable while per-request cost is rising and usage is falling—masking a regression. Another mistake: mixing environments. Always tag env=prod|staging so load tests and debug sessions don’t distort production baselines.
Waste is any spend that doesn’t improve user outcomes. The fastest savings usually come from eliminating wasted calls, not from switching models. Three common sources are retries, timeouts, and duplicate calls.
Retries are necessary for reliability, but uncontrolled retries can double or triple cost during partial outages. Use bounded retries with exponential backoff and jitter, and retry only on retryable errors (rate limit, transient network). Log retry_count and the final error type; alert when retry rate spikes because that’s both a cost event and a reliability event.
Timeouts prevent a request from hanging, but they can still burn money if you time out after the provider has already processed tokens. Set timeouts based on user tolerance and on the model’s typical completion time. A practical approach: set a “soft timeout” where you stop waiting and return a fallback response, while a background task may continue only if it produces reusable output (like a cached summary). If background output won’t be reused, cancel it aggressively.
Duplicate calls happen when frontend and backend both call the model, when users double-click, when you re-run a step after a partial failure, or when multiple services independently fetch the same context. Use idempotency keys: for each user action, generate a stable key (e.g., hash of user ID + feature + normalized input) and store the result for a short window. If the same key arrives again, return the existing result instead of re-paying.
Engineering judgment: don’t remove retries blindly. Instead, pair retries with fallbacks. For example: if tool calling fails twice, return a response that explains the limitation and provides next steps, or switch to a simpler “no-tools” answer. That’s a cost control mechanism and a user experience improvement.
Common mistake: adding a “self-check” second LLM call to every request. Self-checks can help quality, but treat them as conditional: run them only on high-risk outputs (financial, medical, compliance) or when confidence signals are low. Cost control is about selective effort, not constant effort.
Once waste is under control, target structural savings. Three techniques—caching, smaller models, and truncation—cover most beginner wins without changing your product.
Caching means you don’t pay twice for the same work. Cache at multiple layers: (1) embeddings for documents and frequent queries, (2) retrieval results for identical queries within a short window, and (3) final LLM responses for deterministic prompts (or nearly deterministic, if you normalize inputs). Keep cache keys stable by trimming whitespace, sorting JSON keys, and removing irrelevant metadata. Measure cache hit rate and the dollars saved; a cache that hits 5% may still be worth it if those hits are on expensive requests.
Smaller models are your default, not your fallback. Route requests by complexity: use a small model for classification, extraction, and short answers; escalate to a larger model only when needed. Create a simple policy: “If retrieved context is under N tokens and user intent is in our top K intents, use model A; otherwise use model B.” Log the route decision so you can audit when the expensive model is used.
Truncation is the most direct token control. Cap conversation history and retrieved context with explicit budgets (e.g., 2,000 tokens history + 1,500 tokens retrieval). Summarize older history into a compact note instead of dragging the full transcript forward. For retrieval, prefer fewer, higher-quality chunks: rerank and include the top 2–3 rather than dumping 10. Truncation should be deliberate: keep the parts that affect correctness (constraints, user preferences, definitions) and remove the rest.
Milestone: Balance cost vs quality with simple rules. Write down two or three rules that trade cost for quality in a controlled way. Examples: “If confidence low, ask a clarification question instead of generating a long answer,” or “If user uploads a large file, require a paid tier or process asynchronously.” The point is to make trade-offs visible and consistent, not accidental.
Guardrails prevent bill shocks. They are not just financial controls; they are reliability features that keep your system stable under spikes, abuse, and bugs. Implement guardrails at three levels: per request, per user/account, and globally.
Per request limits include maximum input size, maximum output tokens, maximum tool calls, and maximum wall-clock time. If a request exceeds limits, return a helpful error or a degraded mode. Example: “This document is too long for instant processing; we’ll email results when ready,” or “Showing an extract instead of a full rewrite.” These limits make worst-case cost predictable.
Per user/account quotas protect you from a single tenant consuming the budget. Set daily or monthly token quotas by plan, and enforce them with clear messaging. For internal tools, set quotas by team or API key to catch runaway automations early. Track “quota near miss” events; they are leading indicators that a customer will churn or that you should upsell.
Global hard caps are your last line of defense. Define a maximum daily spend for production. If spend approaches the cap, you can automatically switch to cheaper models, disable expensive features, or require human confirmation for high-cost actions. This is uncomfortable but necessary—especially early on—because bugs happen: an infinite loop that calls the model, a queue misconfiguration, or an unintended traffic source.
Common mistake: setting caps without fallbacks. A hard cap that simply breaks the product creates incidents. Instead, predefine what degrades first (e.g., turn off “rewrite in three tones,” keep “basic answer”), and document the behavior in your incident playbook.
Practical outcome: after adding guardrails, you should be able to answer, “What is the maximum cost of one request?” and “What is the maximum cost one user can generate per day?” Those two answers eliminate most surprises.
You don’t need heavy tooling to get useful cost visibility. A basic dashboard can be built from your logs and a small set of aggregates. At minimum, track: daily spend, spend by feature, p95 cost per request, retry rate, cache hit rate, and the distribution of input/output tokens.
Daily spend is your heartbeat. But make it actionable by splitting it into “expected spend” and “unexpected spend.” Expected spend is driven by traffic; unexpected spend is driven by regressions like prompt growth, tool failures, or a routing rule that sends everything to the largest model.
Anomaly detection can be simple: alert when today’s spend is 30% above the 7-day moving average, or when p95 tokens per request exceed a threshold. Also alert on structural signals: retry rate doubling, cache hit rate dropping, or tool latency spiking. These are leading indicators that costs will rise before the invoice does.
Forecasts help you plan. A straightforward forecast is: forecast_monthly_cost = (avg_cost_per_request_last_7d) × (forecasted_requests). If you don’t have good demand forecasting, use last week’s traffic as a baseline and add scenario bands (low/medium/high). The key is to make assumptions explicit so product and engineering can discuss trade-offs.
Milestone: Draft a monthly cost review checklist. Keep it short and repeatable: (1) Top 3 most expensive features and why, (2) Top 10 costliest traces with links to logs, (3) Model routing breakdown and any drift, (4) Cache hit rate and largest misses, (5) Retry/timeout stats and top error types, (6) Token budget changes in prompts and retrieval, (7) Quota/cap events and whether users were impacted, (8) One concrete cost-control experiment for next month.
Done well, cost dashboards shift the team from reactive bill reading to proactive engineering. Your goal is not just “spend less,” but “spend deliberately,” with clear links between dollars, latency, and user outcomes.
1. Why does the chapter argue that “reliability without cost control is fragile” in production?
2. Which tracking approach best matches the chapter’s recommendation for making AI spend explainable and actionable?
3. Which is an example of a small inefficiency that can compound into major cost over time, according to the chapter?
4. Which set of guardrails best aligns with the chapter’s goal of preventing bill shocks while keeping the app predictable?
5. Which rule best reflects the chapter’s approach to balancing cost vs quality with simple, implementable logic?
Monitoring only becomes “real” when it changes what you do day to day. In earlier chapters you collected signals (logs, metrics, user feedback), measured quality, and watched cost drivers like tokens, latency, retries, and caching. This chapter turns those signals into an operating system: alerts that are actionable, an incident playbook that a beginner can follow, and a simple improvement loop that prevents repeat failures.
In AI apps, incidents rarely look like a clean server outage. A model can respond, yet be wrong; it can be correct, yet too slow; it can be fast, yet expensive due to retries or long prompts. Your goal is to connect reliability, quality, and cost so you can detect problems quickly, restore service safely, and learn in a way that steadily improves the product.
By the end of this chapter you will have (1) alert rules that wake you up only when someone needs to act, (2) a basic incident playbook for AI issues, (3) a lightweight post-incident review template, (4) a release readiness checklist, and (5) a weekly routine that keeps reliability, quality, and cost under control without heavy tooling.
Practice note for Milestone: Write alert rules that are actionable (not noisy): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Build a basic incident playbook for AI issues: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Run a simple post-incident review and prevent repeats: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Create a monitoring checklist for new AI releases: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Combine reliability, quality, and cost into one operating routine: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Write alert rules that are actionable (not noisy): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Build a basic incident playbook for AI issues: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Run a simple post-incident review and prevent repeats: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Create a monitoring checklist for new AI releases: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Milestone: Combine reliability, quality, and cost into one operating routine: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
An alert is useful only if it triggers a clear action. “CPU is high” is not a beginner-friendly alert; “95th percentile latency over 5 seconds for 10 minutes on the summarize endpoint” is better because it points to a user-visible symptom and a specific surface area. Your milestone here is to write alert rules that are actionable (not noisy).
Start with three alert categories that map to your reliability goals: uptime (is it working), speed (is it timely), and correctness/quality (is it acceptable). Add a fourth category for cost (is it sustainable). For each category, define: the signal, the threshold, the evaluation window, and the runbook link (even if the runbook is a short doc). Example: “Error rate > 2% for 5 minutes” for uptime; “p95 latency > 4s for 10 minutes” for speed; “human review fail rate > 15% today” for quality; “tokens per request up 40% week-over-week” for cost.
Common mistakes create noisy alerts: alerting on raw counts instead of rates, using thresholds without context, and alerting on symptoms you cannot act on. Fix this by choosing SLO-aligned signals and adding suppression rules. For example, if a vendor API outage is already known, temporarily route alerts to a status channel rather than paging. Also prefer multi-window alerts: a fast trigger for sharp changes (2–5 minutes) and a slower trigger for sustained degradation (15–60 minutes) to reduce false positives.
Finally, don’t forget “silent failures.” For AI, a pipeline can succeed technically while producing unusable outputs. If you run a review workflow, alert on review volume anomalies (sudden drop to zero) and on distribution shifts (e.g., sudden increase in “unknown” classifications). These are often your earliest indicators that something changed in prompts, retrieval, or upstream data.
You don’t need a large team to do on-call well—you need clarity. A basic on-call setup defines who responds, how to classify severity, and when to escalate. This is your second milestone: build a basic incident playbook for AI issues.
Define three roles, even if one person fills multiple roles: Responder (handles the alert and mitigation), Comms (updates stakeholders/users), and Decider (approves risky actions like disabling features or rolling back). In a small team, the Responder is often also the Decider, but writing it down prevents hesitation during a stressful moment.
Use a simple severity scale tied to user impact and money:
Escalation should be based on time and evidence. If SEV-1 is not mitigated within 15–30 minutes, escalate to a second engineer or a domain expert (prompt/retrieval/model). If you rely on an external LLM provider, define when to switch regions/models or contact vendor support. A key beginner move is to keep escalation paths short: one backup person, one vendor contact method, and one “safe mode” lever.
Comms matters more than perfect diagnosis. During incidents, publish short updates: what’s impacted, what users can do (retry later, use fallback), and when the next update will come. Avoid speculation. Internally, track decisions and timestamps; these notes will become your post-incident review timeline.
A practical AI incident triage starts with categorization. Most alerts fall into one of four buckets: down (requests fail), slow (latency spikes), wrong (quality degrades), or expensive (cost spikes). Having a standard flow reduces panic and prevents “random debugging.”
Step 1: Confirm user impact. Check your top-level dashboard: request success rate, p95 latency, and volume. If volume drops to near zero, you may have an upstream outage (auth, UI, queue) rather than the model. If error rate spikes, inspect a few sample logs with correlation IDs to see whether failures are timeouts, 429 rate limits, or parsing errors.
Step 2: Localize the blast radius. Is it one endpoint, one model version, one region, one customer segment, or all traffic? Compare metrics by tag: model=“gpt-4o-mini”, prompt_version=“v12”, retriever=“vector-v3”. Beginners often skip tagging; without tags, everything looks global and mitigation becomes risky.
Step 3: Choose the right diagnostic lens:
Step 4: Apply the smallest safe mitigation. If you can’t fully fix quickly, aim to stop the bleeding: reduce max tokens, tighten timeouts, disable optional tools, or switch to a cheaper/faster model temporarily. Document what you changed and why. A common mistake is “fixing” by redeploying multiple changes at once; you lose the ability to learn what helped.
AI features need safety valves. Because failures can be subtle (wrong answers) or financially dangerous (token spikes), you should plan rollback and fallback strategies before you need them. This section connects monitoring to control: your alert should often trigger a known mitigation step.
Rollback means returning to a previous known-good configuration: older prompt, older model version, older retriever index, or previous post-processing code. Treat prompts and retrieval settings as versioned artifacts. If you can’t roll back quickly, you don’t really control the system. At minimum, keep a “last good” prompt_version and a deploy switch (feature flag or environment variable) that can revert without a full redeploy.
Fallback means providing a reduced but reliable experience when the primary path fails. Common fallbacks for beginner AI apps include:
Plan what “safe mode” looks like for each incident type from Section 6.3. If you’re slow, reduce retrieval depth (top-k), shorten context, or enable aggressive caching. If you’re wrong, temporarily disable a new prompt or data source and revert to the previous one. If you’re expensive, clamp max output tokens and reduce retries. The practical outcome is that your first responder can restore acceptable service in minutes, even if the root cause takes days.
Test these controls intentionally. Once per release cycle, simulate a provider 429 storm and confirm that fallback triggers, alerts fire, and the user experience remains coherent. Beginners often discover their fallback path is broken only during a real incident—when it’s too late.
Incidents are expensive; wasting them is worse. Your third milestone is to run a simple post-incident review and prevent repeats. The goal is not to assign fault—it is to improve the system so the same class of failure becomes less likely, less severe, or faster to detect.
Keep the review lightweight and structured, ideally within 48–72 hours while context is fresh. Use a one-page template:
For AI incidents, root causes often involve interaction effects: a prompt change increases tokens, which increases latency, which triggers retries, which explodes cost. Capture these chains explicitly. Then add controls: token budgets, retry limits, circuit breakers, and evaluation gates. Another common class is “silent quality regression.” The fix is usually a better review workflow: add sampling, increase coverage for critical intents, or create a golden set that runs on every release.
Close the loop: action items should update your alert rules, runbooks, and release checklist. If an incident was detected by users before monitoring, that is a monitoring bug—treat it like one, and fix it.
Reliability is a habit. Your fourth and fifth milestones are to create a monitoring checklist for new AI releases and to combine reliability, quality, and cost into one operating routine. You want a rhythm that is small enough to sustain, but strict enough to prevent avoidable incidents.
Weekly operating routine (30–60 minutes): review a small dashboard that includes (1) error rate and uptime, (2) p50/p95 latency, (3) tokens/request and cost per successful request, (4) cache hit rate and retry rate, and (5) quality signals such as human review pass rate, user thumbs-up, or complaint rate. Look for trends, not just spikes. A slow 5% week-over-week token increase is often more dangerous than a one-day blip.
Release readiness checklist (run before shipping prompt/model/retriever changes):
Make this checklist part of your definition of done. Beginners often treat monitoring as “after launch,” which guarantees the first real test happens in production under user pressure. If you integrate checks into releases, you turn incidents into rare exceptions instead of routine surprises.
Finally, keep tightening the loop. Every alert should point to a runbook step. Every incident should update at least one guardrail. Over time, you will feel the system become calmer: fewer pages, faster triage, safer mitigations, and predictable cost. That is continuous improvement in practice—reliability, quality, and cost managed together as one disciplined workflow.
1. Why does monitoring only become “real” in this chapter’s framing?
2. Which alert rule best matches the chapter’s goal of being actionable (not noisy)?
3. Which situation best reflects how AI incidents can differ from a traditional server outage?
4. What is the main purpose of running a simple post-incident review in this chapter?
5. What does the chapter recommend combining into one operating routine to keep the product under control?
- Learning Evolved.
- Intelligence Amplified.


