Computer Vision — Beginner
Learn to spot objects in images and video from zero
This beginner course is designed like a short, practical book that teaches you one clear idea at a time. If you have ever wondered how apps, cameras, or smart systems can find people, cars, pets, or products inside photos and video, this course will show you the basics in plain language. You do not need any prior background in artificial intelligence, coding, or data science. We start with the very first question: how can a computer look at an image and decide where an object is?
Instead of overwhelming you with heavy theory, this course focuses on simple explanations, visual thinking, and realistic beginner outcomes. By the end, you will understand the full object detection journey: what it is, how it learns from examples, how to read results, how image detection differs from video detection, and how to think about real-world use responsibly.
Many AI courses assume too much too early. This one does the opposite. Each chapter builds naturally on the previous one, so you can develop confidence as you go. First, you learn what computer vision is and how object detection differs from other tasks. Then you explore training data, labels, bounding boxes, and confidence scores in everyday language. After that, you move into practical workflows for photos and video, ending with project planning and ethical awareness.
You will learn how AI systems spot objects in images, why training data matters, and how to tell whether a model is doing a good job. You will also see how object detection works differently in still photos compared with moving video. The course avoids unnecessary jargon and explains every concept from first principles, making it ideal for complete beginners.
The course contains six chapters, each acting like a chapter in a short technical book. Chapter 1 introduces the basic idea of AI vision and object detection. Chapter 2 explains how models learn from labeled examples. Chapter 3 teaches you how to read results with confidence and understand common errors. Chapter 4 focuses on object detection in photos. Chapter 5 extends those ideas to video, where movement and changing scenes create new challenges. Chapter 6 brings everything together with practical use cases, ethics, and a beginner project plan.
This structure helps you learn in a logical order. You will never be asked to understand advanced tools before you know what problem those tools are solving. That means you can move from curiosity to competence step by step.
This course is perfect for students, professionals changing careers, creators, teachers, business learners, and anyone curious about visual AI. If you want a friendly first step into computer vision, this is a strong place to begin. It is especially useful if you want to understand AI products, evaluate object detection demos, or prepare for more advanced computer vision study later.
If you are ready to start learning, Register free and begin today. You can also browse all courses to explore related beginner topics in AI and computer vision.
Object detection is one of the most useful applications of AI in the real world. It supports systems in retail, manufacturing, transport, healthcare, security, and consumer technology. Even if you never become an engineer, understanding how these systems work will help you make better decisions, ask smarter questions, and participate in modern AI conversations with confidence.
By the end of this course, you will not just know what object detection is. You will understand how it works at a beginner level, how to interpret its outputs, and how to think clearly about using it in practice.
Machine Learning Engineer and Computer Vision Educator
Sofia Chen builds practical AI systems that help people understand images and video. She specializes in teaching complex computer vision ideas in simple language for first-time learners. Her courses focus on hands-on understanding, clear examples, and real-world use cases.
When people say an AI system can “see,” they do not mean it sees the world the way a person does. A camera captures light, stores that light as image data, and then a computer processes the data using mathematical patterns. In object detection, the goal is not only to say what is in an image, but also where it is. That simple idea powers many practical systems: counting cars on a road, finding faces in a photo, spotting products on a shelf, or identifying tools in a factory image. For beginners, object detection becomes much easier to understand once you break it into a few core ideas: images are data, models learn visual patterns, and detections are reported as boxes, labels, and confidence scores.
This chapter introduces the basic language of object detection in plain terms. You will see how computers read images as grids of pixel values, how that differs from human vision, and why AI needs examples before it can recognize useful patterns. You will also learn the difference between classification and detection, because many beginners mix them up. Classification answers a question like, “What is this image mostly about?” Detection answers a richer question: “What objects are here, and where are they located?” In videos, an additional step called tracking helps follow those detected objects across frames over time.
As you move through this chapter, think like an engineer, not just a user. An engineer asks practical questions: Is the image clear enough? Are the objects large enough to detect? Are labels consistent? Is the confidence score high enough to trust? These decisions matter because object detection is not magic. Results depend heavily on image quality, data preparation, the choice of tool, and the context in which a model is used. A model that works well on bright daytime street images may struggle at night or in rain. A model trained to detect dogs in photos may fail on cartoon drawings or thermal images.
By the end of the chapter, you should be comfortable reading a basic detection result and explaining it to someone else. You should know what a bounding box is, what a class label means, why confidence scores are estimates rather than guarantees, and how beginners can test a model with user-friendly tools. Just as importantly, you should understand the limits of early results. A box around an object is not proof that the system truly “understands” the scene. It is a prediction based on data. That mindset will help you build better projects throughout the course.
In the sections that follow, you will connect these ideas to everyday examples and to the workflow of a simple object detection project. That includes choosing images, checking whether annotations make sense, understanding what a model can and cannot infer, and testing detections on both photos and video frames. This foundation matters because every later topic in object detection, from training to evaluation to deployment, depends on understanding what a detection result really represents.
Practice note for Understand how computers read images as data: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Tell the difference between seeing, classifying, and detecting: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Identify common object detection examples in daily life: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
To a human, a photo looks like a meaningful scene: a street, a pet, a person, or a table with objects on it. To a computer, the same photo begins as a structured block of numbers. The image is made of pixels, and each pixel stores color information. In a common RGB image, every pixel has three values: red, green, and blue. When millions of these pixel values are arranged in a grid, the result is the picture you see. This is the first important beginner lesson: computers do not start with concepts like “car” or “cup.” They start with numeric data.
Why does this matter for object detection? Because the model must learn to connect patterns in those numbers to real-world object categories. Edges, textures, shapes, and color combinations all become clues. A wheel shape near a car body, for example, may help the model detect a vehicle. But if the image is blurry, too dark, or too small, those clues become weaker. That is why image quality matters so much in computer vision. A model cannot detect what the image does not show clearly.
For a beginner project, preparing image data means making sensible, simple choices. Use images where the target objects are visible, large enough, and not hidden too much by other objects. Try to include a variety of backgrounds and lighting conditions, but keep your labels consistent. If you are detecting bottles, decide whether cans count as bottles or not before you annotate your data. This is engineering judgement: the model can only learn from the rules your data teaches it.
Another practical point is image size. Larger images may preserve more detail, but they also require more memory and more processing time. Smaller images run faster but may lose tiny objects. Beginners often assume bigger is always better, but the right answer depends on the task. If you only need to find one large dog in a photo, a moderate image size may work well. If you need to detect tiny screws in a manufacturing image, you may need much higher resolution.
Common mistakes include using too few images, collecting images that all look nearly identical, or forgetting that poor labels create poor models. Even before training anything, you can inspect images manually and ask: Are the objects clear? Are there edge cases? Would a person agree on what should be labeled? Strong object detection starts with strong image data.
Humans and computers both work with visual input, but they do it very differently. A person can glance at a kitchen table and instantly understand context: a mug is next to a book, the spoon is partly hidden, and sunlight is causing a bright reflection. We combine raw sight with years of experience and common sense. Computer vision systems do not naturally have that kind of understanding. They process patterns from data and produce predictions based on what they learned during training.
This distinction is useful because it prevents a common beginner misunderstanding. When a model detects a cat, it does not “know” what a cat is in the human sense. It has learned statistical patterns that often match labeled cat examples. This can produce impressive results, but it also explains why models sometimes fail in surprising ways. A strange camera angle, unusual lighting, or a partially hidden object can confuse the system even when a human would still recognize the object easily.
Computer vision is the broader field that includes several tasks. Some models classify images, some detect objects, some segment shapes more precisely, and some estimate poses or recognize actions. Object detection is one of the most useful beginner entry points because the result is concrete and visual. You can look at an image and see whether the predicted box sits around the intended object. That makes it easier to inspect errors and learn what the model is doing.
In practice, object detection often follows a simple workflow. First, collect or choose images related to your problem. Next, define the object classes you care about. Then annotate examples by drawing boxes and assigning labels. After that, train or test a model. Finally, inspect the outputs and make decisions about whether they are accurate enough for your use case. At every step, human judgement is still required. AI helps automate visual tasks, but people define goals, check quality, and decide what level of error is acceptable.
For beginners using no-code or low-code tools, this idea is especially important. A friendly interface may make object detection feel easy, but behind the scenes the same principles still apply: image quality, class definition, dataset balance, and realistic expectations. The more clearly you understand the gap between human vision and computer vision, the better you will be at interpreting model results honestly and improving them step by step.
One of the most important concepts in this chapter is the difference between classification, detection, and tracking. These terms are related, but they solve different problems. Image classification asks what the whole image contains. If you show a classifier a photo of a beach with a dog in the corner, it might answer “beach” or “dog,” depending on what it was trained to do. It usually gives one label, or a small set of labels, for the image as a whole.
Object detection goes further. It does not just say what is present. It identifies each object instance and estimates where it is located. In that same beach image, a detector might draw one box around the dog, another around a surfboard, and another around a person. This is why detection is more useful for many real applications. If you want a security camera to notice a person entering a scene, location matters. If you want a retail system to count products on shelves, each item needs its own detection.
Tracking adds time. It is commonly used with video, where the system processes frame after frame. First, objects are detected in each frame. Then a tracking method tries to keep the identity of each object consistent over time, such as following the same car as it moves across the screen. This is important in applications like traffic monitoring, sports analysis, and robotics, where movement and continuity matter.
Beginners often confuse these tasks because they can look similar in demos. A classification demo may show a label on an image and seem visually impressive, but it cannot tell you where the object is. A detection demo gives boxes and labels, but it does not automatically maintain object identity across frames. Tracking requires an additional layer of logic.
From an engineering point of view, choose the simplest tool that matches your goal. If all you need is to decide whether an image contains a helmet or not, classification may be enough. If you need to locate every helmet in the image, use detection. If you need to follow workers wearing helmets as they move through video, use detection plus tracking. Clear problem definition saves time and prevents building a more complex system than necessary.
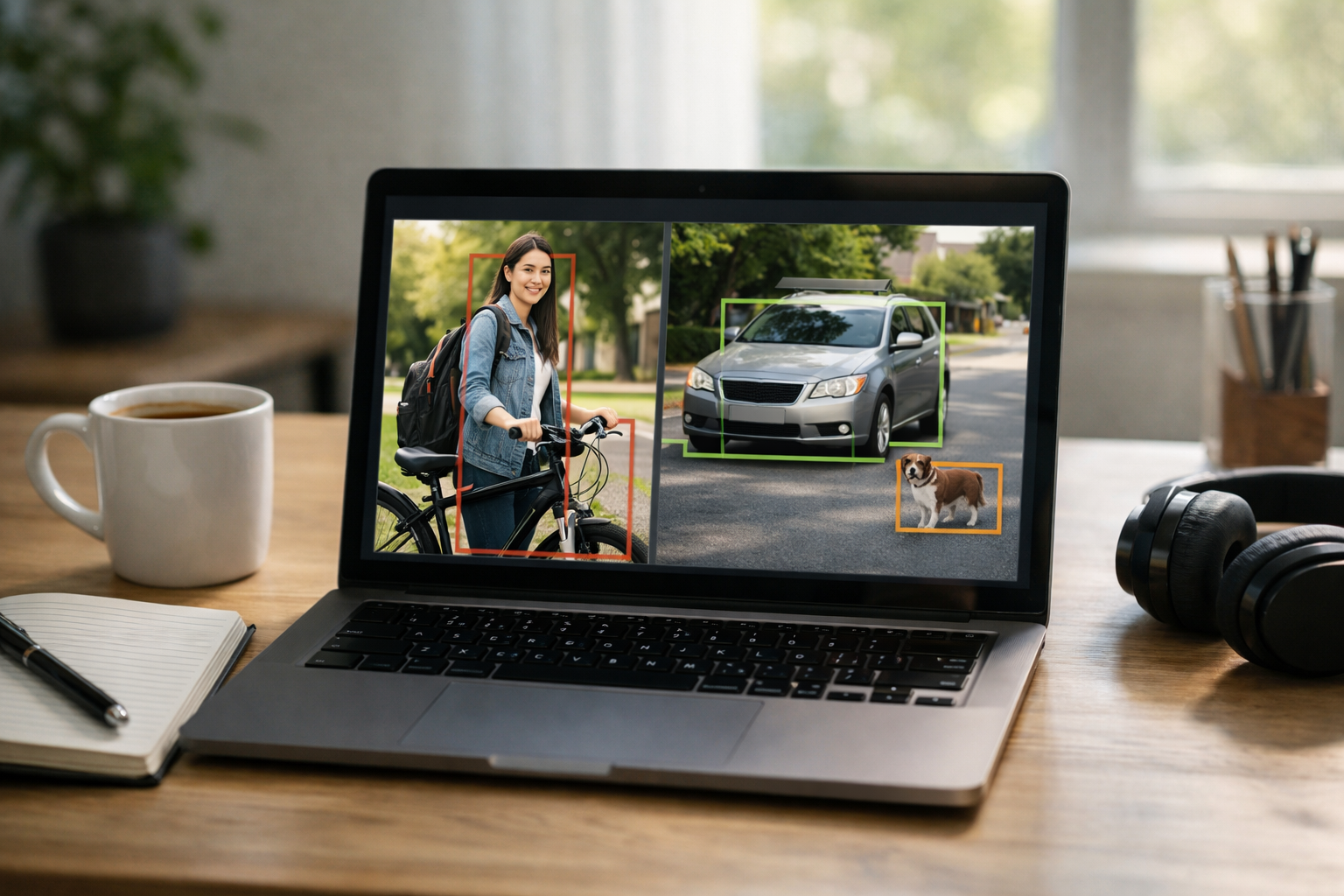
A standard object detection result usually contains three pieces of information: a bounding box, a class label, and a confidence score. The bounding box is a rectangle drawn around the object. It gives the model’s estimate of where the object is in the image. The class label names what the object is, such as “person,” “bicycle,” or “dog.” The confidence score estimates how sure the model is about that prediction, often shown as a number like 0.91 or 91%.
Reading these outputs correctly is a key beginner skill. A high confidence score does not guarantee correctness. It means the model is strongly leaning toward that prediction based on patterns it learned. A lower score does not automatically mean the detection is useless, especially in difficult images. Confidence thresholds are often used in practice to filter results. For example, a tool might only show detections above 0.5 confidence. Raising the threshold can reduce false positives, but it may also hide real objects that the model detected with lower confidence.
Bounding boxes are also approximations. They may not perfectly fit the object, especially when the object is rotated, partly hidden, or oddly shaped. For many applications, an approximate box is enough. If your goal is simply to count cars, a tight outline is not always necessary. But if precision matters, such as in medical or industrial tasks, you may need more exact methods or stricter quality checks.
When preparing data, labels must be consistent. If one annotator labels a parked motorcycle as “bike” and another uses “motorcycle,” the model receives mixed signals. Consistent naming matters just as much as consistent boxing. Another common mistake is drawing boxes too loosely in some images and too tightly in others. Models can learn from this inconsistency and become less stable.
Beginner-friendly tools usually let you upload an image, run a pretrained detector, and view boxes directly on the image. This is a great way to build intuition. Try observing when the model misses small objects, creates duplicate boxes, or labels similar objects incorrectly. Those are normal early failure modes. Learning to inspect outputs calmly and systematically is part of becoming effective with object detection.
Object detection appears in many everyday systems, often without users thinking about the technical details. Phone cameras use related vision features to focus on faces and highlight subjects. Cars and driver-assistance systems may detect pedestrians, lane-related objects, or nearby vehicles. Security cameras can flag people entering certain areas. Retail systems can monitor shelf stock, count items, or help automate checkout. In warehouses and factories, detection can locate packages, tools, or safety equipment. In agriculture, it can help spot fruit, animals, or signs of crop issues from images.
These examples show why detection is practical: many decisions depend not only on what is present but also on where it is. If a system detects a person near a dangerous machine, location is part of the safety logic. If a store wants to count bottles on a shelf, each bottle must be found separately. If a robot arm needs to pick up an object, it must know where the object is before it can act.
At the same time, real-world usage requires good engineering judgement. A system that works in a polished demo may fail in live conditions because of shadows, glare, camera shake, crowded scenes, or unusual objects. Beginners often focus only on the success cases. A better habit is to ask where the model will struggle. What happens when objects overlap? What happens if the camera angle changes? What happens if the object is tiny or partly off-screen? These questions lead to better datasets and more realistic expectations.
Another practical lesson is that not every use case needs a custom model right away. Pretrained models can already detect common classes such as people, cars, dogs, and chairs. For learning, this is ideal. You can test photos and videos quickly, inspect the outputs, and understand the format of results before collecting your own dataset. Later, if your project involves custom classes like helmets, tools, or plant diseases, you can move toward tailored training.
Daily-life examples make object detection feel approachable, but they also remind us that model outputs influence real decisions. That is why reliability, error inspection, and thoughtful deployment matter from the very beginning.
The easiest way to begin with object detection is to test a pretrained model on a single photo. Upload an image into a beginner-friendly tool, run detection, and study the result. Look for the boxes, labels, and confidence scores. Ask practical questions: Did the model find all obvious objects? Did it confuse similar categories? Were small or hidden objects missed? This simple exercise teaches you how to read detections and how to think critically about results instead of accepting them blindly.
Photos are a good starting point because they are stable. You can zoom in, inspect mistakes, and compare multiple images. They also help you prepare data for future projects. If you plan to build your own detector, begin by gathering clear images of your target objects and reviewing whether a human could label them consistently. Remove images that are too ambiguous unless handling ambiguity is part of your use case. A clean beginner dataset is often more valuable than a large messy one.
Video detection adds a new challenge: the model processes many frames in sequence. In practice, a video is just a rapid stream of individual images. The detector usually runs on each frame, and the results may vary slightly from frame to frame. A box can jitter. Confidence can rise and fall. An object visible in one frame may be missed in the next. This does not always mean the system is broken; video is simply more demanding because of motion blur, changing angles, and time pressure.
When you test on video, notice both accuracy and stability. Does the detector keep finding the same object as it moves? Are false detections appearing briefly and disappearing? This is where tracking can become useful later, but even before that, you can learn a lot by observing frame-by-frame results. If your model misses objects only when they are far away or moving fast, that tells you something important about the images it may need for training.
For complete beginners, the practical outcome of this first chapter is simple but powerful: you should now be able to open a detection demo, run a model on a photo or short video, and explain what the output means. You can describe the image as data, distinguish classification from detection, interpret boxes and confidence scores, and recognize where object detection is useful in real life. That foundation prepares you for the more hands-on parts of the course.
1. What is the main difference between image classification and object detection?
2. How does a computer read an image in object detection?
3. Which combination best describes a basic detection result?
4. Why should confidence scores be treated carefully?
5. Which situation best shows why object detection results depend on context?
In Chapter 1, you learned what object detection does: it finds objects in an image and tells you what they are. Now we move one step deeper and answer a very practical question: how does an AI system learn to do that? For complete beginners, the easiest way to think about learning in AI is this: the model studies many examples, notices visual patterns, and gradually gets better at predicting where objects are and what category each object belongs to.
Object detection is different from image classification. A classifier might look at a photo and say, “This image contains a dog.” An object detector must do more work. It must say, “There is a dog here,” draw a box around it, attach the label dog, and usually provide a confidence score such as 0.91 to show how sure it is. In a photo with three dogs and one bicycle, detection must identify each separate object. That is why the training data for object detection needs more detail than simple image labels.
At a high level, a beginner-friendly workflow looks like this: collect images, annotate them with labels and bounding boxes, split the data into training, validation, and test sets, train a model, review its predictions, and improve the dataset when the results are weak. This chapter explains that workflow in plain language. You will see why examples matter, why labels and boxes are essential, how the basic training and testing process works, and why careful data preparation usually matters more than adding random extra images.
Good object detection depends on engineering judgment, not just software. You must decide what counts as an object, how tightly to draw boxes, whether blurry examples should be included, and how much variety the model needs. These choices shape what the model learns. A strong beginner habit is to think from the model’s point of view: if a human could learn from these examples, are the examples clear, consistent, and representative of the real task?
By the end of this chapter, you should be able to describe how a detection model learns in plain language, read annotations with more confidence, and make smarter decisions when preparing simple image data for a beginner project.
Practice note for Understand training data in simple terms: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Learn how examples teach a model what objects look like: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for See why labels and boxes are important: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Explain the basic training and testing process: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand training data in simple terms: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
A model is the part of the AI system that learns patterns from examples. You can think of it as a very large pattern-matching machine. It does not “understand” objects the way people do. It does not know what a bicycle is because it has ridden one. Instead, it learns that certain shapes, colors, edges, and textures often appear together and are usually labeled bicycle. During training, the model adjusts many internal numbers so that its predictions become closer to the correct answers.
For object detection, the model learns two jobs at the same time. First, it learns classification: deciding whether something is a person, car, cat, bottle, or another category. Second, it learns localization: predicting where that object is in the image. Localization is usually represented with a bounding box, often written as coordinates for the left, top, right, and bottom edges, or as center position plus width and height.
A simple mental model helps here. Imagine showing a child hundreds of street photos and pointing at every car, bus, and pedestrian. Over time, the child becomes better at spotting them quickly. An AI model learns in a similar example-driven way, except it needs structured labels and boxes instead of spoken explanations. The model is not storing full images like a photo album. It is compressing patterns into parameters that help it make future predictions on new images.
This is why a model can perform well on one task and poorly on another. A detector trained on warehouse boxes may not work well on fruit in a supermarket because it has learned patterns from one visual world, not all possible scenes. Practical outcome: when choosing or testing a beginner-friendly model, always ask, “What kinds of images was it likely trained on, and how similar are those to my images?” That question saves time and sets realistic expectations.
Training data is the collection of examples the model studies while learning. In object detection, an example is usually an image paired with annotation data. The image shows the scene, and the annotation tells the model what objects appear and where they are. If the annotations are missing, inconsistent, or wrong, the model learns the wrong lesson. That is why people often say, “garbage in, garbage out.”
Examples teach a model what objects look like under different conditions. A car can appear close or far away, in sunlight or shade, parked or moving, fully visible or partly hidden. If your dataset includes only clean side views of cars, the model may struggle with front views, nighttime scenes, or partially blocked cars. Good training data covers the variation the model will face later. This includes different backgrounds, sizes, camera angles, lighting conditions, and image quality levels.
Labels are the names of the object categories. For beginners, it is best to keep labels simple and clearly defined. For example, if you use both car and vehicle without a clear rule, annotation becomes inconsistent. One person may label a van as vehicle, while another labels it as car. The model then receives mixed signals. Strong engineering judgment means defining classes in a way that humans can apply consistently.
A practical beginner workflow is to start with a small set of classes, such as person, car, and bicycle, rather than twenty categories at once. This makes annotation faster and quality control easier. Once the first model works reasonably well, you can expand. The key lesson is simple: examples are how the model learns, and labels are how you explain those examples to the model in a structured way.
Annotating means marking the objects in each image so the model can learn from them. In object detection, the most common annotation is a bounding box: a rectangle drawn around an object. Each box is paired with a label such as dog or traffic light. During training, the model compares its predicted boxes and labels with these human-created annotations and gradually improves.
Boxes matter because detection is about location as well as identity. A photo may contain five objects of the same type, and the model needs to find each one separately. A good box is usually tight enough to include the full object while avoiding too much empty background. If boxes are loose and inconsistent, the model learns sloppy localization. If boxes cut off important parts of the object, the model learns incomplete visual patterns.
Beginner tools often let you draw boxes by clicking and dragging on an image. While this seems simple, consistency is the real challenge. Decide early how to handle partial objects at the image edge, reflections, tiny distant items, or heavily occluded objects. If one image includes a tiny person and another similar tiny person is ignored, the model gets conflicting signals. That makes training harder and evaluation less reliable.
When you read a model’s output later, you will usually see three things together: a box, a label, and a confidence score. For example, a detector might produce person, 0.88 with a box around a pedestrian. The confidence score is not a guarantee that the answer is correct; it is the model’s estimated certainty based on what it learned. Practical outcome: when checking results, do not focus only on whether the label is right. Also ask whether the box is placed correctly and whether confidence looks sensible for easy versus difficult examples.
The basic process of machine learning has three parts: training, validation, and testing. During training, the model sees many labeled images and adjusts itself to reduce prediction errors. During validation, you check performance on a separate set of images the model did not train on directly. This helps you tune settings and notice problems such as overfitting. Finally, testing gives a final, more honest measurement of performance on data kept aside until the end.
Why not use the same images for everything? Because a model can memorize training examples. If you ask it to predict on the exact same images, the results may look excellent even if it cannot generalize to new photos. Validation and test sets answer the important real-world question: can the model handle unseen images and video frames?
For a beginner project, a practical split might be something like 70% training, 15% validation, and 15% testing. The exact numbers can vary, but the principle should not. Keep similar near-duplicate images together when possible. For example, if you extracted many frames from one short video, do not scatter almost identical frames across training and test sets. That makes the test too easy and gives a false sense of quality.
During training, you may notice the model improving on the training set while validation performance stops improving or gets worse. That often means overfitting: the model is becoming too specialized to the training images. Practical actions include gathering more diverse examples, simplifying the task, improving annotation quality, or using different training settings in a beginner-friendly tool. The big lesson is that training teaches, validation guides, and testing verifies. Each plays a different role in building trust in your detector.
Beginners often hear that AI needs lots of data, and that is partly true. But more data is not automatically better. If you add thousands of poor-quality images, wrong labels, or inconsistent boxes, you may make the model worse rather than better. Quality, diversity, and relevance matter more than raw file count, especially in early projects.
Imagine you want to detect mugs on a desk. You could collect 10,000 nearly identical images of the same mug from the same angle and under the same lighting. That sounds impressive, but it teaches a narrow lesson. A smaller dataset with different mugs, backgrounds, camera distances, desk types, and lighting conditions may perform better in practice. The goal is not to flood the model with repetition. The goal is to show the visual range of the real task.
Good engineering judgment means asking whether each new batch of images adds useful information. Does it introduce new object sizes, harder scenes, or realistic clutter? Or is it just more copies of what the model already knows? Relevance is equally important. If your target environment is a factory floor, random internet photos may not help much unless they resemble the factory setting.
A strong beginner strategy is to train with a modest but clean dataset, inspect the model’s mistakes, and then collect targeted new data to fix those weak points. That feedback loop is usually more effective than blindly adding thousands of images. Better data teaches better lessons.
Most early object detection problems come from data collection rather than model code. One common mistake is collecting images that are too easy. If every object is centered, large, well-lit, and fully visible, the model may fail in real scenes where objects are small, partly hidden, or surrounded by clutter. Include some easy examples, but also include realistic difficult ones.
Another frequent mistake is inconsistent annotation. For example, one annotator draws boxes tightly around bottles, while another includes large areas of background. Or some small objects are labeled while others are ignored. Inconsistency confuses the model because the target keeps changing. Create simple annotation rules and follow them every time. Consistency is more important than perfection.
Beginners also often mix classes in unclear ways. Suppose a dataset uses phone, mobile, and smartphone as separate labels without good reason. That fragments the learning task and reduces useful training signal. Keep your taxonomy simple. Another trap is data leakage, where nearly identical images appear in both training and test sets. This can make the detector seem much stronger than it really is.
Finally, many people forget to review failed predictions. Beginner-friendly tools make it easy to run a model, but the real learning comes from inspecting mistakes. Are missed objects tiny? Are false detections happening on shiny surfaces? Are confidence scores too high for wrong predictions? These observations tell you what data to collect next. Practical outcome: treat the dataset as a product you improve over time, not as a one-time download. Careful collection, clean labels, and honest evaluation are the foundation of object detection success.
1. What is the simplest way to describe how an object detection model learns?
2. How is object detection different from basic image classification?
3. Why are labels and bounding boxes important in training data?
4. What is the main purpose of validation and test data?
5. According to the chapter, which choice usually leads to better beginner results?
In the last chapter, you learned how an object detection model looks at an image and tries to find meaningful things inside it. Now we move to the part that beginners often find confusing at first: reading the output. When a model finishes its work, it does not speak in plain English. It gives you a set of results that usually include a label, a box around the object, and a confidence score. If you can read those three pieces clearly, you can already make useful decisions about whether the system is working well enough for your task.
Think of detection results as the model saying, “I think there is a bicycle here,” while pointing to a location in the image and adding, “I am 87% confident.” That is very different from saying the model is certain. AI systems do not truly know things the way people do. They estimate patterns based on what they learned from training data. This is why reading results is not just about seeing boxes on a photo. It is about learning to interpret uncertainty, noticing when the model is making weak guesses, and deciding whether those guesses are acceptable in real use.
As a beginner, your goal is not to memorize advanced math. Your goal is to build judgment. You want to look at a detection result and ask practical questions: Is the box in the right place? Is the label sensible? Is the confidence high enough to trust? Did the model miss something obvious? Did it detect something that is not really there? These questions matter whether you are detecting pets in family photos, products on shelves, cars on a road, or helmets on workers.
A good workflow is simple. First, look at the image with the model’s detections drawn on it. Second, compare each detection with what a person would naturally say is in the image. Third, pay attention to confidence scores rather than treating every box as equally reliable. Fourth, review patterns across many images instead of judging the model from just one lucky example. A model can look impressive on one image and still fail often in normal use.
In this chapter, you will learn how to interpret outputs without technical jargon, how to read confidence scores and understand uncertainty, how to spot false positives and missed detections, and how to judge whether a model is useful for a task. These are the skills that turn raw model output into practical understanding.
By the end of this chapter, you should be able to open a beginner-friendly detection tool, run a model on a few images, and explain in plain language what the model did well, what it did poorly, and whether it is good enough for the job you care about.
Practice note for Interpret model outputs without technical jargon: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Read confidence scores and understand uncertainty: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Spot false positives and missed detections: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Most object detection tools show results in a very similar way. You will usually see a rectangle drawn around part of the image, a text label such as person or dog, and a number such as 0.92 or 92%. These are the basic building blocks of model output. If you understand them, you can interpret almost any beginner-level detection result.
The label is the model’s best guess about what the object is. The box, often called a bounding box, marks where the model believes the object is located. The confidence score tells you how strongly the model believes that the label and box are correct. These three parts should always be read together. A correct label with a badly placed box is still a poor detection. A perfectly placed box with a low confidence score is not something you should trust without caution.
Imagine a photo of a street. The model draws one box around a car and shows car: 0.96. That likely means the model is seeing a clear example. If it shows car: 0.41 on a blurry shape in the distance, that is a much weaker result. Beginners often make the mistake of treating both boxes as equal just because both appear on the screen. In practice, they are not equal at all.
When reading outputs, ask these practical questions:
Confidence thresholds matter here. Many tools let you hide detections below a chosen score, such as 0.5. Raising the threshold usually removes weak guesses, which can reduce clutter and false alarms. Lowering it can reveal more possible objects, but also more mistakes. There is no universal perfect setting. A wildlife hobby project may accept lower-confidence detections because missing an animal is worse than reviewing a few extra boxes. A safety system may need stricter rules.
The key idea is simple: labels tell you what, boxes tell you where, and confidence gives you a clue about how certain the model is. Learning to read them together is the first step toward real evaluation.
AI models are often unsure, even when their output looks neat and polished. This is normal. A model becomes unsure when the visual evidence in the image is weak, confusing, incomplete, or unlike the examples it learned from during training. In beginner-friendly terms, uncertainty means the model sees something that partly looks familiar, but not clearly enough to make a strong decision.
For example, suppose a cat is partly hidden behind a chair. A person can still infer that it is a cat from context, shape, and experience. A model may detect only part of the body and produce a low confidence score, or it may fail to detect the cat entirely. The same thing happens with shadows, reflections, unusual poses, crowded scenes, motion blur, and low-resolution objects.
Low confidence does not always mean the detection is wrong. It means the model is less certain. Sometimes a 0.48 result is actually correct, especially in difficult images. Other times a 0.78 result is still wrong because the model has learned a misleading pattern. That is why confidence scores are helpful signals, not guarantees.
A practical way to work with uncertainty is to review results in bands:
When beginners see uncertain outputs, they sometimes assume the model is broken. A better response is to ask why the model is unsure. Is the object too small? Is the image dark? Is the view unusual? Is there another object nearby causing confusion? These questions help you connect uncertainty to image conditions rather than treating the score as mysterious.
In real projects, uncertainty can guide action. You might automatically accept high-confidence detections, send medium-confidence ones for human review, and ignore very low-confidence ones. This is a common engineering pattern because it balances speed with caution. The practical lesson is that uncertainty is not a flaw to hide. It is part of the model’s output, and reading it well helps you use the system more safely and effectively.
Once you start reviewing detection results, you will see two major kinds of mistakes. A false positive happens when the model says an object is present, but it is not really there. A false negative, often called a miss, happens when the object is truly there, but the model fails to detect it. These two error types matter because they affect usefulness in different ways.
Imagine a parking lot camera. If the model marks a shadow as a car, that is a false positive. If it fails to detect an actual car parked in the corner, that is a false negative. Both are errors, but they create different problems. False positives create extra alerts, wasted time, and annoyance. False negatives can be more serious when missing an object has consequences, such as missing a helmet, a person, or a damaged product.
Beginners often focus only on visible boxes and forget to check for missing detections. This creates a biased impression because you notice what the model found, but not what it ignored. A better habit is to inspect the image manually and count both sides: what should have been detected and what actually was detected.
Common causes of false positives include confusing backgrounds, similar-looking objects, logos, reflections, and patterns the model has overlearned. Common causes of misses include tiny objects, occlusion, blur, poor lighting, and unusual viewpoints. Sometimes the model detects the right object class but places the box so badly that it is not very useful. In practice, that also counts as a detection quality problem.
To review errors practically, create a simple checklist for each image:
This kind of review quickly reveals whether a model is merely impressive-looking or genuinely useful. A tool that draws many boxes may feel smart, but if too many are false alarms, it may not help your workflow. Likewise, a model that is very cautious may look clean, yet still miss too many real objects. Your job is to judge both kinds of failure, not just admire the interface.
Precision and recall are standard ideas in AI evaluation, but you can understand them without heavy math. Precision asks: when the model says it found something, how often is it right? Recall asks: out of all the real objects that were present, how many did the model successfully find? These two ideas help you judge whether the model is useful for your task.
Suppose a model reports 10 bicycle detections in a set of images, and 8 of them are truly bicycles. That suggests decent precision, because most reported detections were correct. Now imagine there were actually 20 bicycles across those images, but the model found only 8 of them. That means recall is not very high, because many real bicycles were missed.
These measures often pull in opposite directions. If you set a high confidence threshold, the model may report fewer detections, but the ones it keeps are more likely to be correct. Precision may improve, while recall drops because more real objects are filtered out. If you lower the threshold, recall may improve because more real objects are included, but precision may fall because weak false positives also appear.
For beginners, the practical question is not “What is the perfect precision or recall value?” The practical question is “What balance is acceptable for my use case?” A toy app that labels pets in home photos can tolerate some mistakes. A warehouse counting system may need fewer misses. A safety-related application may require strict review and stronger performance before use.
Use precision and recall as thinking tools:
Even if your software does not display precision and recall directly, the ideas still help. They teach you to separate two questions: “Are the reported detections trustworthy?” and “Is the model finding enough of what matters?” That distinction is one of the most important habits in reading detection results intelligently.
Object detection models do not see images the way people do. Humans are surprisingly good at recognizing familiar objects even in poor conditions. Models are much more sensitive to changes in appearance. This is why image conditions matter so much when reading results. If a model works well on clear, bright images and poorly on dark or unusual ones, that is not random. It usually reflects what kinds of examples it learned from and what visual clues it depends on.
Lighting is one of the biggest factors. In dim scenes, objects lose detail, colors shift, and shadows can look like real shapes. A model that detects a red apple in a bright kitchen may struggle with the same apple in evening light. Angle matters too. If the training images mostly showed cars from the side, the model may be weaker on top-down or partially blocked views. Size is another major issue. Large objects occupy more pixels, so they provide more visual evidence. Tiny objects far away often produce low confidence or get missed altogether.
Background clutter also changes performance. A cup on a clean table is easier to detect than a cup in a crowded cupboard. Motion blur can reduce clarity in video frames. Reflections in glass can create false positives. Rain, fog, and compression artifacts can all reduce reliability.
As a practitioner, do not evaluate a model only on ideal images. Test across realistic conditions:
This kind of testing gives you an honest picture of where the model is dependable. It also helps explain output patterns. If small objects are often missed, you should not be surprised when confidence scores are low in distant scenes. If side views work but angled views fail, that tells you where the model’s weak spots are. Good evaluation is not just looking at results; it is connecting those results to the conditions that produced them.
A real practitioner does not judge a model by one screenshot. They review many examples, record patterns, and decide whether the model is useful for a specific job. This mindset is one of the biggest differences between casual experimentation and practical AI work. Your goal is not to ask, “Does the model ever work?” but “Does it work reliably enough, under realistic conditions, for my task?”
Start with a small review set of images or video frames. Make sure they reflect real use, not only your best-looking examples. Run the model and examine every result. For each image, note the correct detections, false positives, missed objects, confidence levels, and any obvious reasons for failure such as darkness or occlusion. A simple spreadsheet is enough. You do not need advanced tools to begin thinking professionally.
Next, look for patterns instead of isolated mistakes. If the same class is often confused with another, that is a pattern. If low-light scenes consistently produce misses, that is a pattern. If confidence is high when objects are centered and low when they are small or tilted, that is a pattern too. Patterns lead to better decisions than emotional reactions to one bad example.
Then ask the most important engineering question: is this model useful enough? Useful does not mean perfect. It means the errors are manageable for the task. A model might be useful if it saves review time, helps narrow down frames to inspect, or performs well enough when paired with human checking. Another model might be unusable if false alarms are constant or if critical objects are regularly missed.
A practical review workflow looks like this:
This is how confidence becomes action. Instead of treating model output as magic, you learn to read it, question it, and judge it. That skill will help you use beginner-friendly detection tools wisely and prepare you for more advanced model testing later in the course.
1. When reading an object detection result, which three parts should be understood together?
2. What does a low confidence score usually suggest?
3. Which situation is an example of a false positive?
4. According to the chapter, what is a better way to judge whether a model is useful?
5. Which question best shows practical judgment when evaluating a detection result?
In the previous chapter, you learned the basic idea behind object detection: the computer does not simply say what is in an image, it also points to where each object appears. In this chapter, we move from idea to action. You will walk through a simple image detection workflow from start to finish, using beginner-friendly tools and everyday photo files. The goal is not to become a machine learning engineer in one sitting. The goal is to learn how a practical detection task works, what kind of image data helps, and how to read the output with confidence.
A beginner object detection workflow usually follows a clear sequence. First, choose a tool that already has a ready-made model. Second, gather a small collection of photos. Third, run the detector on those images. Fourth, inspect the output: labels, bounding boxes, and confidence scores. Finally, improve the inputs and test again. That pattern appears again and again in real projects, whether the task is detecting fruit on a kitchen table, cars in a parking lot, or packages on a warehouse shelf.
One useful habit is to think like both a user and a builder. As a user, you ask: did the tool find the object I care about? As a builder, you ask: what about the image made detection easy or difficult? Those two viewpoints help you build engineering judgment. Strong results do not come only from better AI models. They often come from clearer photos, better organization, and realistic expectations about what the model can recognize.
When you read an object detection result, focus on three parts. The label tells you what the model believes the object is, such as person, dog, bottle, or car. The bounding box shows where the object is located in the image. The confidence score estimates how sure the model is, often as a decimal or percentage. A box labeled dog 0.93 means the model is very confident it has found a dog. A box labeled chair 0.41 is more uncertain and may deserve a closer look.
As you work through this chapter, keep an important beginner rule in mind: object detection is not magic. It is pattern recognition based on visual examples. Good lighting, clear objects, and sensible image framing often improve results more than beginners expect. Poor lighting, clutter, blur, and tiny objects can quickly reduce quality. That is why preparing photos is part of the job, not a side detail.
By the end of this chapter, you should be able to choose a beginner-friendly detection tool, prepare simple image data for a project, run a ready-made detector on still images, and review the results in a practical way. Just as importantly, you will learn how to improve weak results without guessing. That skill matters in every computer vision project.
This chapter focuses on still photos because they are easier to inspect than video. However, the same logic applies to video frames. A video is simply a sequence of images. If a model can detect an object in a clear photo, it may also detect it in a video frame, as long as motion blur, low light, and camera angle do not get in the way. Learning with photos gives you a clean foundation before moving to more complex live detection tasks later.
As you read each section, think practically. Imagine you are helping a friend build a tiny detector demo using objects on a desk or in a room. What tool would you choose? How would you name folders? What photos would you keep or discard? Those decisions are the real work of beginner computer vision, and they turn abstract concepts into usable skills.
Your first detection project should begin with a ready-made tool, not with training a model from scratch. A beginner-friendly detection tool already knows many common object categories and lets you test images with minimal setup. This lowers the barrier and helps you focus on the workflow: input image, detector output, and result review. Many tools are available as web demos, notebook examples, desktop apps, or simple Python packages. The best choice is the one that lets you load an image and see bounding boxes quickly.
When comparing tools, look for four practical features. First, the tool should support common labels such as person, car, dog, bottle, chair, and phone. Second, it should clearly display bounding boxes and confidence scores. Third, it should accept standard image formats like JPG and PNG. Fourth, it should be easy to run again and again as you test different photos. If a tool is hard to install or hides its results, it may teach you less than a simpler option.
Engineering judgment matters here. A tool can be technically powerful but still be a poor fit for a beginner. For example, a command-line library with many settings may be excellent for experts, yet confusing for a first project. A web interface or notebook may be slower, but it helps you see the connection between the photo and the detection result. Early on, visibility is more important than speed.
A common mistake is choosing a detector for the wrong object set. If your model only knows everyday categories, it will not reliably detect custom items like your own brand of cereal box or a specific school logo. Another mistake is trusting labels too quickly. If the model labels a mug as a bowl or a backpack as a suitcase, that does not always mean the software is broken. It may mean the object is partly hidden, oddly shaped, or visually similar to a different category.
For a first project, choose one tool and stick with it for several tests. Avoid jumping between many tools after one weak result. Consistency helps you learn what changes are caused by the image itself and what changes come from the software. In short, the right beginner tool is one that is simple, visual, repeatable, and trained on the kinds of objects you want to explore.
Before running detection, prepare your photos carefully. This may feel basic, but file organization is one of the most useful skills in any AI workflow. A messy folder of random screenshots, duplicates, and badly named images makes learning harder. A clean folder helps you test ideas quickly and compare results fairly. For a beginner project, create one main folder for the chapter, then add subfolders such as raw_photos, test_images, and results.
Use simple file names that tell you what the image contains. For example, kitchen_table_01.jpg, living_room_chair_02.jpg, or desk_objects_03.png. Good names make it easier to remember what you tested and what happened. If your detector misses the bottle in one image but detects it in another, clear names help you compare them without confusion.
As you collect photos, aim for variety, but not chaos. Include different angles, lighting conditions, distances, and backgrounds. At the same time, keep the task realistic. If your goal is detecting everyday objects, do not fill the folder with artistic filters, extreme close-ups, or images where the target object is barely visible. Start with clear examples, then gradually add harder cases.
There are also practical quality checks to apply. Make sure the object is not too small in the frame. Avoid images that are heavily blurred or underexposed. Watch for cut-off objects at the edge of the image, especially if the important object is only partly visible. Those images are not useless, but they can be harder for a ready-made detector and may lead to confusing results for a beginner.
A common mistake is mixing unrelated purposes in one folder. If some images are for object detection practice and others are personal downloads or unrelated screenshots, your workflow becomes harder to track. Another mistake is constantly overwriting files or saving edited copies with unclear names like final2_realfinal.jpg. Treat image data like project material. Small acts of organization save a great deal of time later.
By preparing your photo files well, you create a fair test environment for the detector. That means your next results will teach you something useful. If the model succeeds, you can see why. If it fails, you can inspect whether the problem came from the object, the photo quality, or the model’s limitations.
Now it is time to run the detector. The exact button names or commands will depend on the tool you chose, but the workflow is usually similar. Open the tool, upload or select one image, run inference, and wait for the output. The tool then returns the original image with bounding boxes drawn around detected objects. Beside or above each box, you usually see the predicted label and a confidence score.
As you review the output, slow down and inspect it carefully. Start with the largest and clearest objects. Are the boxes placed tightly around the correct items? Do the labels match what a person would call those objects? Are the confidence scores high on easy examples and lower on harder ones? This visual review is important because a result can look impressive at first glance while still containing subtle errors.
Suppose your photo contains a laptop, mug, book, and backpack. A typical detector might find all four objects, miss one of them, or confuse one category with another. If the detector labels the mug correctly with a confidence of 0.91, that is a strong result. If it labels the book as a laptop at 0.38, that lower score suggests uncertainty. Confidence is not a guarantee of truth, but it helps you decide which results deserve trust and which deserve caution.
This is also where you begin to build practical intuition about thresholds. Some tools let you hide detections below a chosen confidence level, such as 0.5. A lower threshold shows more boxes, including more possible false positives. A higher threshold shows fewer boxes, but may hide real objects that were detected with only moderate confidence. Beginners often either trust every box or reject every uncertain result. A better habit is to treat confidence as a clue, not a verdict.
Common mistakes include testing only one perfect image and assuming the model is excellent, or testing one difficult image and assuming it is useless. Run the same tool on several photos of the same object type. Compare what changes when the angle, lighting, or background changes. This simple repetition teaches more than a single dramatic example.
Running detection on still images is the heart of the workflow. It turns theory into something visible. Once you can load a photo, get a result, and explain what the labels, boxes, and confidence scores mean, you have crossed an important beginner milestone in object detection.
One of the fastest ways to improve at object detection is to compare strong image inputs with weak ones. A good image input usually has clear lighting, a visible object, reasonable contrast, and enough object size in the frame. A bad image input often suffers from blur, darkness, glare, extreme angle, clutter, or very small target objects. Looking at these differences helps you understand why the same detector performs well on one image and poorly on another.
Imagine two photos of a bottle. In the first photo, the bottle is upright on a table in daylight, centered in the frame, and not blocked by other items. In the second photo, the bottle is partly hidden behind a bag, photographed in dim light, and cut off near the edge. A ready-made detector is much more likely to detect the bottle in the first image. This is not because the tool suddenly became smarter. It is because the visual evidence is stronger.
Background also matters. Busy scenes with many overlapping objects can confuse a beginner detector, especially if multiple categories look similar. A shoe near a backpack, a cup near a bowl, or a monitor near a TV may trigger uncertain predictions. Reflection and transparency can be difficult too. Glass, mirrors, and shiny packaging may distort object appearance enough to reduce confidence.
Do not think of bad image inputs as worthless. They are valuable teaching material. They show the boundaries of what your detector can handle. In real projects, not every image will be perfect. Cameras shake, lighting changes, and objects move. By comparing good and bad inputs side by side, you learn to predict failure cases before the model runs.
A common beginner mistake is blaming the model for every error. Sometimes the model does fail. But often the image itself gives the model very little to work with. Another mistake is using only extremely clean examples and then being surprised when real-world photos perform worse. A balanced project includes easy images for understanding the basics and harder images for realistic evaluation.
The practical outcome of this comparison is simple: if you want better results, improve the evidence in the image whenever possible. Move closer, reduce clutter, increase lighting, hold the camera steady, and make sure the target object is visible. These simple changes often matter more than beginners expect.
Once you have reviewed your first detection outputs, the next step is improvement. For beginners, the easiest improvement method is not model retraining. It is better example selection. In other words, give the detector clearer, more useful photos. This is an important engineering lesson: before changing the system, improve the inputs. Many weak results come from weak examples rather than from impossible technical limitations.
Start by sorting your tested images into three groups: strong results, mixed results, and poor results. Then ask why each image landed in that group. Did the strong images have larger objects, simpler backgrounds, and better lighting? Did the poor images include blur, shadows, or partial occlusion? This review gives you a practical checklist for collecting better examples next time.
Next, create a second pass of images with deliberate improvements. If the object was too small, step closer. If the background was distracting, move the object to a cleaner area. If the scene was dark, add natural light or use a brighter room. If the detector struggled with side angles, include more front-facing views. These are not advanced machine learning tricks. They are basic data-quality improvements, and they work.
You can also improve by increasing the variety of good examples. For example, if your tool detects bottles well on a white table but struggles in a kitchen, test several bottle photos in different normal settings. This helps you understand whether the model is genuinely robust or only successful in one narrow condition. Variety should expand gradually, not randomly.
A common mistake is changing too many variables at once. If you move the object, change the lighting, switch the camera, and use a different tool all in one step, you will not know what caused the improvement. Change one or two things at a time and compare results. Another mistake is keeping every image forever. Curating your set matters. Remove duplicates and extremely poor images if they do not help you learn.
Improving results with better examples teaches an idea that will stay useful beyond this chapter: AI systems depend heavily on input quality. If you can recognize what makes an example helpful or harmful, you are already thinking like a computer vision practitioner, even at a beginner level.
To bring the chapter together, finish with a small practical project. Choose three to five everyday object categories that a ready-made detector is likely to recognize, such as bottle, chair, backpack, book, phone, cup, or laptop. Then collect around 12 to 20 photos using your phone or existing images. Keep the project simple. The purpose is to practice the full workflow, not to produce a research dataset.
Set up a folder structure for the project. Place original images in raw_photos, chosen test images in test_images, and saved outputs in results. Run your detection tool on each test image and save the visual outputs if possible. For every image, note three things: which objects were correctly detected, which were missed, and whether any false detections appeared. Also note the confidence of the most important box.
After running the full set, review the pattern of outcomes. Perhaps chairs were found reliably, but phones were often missed because they appeared too small. Perhaps bottles were detected in daylight but not in dim indoor images. This comparison is the heart of the mini project. You are not just collecting outputs. You are learning how image conditions shape detector behavior.
Now improve the project by replacing a few weak images with better examples. Retest and compare. Did confidence scores rise? Did previously missed objects become visible to the model? If yes, you have demonstrated an important beginner result: image preparation and thoughtful testing can improve practical detection outcomes even without changing the model itself.
Keep your summary short and concrete. State which object categories worked best, which conditions caused failures, and what image changes helped. This kind of reflection is what turns a software demo into a learning exercise. It shows that you understand not only how to click a button, but how to interpret and improve the system.
By completing this mini project, you will have used beginner-friendly tools to test an object detection model, prepared simple image data, read bounding boxes and confidence scores, and reviewed the strengths and weaknesses of your results. That is a strong foundation for moving from still photos toward more advanced detection tasks in later chapters.
1. What is the main goal of Chapter 4?
2. Which sequence best matches the beginner object detection workflow described in the chapter?
3. When reading an object detection result, what do the label, bounding box, and confidence score tell you?
4. According to the chapter, which change is most likely to improve weak detection results for a beginner project?
5. Why does the chapter focus on still photos before video?
So far, object detection may have felt most natural on single photos: one image goes in, and the model returns boxes, labels, and confidence scores. Video detection builds directly on that idea, but adds an important twist: instead of working on one still image, the computer processes many images in rapid sequence. A video is essentially a stream of frames, and each frame can be treated like a photo. This makes video detection easier to understand than it first appears. If you already know how detection works on one image, you already know the core idea behind detection in video.
However, video also introduces new challenges that do not appear as strongly in single-image detection. Objects move. Cameras shake. Lighting changes from one moment to the next. A person may be clear in one frame, blurry in the next, and partly hidden a moment later. In a single image, the model has only one chance to make a decision. In video, it makes many decisions over time, and those decisions should feel stable enough for a human viewer to trust. This is why video detection is not only about recognizing objects, but also about handling change.
For beginners, the most useful mental model is simple: the detector looks at each frame, predicts what objects are present, places bounding boxes around them, and assigns confidence scores. Then the system repeats this process for the next frame, and the next, and the next. If the results are displayed quickly enough, the boxes appear to move along with the objects. This gives the impression of "live" understanding, even though the computer is really performing a long series of image detections.
That frame-by-frame idea connects directly to engineering judgment. A practical system must balance speed and accuracy. If you process every frame at very high quality, the model may be too slow for real-time use. If you skip too many frames or use a very small image size, the system may miss important details. In real projects, there is often no perfect setting. You choose what matters most: smoother playback, lower delay, or stronger detection accuracy. Even at a beginner level, it is helpful to understand that video detection is not just a model problem. It is also a workflow problem.
Compared with image detection, video detection also gives you more evidence to work with. If the model misses a bicycle in one frame but finds it clearly in the next three, a person reviewing the output can still tell that the bicycle was present. This means video can sometimes be more forgiving than still images. At the same time, repeated mistakes become more visible. A box that flickers on and off across frames looks unreliable, even if each single-frame prediction seemed reasonable by itself.
In this chapter, you will learn how video is processed frame by frame, how object detection changes when scenes and objects are moving, and how to build a simple workflow for testing a detector on a short clip. You will also see why reviewing the output carefully matters just as much as running the model. The goal is not to master advanced tracking systems yet, but to become comfortable with the practical logic of spotting objects in video and judging whether the results are useful.
As you read, keep connecting each idea back to the course outcomes. When a model labels a moving car with a box and a confidence score in frame after frame, you are seeing object detection in plain language. When you compare that to simple image classification, you can see why detection is more informative: it tells you not only what is present, but also where it is. Video simply repeats that process over time. Once that clicks, the rest of the chapter becomes much easier to follow.
A video may look like continuous motion, but for a computer it is usually a sequence of still images called frames. If a video runs at 30 frames per second, that means the system receives 30 separate images every second. This idea is the foundation of video object detection. Instead of inventing a completely new method for video, many beginner-friendly tools simply run an image detector on one frame after another. The detector does not need to understand the full movie all at once. It can begin by understanding each frame as if it were a photo.
This is an important concept because it removes a lot of mystery. If you know how a model reads a photo, predicts bounding boxes, assigns labels like person or car, and gives confidence scores, then you already understand most of what happens in video detection. The main difference is repetition over time. One frame might show a dog on the left side of the scene, and the next frame shows the dog slightly farther right. The detector repeats its job, and the boxes update.
There are practical consequences to this frame-based view. First, more frames mean more computation. A 10-second clip at 30 frames per second contains 300 frames. Running detection on all 300 frames can take time, especially on slower hardware. Second, not every project needs every frame. In some beginner experiments, processing every second frame or every third frame can be a reasonable shortcut. This can make the system faster, though it may miss very quick motion.
Another useful point is that frames are often compressed, resized, and converted before the model sees them. If the frame is reduced too much, small objects may disappear. If the video quality is poor, the detector has less detail to work with. Good engineering judgment starts here: understand the input before blaming the model. Many detection problems in video are partly data-quality problems.
A common beginner mistake is to think of video as something fundamentally different from images. In reality, the frame-by-frame mindset is the correct starting point. Once you are comfortable with that, you can build a simple and reliable workflow: extract or read frames, run a detector, draw predictions, and save or display the updated frames as video output.
When detecting objects in video, the simplest workflow is straightforward: read a frame, send it to the model, receive predictions, draw the boxes and labels, then move to the next frame. This cycle repeats until the video ends. For a beginner, this is the most important workflow to understand because it turns object detection into a practical process rather than an abstract concept.
Each prediction usually contains three main parts you already know from image detection: a bounding box, a class label, and a confidence score. In a video of a street, one frame might produce boxes labeled car, bicycle, and person. The next frame might produce similar boxes in slightly different positions. If the confidence score for a person falls from 0.92 to 0.58, that tells you the model is becoming less sure, perhaps because the person is farther away or partly hidden.
This is also where the difference between image detection and video detection becomes clearer. In a single image, one weak prediction may still be acceptable because the user can inspect it manually. In video, a weak prediction repeated across many frames becomes distracting. You may see boxes flicker, labels switch, or confidence scores jump up and down. These effects do not always mean the model is broken. They often mean the scene is difficult or the model is operating near its limits.
Confidence thresholds matter a lot here. If the threshold is too low, the system may show many false positives, such as boxes on background shapes that only briefly resemble real objects. If the threshold is too high, the detector may miss real objects whenever the view becomes harder. A practical beginner approach is to test a few threshold settings and compare the output visually. Choose a setting that reduces obvious mistakes without hiding too many real detections.
A good frame-by-frame workflow often includes these steps:
The key practical lesson is that video detection is not only about whether a model can detect an object once. It is about whether the detections remain useful over time. That makes reviewing the full output essential.
Video becomes more challenging than still-image detection because the scene can change from frame to frame. Objects move, the camera may pan or shake, and the background itself might not stay still. A parked car in a photo is often easier to detect than a fast-moving car in a video taken from a moving camera. This is one of the biggest practical differences between image detection and video detection.
Motion blur is a common source of trouble. When an object or the camera moves quickly, the image can smear across the frame. To a human, the object may still be recognizable. To the model, important edges and textures may become unclear. This can lower confidence scores or cause missed detections. Small objects are especially vulnerable because they already contain limited detail.
Changing backgrounds create another challenge. Imagine detecting a person walking indoors, then passing a window with bright sunlight, then moving into shadow. The model sees different contrast, different brightness, and possibly reflections. In a single image task, you only need one good prediction. In video, the appearance may shift many times in a few seconds. This means a detector that works well on clean sample images can behave less consistently on real footage.
Occlusion also matters. An object may be partly hidden behind another object for a few frames. A bicycle behind a pedestrian might be visible enough in one frame, almost invisible in the next, and visible again after that. Beginners often assume this means the model failed randomly. In fact, the detector is reacting to incomplete visual evidence, which is expected.
Good engineering judgment means learning to ask practical questions: Is the video resolution high enough? Is the object too small for the chosen model input size? Is the camera motion too strong? Is poor lighting reducing contrast? These questions help you decide whether to improve the data, adjust settings, or accept that the scene is difficult.
A common mistake is to judge a detector only on easy clips. Always test on realistic video with movement, blur, and changing backgrounds. That is where the difference between a nice demo and a useful workflow becomes obvious.
Once you detect objects frame by frame, the next natural idea is to keep track of which object is which over time. This is called tracking. A full tracking system can be advanced, but the beginner concept is simple: if a box in the current frame looks like the same object as a box in the previous frame, the system can give it the same identity. That helps the output feel more stable and meaningful.
For example, suppose two people are walking across a scene. A detector can tell you that each frame contains person boxes. A tracker tries to maintain consistency, such as Person 1 and Person 2, across frames. Even if the exact box position changes slightly, the tracker helps connect detections over time. This is useful in practical applications because people often care not just about what is present, but also about how long it remains in view and where it moves.
At a beginner level, you do not need to build a complex tracker from scratch. What matters is understanding why tracking helps. Without it, the detector may produce boxes that flicker or briefly disappear. With a tracking layer, the system can often smooth those short interruptions. If an object is confidently detected in many nearby frames, tracking can help preserve continuity when one frame is uncertain.
Tracking is not magic, though. If two similar objects cross paths, identities can switch. If an object disappears for too long, the tracker may lose it. If the initial detections are poor, tracking has little to work with. That is why tracking should be viewed as a support system for detection, not a replacement for good detection.
From an engineering point of view, a useful beginner mindset is this: detection answers "what and where in this frame?" Tracking adds "which one is this over time?" You may not need tracking for a simple classroom demo, but it becomes valuable when you want stable video output, object counts, or movement summaries. Understanding this relationship prepares you for more advanced computer vision workflows later.
Running a model on a video is only half the job. The other half is reviewing the output carefully. Beginners often focus on whether the code runs, but a working script does not guarantee useful results. You should watch the processed video and inspect whether the boxes are accurate, stable, and readable. A detector that misses every tenth frame may still be acceptable in one use case and unacceptable in another. Context matters.
Start by checking basic visual quality. Are the boxes placed around the correct objects? Are labels easy to read? Do confidence scores look reasonable? Next, watch for temporal issues, meaning issues over time. Flickering boxes are one of the most common problems. This happens when detections appear in one frame, disappear in the next, and return again. Another common issue is box jitter, where a box jumps around even though the object moves smoothly.
False positives are also easier to notice in video. A single incorrect box in a photo may seem minor, but in a clip it can repeat for several seconds and become distracting. False negatives matter too. If a real object disappears whenever it turns sideways or moves quickly, the system may not be reliable enough for the task. Label switching can happen as well, especially when the model is unsure and alternates between related classes.
When you notice problems, avoid guessing blindly. Review the conditions around the mistake. Was the object far away? Was there blur, low light, or occlusion? Did the confidence threshold remove borderline detections? Did resizing the video make small objects too hard to see? This style of review builds strong practical habits.
Useful fixes may include:
The main lesson is that video output should be judged as a whole experience, not as isolated frames. A good workflow includes not just detection, but also thoughtful review and iteration.
To bring the chapter together, imagine a small beginner project: detect common objects in a 10- to 20-second video clip. Choose a simple scene first, such as a phone video of a street, a room with people walking, or a parking area with vehicles. Keep the clip short so you can review it carefully. The goal is not to build a perfect production system, but to practice a complete video detection workflow from input to output.
Start by selecting a beginner-friendly detection tool or notebook that can process video. Load the clip and note its frame rate and resolution. Then run the detector frame by frame. For each frame, draw bounding boxes, class labels, and confidence scores. Save the processed frames into a new output video. If your tool supports it, also log predictions so you can inspect them later.
As you test the clip, make practical observations. Which objects are detected consistently? Which ones are missed when they move quickly or become small? Do confidence scores drop when lighting changes? If a person walks behind a chair for a moment, does the detection recover quickly when the person becomes visible again? These observations are more valuable than simply saying the model worked or did not work.
A sensible mini-project workflow looks like this:
This project teaches several course outcomes at once. You see object detection in plain language, compare still-image detection with video behavior, read boxes and confidence scores in a moving scene, and use a beginner-friendly tool to test a real model. Just as importantly, you learn engineering judgment: useful AI work is not only about pressing run. It is about observing results, understanding limitations, and making simple improvements step by step.
By the end of this mini project, you should feel comfortable explaining how a model spots objects in video and why the process is really many image detections connected over time. That is a strong foundation for the more advanced workflows you will meet later.
1. What is the basic idea behind object detection in video?
2. Why is video detection often harder than detection on a single photo?
3. What happens when detection results are displayed quickly enough across frames?
4. What trade-off is important in a practical video detection system?
5. Which workflow best matches the beginner-friendly video detection process described in the chapter?
Up to this point, you have learned what object detection is, how it differs from image classification, how to read bounding boxes and confidence scores, and how to test beginner-friendly models. That foundation is enough to move beyond a one-time demo and begin thinking like a real builder. In practice, object detection becomes useful when it is attached to a clear purpose: counting products on shelves, spotting safety gear in a work area, detecting vehicles in a driveway camera feed, or identifying when objects enter a restricted zone. A model by itself is only one part of a system. Real value comes from the workflow around it.
This chapter helps you make that shift. Instead of asking, “Can the model detect objects?” you will start asking better questions: “What problem am I trying to solve?” “What level of accuracy is good enough?” “Who could be affected if the model makes mistakes?” and “How do I present results in a useful way?” These are the questions that turn beginner experiments into practical projects.
A good beginner mindset is to keep the first real-world use case small, measurable, and low-risk. For example, detecting whether a package is present on a desk is a better first project than building a full autonomous surveillance system. A narrow problem gives you a better chance of collecting relevant images, testing performance honestly, and improving step by step. It also teaches engineering judgment: choosing constraints, knowing what to ignore at first, and deciding when a model is good enough for a simple task.
You should also expect limits. Object detection systems can fail because of poor lighting, unusual camera angles, partial occlusion, cluttered backgrounds, motion blur, reflections, or classes that look too similar. Confidence scores can look reassuring even when predictions are wrong. A model trained on one environment may perform poorly in another. That is why successful projects always include testing, error review, and a plan for what happens when the model is uncertain.
In this chapter, you will connect object detection to practical beginner projects, learn the basics of limits and ethical concerns, plan a simple end-to-end use case, and identify clear next steps for continued learning. Think of this as the bridge between understanding the tool and using it responsibly. If earlier chapters taught you how object detection works, this chapter shows you how to make it useful in the real world.
Practice note for Connect object detection to useful beginner projects: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand limits, risks, and ethical concerns: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Plan a simple end-to-end use case: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Choose clear next steps for continued learning: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Connect object detection to useful beginner projects: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand limits, risks, and ethical concerns: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Object detection becomes easier to understand when you attach it to concrete examples. In retail, a beginner-friendly project might detect bottles, cans, or boxes on a shelf. The goal is not to build a perfect commercial inventory system on day one. A realistic goal is to answer one simple question such as, “Is this shelf section empty?” or “How many visible product units are in this image?” Even this small use case teaches important ideas: class labels, overlapping objects, counting, and the challenge of different packaging designs.
In safety settings, object detection is often used to detect helmets, safety vests, vehicles, cones, or people entering a marked zone. A beginner project could use a static camera to detect whether a hard hat is visible in a defined workbench area. This is much simpler than trying to monitor a busy construction site. It also helps you learn an important engineering lesson: reduce variability. Fixed cameras, stable backgrounds, and one or two target classes make early projects much more manageable.
Smart cameras are another common application. A home or office camera might detect people, pets, packages, or cars. Here, object detection can trigger an event: save an image, send an alert, or count occurrences over time. For beginners, package detection near a front door or pet detection in a room can be excellent starter projects. These cases are easier to explain and test than abstract benchmark scores.
The practical lesson is that useful projects are usually narrow. They have a specific camera view, a small number of classes, and a clear action tied to the detection result. If you try to detect everything everywhere, you create too much complexity too soon. Start with one camera, one environment, and one decision the system should support. That is how a demo becomes a usable first application.
As soon as object detection touches real people or real spaces, responsibility matters. A technically interesting project can still be a bad idea if it invades privacy, treats groups unfairly, or creates harm through false confidence. Beginners do not need to become policy experts, but they do need a basic habit of asking who is affected and what could go wrong.
Privacy is often the first concern. If your system uses cameras in homes, schools, offices, or public-facing areas, you should think carefully about consent, storage, and access. Do you really need to save video, or can you process frames locally and keep only counts or alerts? Can you crop the image to focus only on relevant objects and avoid capturing unnecessary personal details? Simple design choices can reduce risk before the model even runs.
Bias appears when a model performs better in some conditions than others. A detector trained mostly on bright, clean images may fail in darker environments. A safety detector trained with one helmet color may miss others. A person detector may work differently across body sizes, clothing styles, or mobility aids if the training data is not diverse enough. The key beginner lesson is this: model performance depends on data. If your examples are narrow, your system will likely be narrow too.
Responsible AI also means planning for mistakes. False positives can create annoyance and wasted effort. False negatives can be more serious because they miss important events. In a safety context, missing a helmet matters more than wrongly flagging one image for review. That means the threshold you choose and the fallback process you design should match the risk level.
Responsible use is not an extra step added at the end. It is part of problem selection, data collection, testing, and deployment. If you build this habit now, your future computer vision projects will be more trustworthy and more useful.
One of the biggest beginner mistakes is choosing a problem that is too broad. “Detect all important objects in my environment” sounds exciting, but it is difficult to define, difficult to test, and difficult to improve. A better problem is narrow, observable, and tied to a decision. For example: “Detect whether a package is on the porch mat,” “Count apples on a table,” or “Detect whether a helmet is visible at a station entrance.”
To pick the right problem, start with the output you actually need. Do you need a class label, a count, an alert, or a visual annotation on an image? If your real need is just a count, you may not need a complex multi-class system. If your real need is a simple warning, one object class in a fixed scene may be enough. This is good engineering judgment: solving the actual problem rather than the most technically impressive version of it.
Next, check whether the scene is stable. Fixed camera angles are much easier than moving cameras. Indoor lighting is usually easier than outdoor weather changes. Fewer object classes are easier than many. Large, visually distinct objects are easier than tiny, overlapping ones. If two possible projects seem equally interesting, choose the one with less variation. You will learn faster.
You should also define success early. How accurate does the system need to be? What kinds of mistakes are acceptable? How often will images be captured? Who will use the result? A simple written problem statement helps:
This kind of scope keeps your project grounded. It also makes testing possible. If you cannot clearly describe the input, output, and success condition, the problem is probably still too vague. Good projects begin with a clear question the model can help answer.
Once you have chosen a narrow problem, build a simple end-to-end plan. This matters because object detection is not just model inference. A full workflow includes data, testing, decision rules, and communication. Beginners often jump from sample images straight to conclusions. A better approach is to map the whole pipeline before adding technical complexity.
Start with the use case. Suppose your goal is to detect packages near a doorway camera. First, gather sample images from the real location. Include different times of day, shadows, empty scenes, and scenes with objects that might confuse the model, such as bags, shoes, or boxes. Then test a beginner-friendly detector and review the outputs manually. Do the labels match what you need? Are the boxes reasonable? Are confidence scores useful or misleading in this scene?
Next, define the system rule. A detection model returns boxes, labels, and scores, but your application needs a decision. For example: “If a package is detected in the mat region with confidence above 0.65 for three consecutive frames, create an alert.” That rule reduces noise and makes the system more practical than reacting to a single frame.
A simple project plan can follow these steps:
Common mistakes include testing only on ideal images, ignoring false positives, changing too many variables at once, and skipping manual review. Another mistake is trying to retrain too early. Often the first gains come from better camera placement, better lighting, a better threshold, or a better-defined detection zone. Real-world engineering is not only about smarter models. It is also about designing conditions that help the model succeed.
A useful project is not complete until you can explain what it does, how well it works, and where it fails. This is true whether you are showing your work to a teacher, teammate, manager, or client. A common beginner mistake is to present only the best screenshots. That makes the project look polished, but it hides the most important learning. Strong presentations include examples of success, failure, and the decisions you made because of those results.
Start with the problem statement in plain language. Explain what the system is trying to detect, why that matters, and what output it produces. Then describe the setup: camera position, lighting conditions, object classes, and whether the detector was pre-trained or customized. This context helps others interpret your results correctly. Without context, a number like “82% accuracy” is nearly meaningless.
Next, show practical evidence. Include annotated images with bounding boxes and labels, but also summarize patterns. Did the model perform well on large objects and poorly on small ones? Did glare or darkness reduce performance? Were some false positives repeated again and again? These observations show engineering judgment because they connect model behavior to real conditions.
When presenting results, include at least these points:
It is also helpful to avoid overclaiming. Say “This prototype works reasonably well in a fixed daylight scene” instead of “This system solves package detection.” Honest framing builds trust. If the project has privacy or bias concerns, mention them directly and explain any safeguards you used. Clear communication is part of responsible AI practice. A modest, accurate presentation is stronger than an impressive-sounding but unsupported claim.
You now have the beginner foundations needed to continue in computer vision with purpose. You understand object detection in plain language, can distinguish it from classification, can read boxes, labels, and confidence scores, and can test simple models. The next step is not to rush into the hardest techniques. It is to deepen your skill in a structured way.
A smart path forward is to improve one small project. Choose a narrow use case and repeat the full cycle: gather better images, test more carefully, review errors, adjust thresholds, and document results. This repetition teaches far more than jumping between unrelated demos. As you gain confidence, you can explore annotation tools, custom datasets, and beginner-friendly training workflows.
You may also want to branch into related topics. Image segmentation goes beyond boxes and labels individual pixels. Tracking follows objects across video frames. Edge deployment focuses on running models on phones, small computers, or smart cameras. Evaluation metrics such as precision and recall help you compare systems more carefully. But these topics make the most sense after you have real experience with a small end-to-end project.
Here are practical next steps:
The most important habit to keep is curiosity joined with caution. Stay curious about what computer vision can do, but cautious about data quality, limitations, and real-world impact. That combination will serve you well as you move from beginner tools to more advanced systems. A good first project does not need to be perfect. It needs to be clear, honest, and useful enough to teach you what to build next.
1. What is the main shift this chapter encourages after building a first object detection demo?
2. Which beginner project best matches the chapter's advice to start with a small, measurable, low-risk use case?
3. Why does the chapter say a model alone is not enough to create real value?
4. Which of the following is presented as a common reason object detection systems may fail in real-world settings?
5. What responsible practice does the chapter recommend when a model may be uncertain or wrong?
- Learning Evolved.
- Intelligence Amplified.


