Computer Vision — Beginner
Learn how AI finds everyday objects in photos from zero
This course is a short, book-style introduction to one of the most exciting areas of artificial intelligence: teaching computers to recognize objects in photos. It is designed for complete beginners who have never studied AI, coding, machine learning, or data science before. If you have ever wondered how an app can identify a dog, a car, a face, a bottle, or a piece of fruit in an image, this course gives you a clear and friendly explanation from first principles.
Instead of assuming technical knowledge, this course starts with the basics. You will learn what a digital image really is, how AI looks for patterns in pictures, and how a system turns a photo into a prediction. Every chapter builds on the last one, so you can develop understanding step by step without feeling overwhelmed.
Many AI courses move too fast or depend on heavy math and coding. This course takes a different path. It focuses on clear language, visual thinking, and practical understanding. The goal is not to turn you into an engineer overnight. The goal is to help you truly understand how object recognition works so you can talk about it confidently, evaluate basic results, and plan a simple project of your own.
You will begin by learning how computers “see” photos through pixels and patterns. Then you will explore how models learn from examples, why labels matter, and how training data shapes results. After that, you will examine predictions, confidence scores, and common mistakes so you can understand what a model is doing well and where it may be going wrong.
In the second half of the course, you will learn how a beginner object recognition workflow is organized. You will see how to choose a practical goal, gather helpful image examples, and test results using new photos. The course then introduces responsible use, including bias, privacy, and safety, because good AI learning should include both technical understanding and thoughtful decision-making. Finally, you will bring everything together by planning a small real-world photo recognition project that matches your current skill level.
This course is ideal for curious learners, students, professionals exploring AI for the first time, educators, and anyone who wants to understand computer vision without technical barriers. It is especially useful if you want a gentle first step before moving into tools, coding, or more advanced machine learning topics later.
If you are brand new and want a safe starting point, this course will help you build the vocabulary, mental models, and confidence needed to continue learning. You can also Register free to begin your learning journey or browse all courses to explore related beginner-friendly AI topics.
By the end of the course, you will be able to explain object recognition in plain language, understand the role of training data, read predictions and confidence scores, spot common failure cases, and describe the limits of image AI responsibly. Most importantly, you will be able to think through a simple object recognition project from start to finish in a structured way.
AI can seem mysterious at first, but it becomes much easier when you learn it one idea at a time. This course helps you do exactly that with a practical, readable, beginner-first approach to computer vision.
Computer Vision Educator and Machine Learning Engineer
Sofia Chen designs beginner-friendly AI learning programs with a focus on computer vision and practical understanding. She has helped students with no technical background learn how image models work through simple explanations, visual examples, and guided projects.
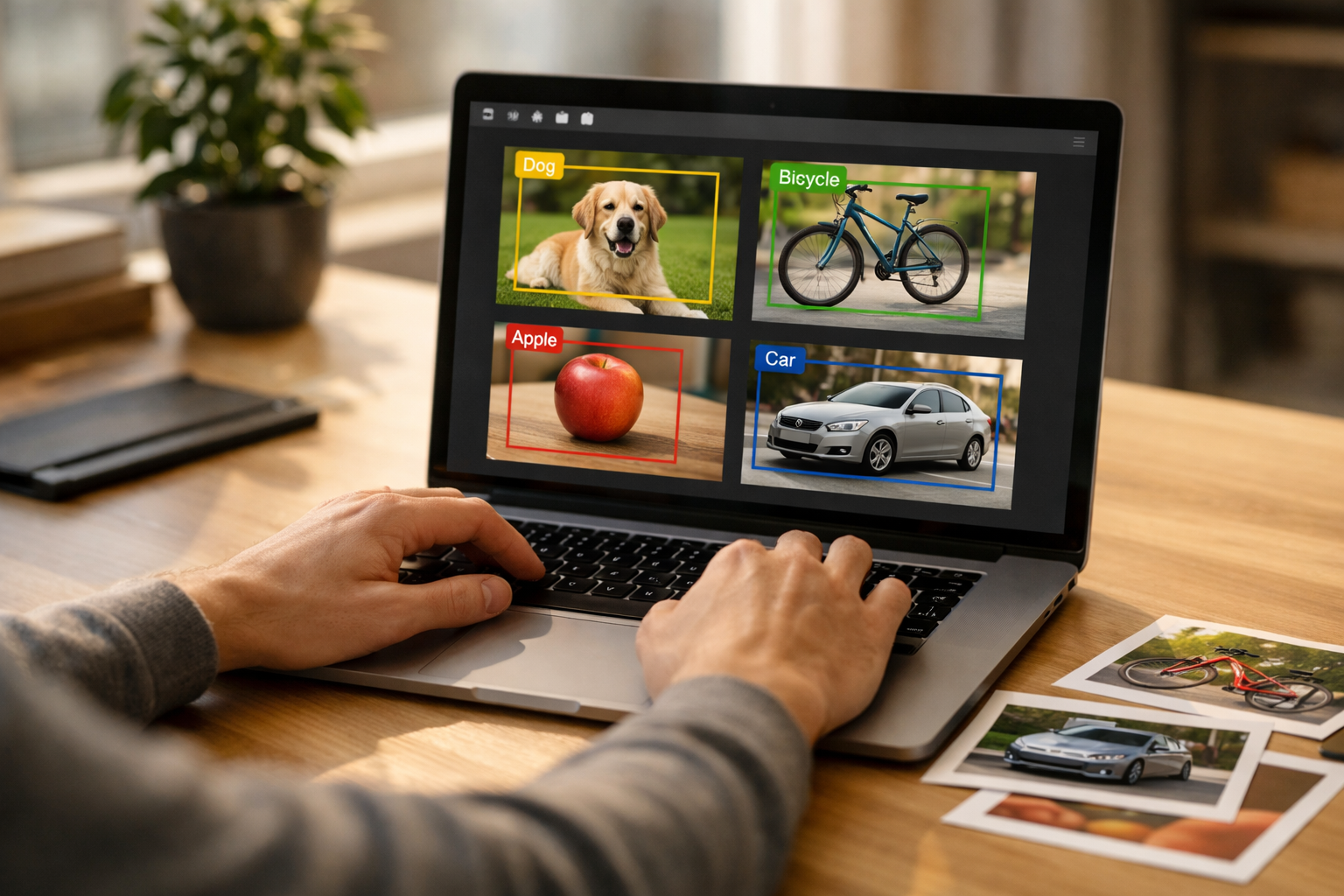
When people first hear the phrase object recognition, they often imagine a computer looking at a photo the way a human does. That is a useful starting picture, but it is not literally true. A person looks at a photo and quickly understands meaning: a dog running in grass, a parked bicycle, a friend holding a cup. An AI system does something more mechanical. It receives image data, processes visual patterns, compares those patterns to what it learned during training, and produces a prediction such as dog, bicycle, or cup with a confidence score.
This chapter builds your first mental model of how that process works. You will learn what object recognition means in simple terms, how a digital image is represented, why AI does not truly “see” in the human sense, and how labels, predictions, and confidence scores fit together. You will also meet the basic workflow used in many computer vision systems: a photo goes in, the model analyzes patterns, and a result comes out. Most importantly, you will begin developing engineering judgment. A model output is not automatically correct just because it sounds plausible. Sometimes the result is useful. Sometimes it is uncertain. Sometimes it is clearly wrong, often because the image is poor, the training data was limited, or the examples were biased in some way.
For a complete beginner, the goal is not to memorize technical formulas. The goal is to build a practical understanding. If you can explain the difference between an image and a label, between a real object and a predicted class, and between a confident answer and a trustworthy answer, then you are already thinking like someone who can work with image AI responsibly.
Throughout this chapter, keep one simple idea in mind: AI object recognition is a pattern-matching system trained on examples. It does not know what a cat is in the human sense. It learns that some arrangements of shapes, textures, colors, and edges often match the label cat. That simple idea will support everything else you study in this course.
Practice note for Understand what object recognition means: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Tell the difference between seeing and predicting: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Recognize common everyday uses of photo AI: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build your first mental model of how the system works: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand what object recognition means: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Tell the difference between seeing and predicting: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Recognize common everyday uses of photo AI: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
To understand what AI sees in a photo, begin with what a digital photo actually contains. A digital image is not a tiny scene stored inside your computer. It is a grid of picture elements called pixels. Each pixel stores numeric values, usually representing red, green, and blue color intensity. A camera photo that looks smooth and meaningful to you is, for the computer, a large table of numbers arranged in rows and columns.
This matters because an AI model does not receive the idea of “a dog on a couch.” It receives pixel values. If the image is 800 by 600 pixels, that means hundreds of thousands of positions, each carrying color information. The model must find useful structure inside those numbers. For a beginner, this is a key shift in thinking: the machine starts with raw data, not understanding.
Even simple changes in a photo can affect those numbers a lot. Lighting, blur, shadows, camera angle, distance, cropping, and background clutter all change the pixel pattern. A dog photographed outdoors at noon looks very different, numerically, from the same dog photographed indoors at night. Humans often ignore those differences. Models may struggle with them if they were not trained on enough varied examples.
In practice, this is why image quality matters. Dark, noisy, tilted, or low-resolution photos are harder for models to interpret. Beginners sometimes assume the model failed because the AI is “bad,” when the real problem is that the input image did not clearly show the object. Before blaming the model, always inspect the photo itself. Ask: Is the object visible? Is it too small? Is the image blurry? Is the background confusing? Good object recognition starts with useful image data.
If a photo is just numbers, how does AI turn those numbers into a guess about what is in the image? The short answer is pattern learning. During training, the model is shown many labeled examples. Over time, it learns statistical relationships between pixel arrangements and labels such as cat, car, or banana. It is not memorizing every photo. It is learning recurring visual patterns that often appear with each label.
At a simple level, models learn to respond to features such as edges, corners, textures, repeated shapes, color regions, and larger combinations of those features. For example, curved outlines, fur-like textures, and face-like arrangements may contribute to a cat prediction. Wheels, windows, and a certain body shape may contribute to a car prediction. This is why object recognition is often described as moving from pixels to patterns.
This also helps explain the difference between seeing and predicting. A person may say, “I see a cat.” An AI system is better described as saying, “Based on learned patterns, this image is likely to belong to the cat class.” That may sound similar, but the difference is important. The model is producing a probability-based judgment, not a human-style understanding of the scene.
In engineering work, this distinction keeps you realistic. If a model predicts wolf because the background contains snow and many wolf training images also had snow, then the model may be using a shortcut pattern rather than the animal itself. That result may still have a high confidence score, but it may not be trustworthy. Good practitioners do not just ask, “What did the model predict?” They also ask, “What visual cues might the model be relying on?”
A practical takeaway is that training data teaches the model what patterns matter. If the training photos are diverse, clear, and balanced, the learned patterns are often more useful. If the examples are narrow, biased, or low quality, the model may learn weak or misleading patterns.
In everyday speech, an object is simply a thing in the world: a cup, chair, dog, shoe, or person. In AI systems, an object usually means a visual category the model has been trained to recognize. That distinction matters. A model cannot identify every possible thing in existence. It can only predict from the set of labels it was trained on, or something close to them.
For example, if a model was trained to recognize cat, dog, and bird, and you show it a rabbit, it may still output one of those three labels because those are its available choices. This is not the model “lying.” It is operating within its defined label space. Beginners often mistake this for intelligence failure, when it is really a design limitation.
This is where several core terms become important. The image is the photo data. The label is the correct category attached to a training example, such as apple. The prediction is the model’s output for a new image. The confidence score is a numeric estimate of how strongly the model favors that prediction. A confidence score is not a guarantee of truth. It only describes the model’s own certainty based on what it learned.
It is also useful to remember that some categories are harder than others. Distinguishing between a mug and a cup may be difficult if the training labels were inconsistent. Recognizing a person is usually easier than recognizing a rare machine part with many similar-looking versions. Good judgment means matching the problem to a realistic label set. If your categories are vague, overlapping, or poorly defined, your model results will also be vague, overlapping, or confusing.
In practice, before building or using an object recognition system, ask: What exact classes does this model know? What examples define each class? Are the categories visually distinct enough to recognize reliably? These simple questions prevent many beginner mistakes.
Beginners often use many image AI terms interchangeably, but they do not all mean the same thing. Recognition usually means deciding what is present in an image or image region. Detection means finding where an object is located and identifying it at the same time, often by drawing a bounding box around it. In short, recognition answers “what is this?” while detection answers “what is this, and where is it?”
Imagine a photo of a kitchen table containing a banana, a plate, and a cup. A recognition system might say, “This image contains a banana.” A detection system might return three separate results with positions: banana at the left, plate in the center, cup on the right. Detection is often more useful in real-world applications because many photos contain multiple objects.
There is also a practical engineering difference. Recognition may be enough for a simple app that checks whether a product photo contains a shoe. Detection is needed for tasks such as counting items on a shelf, locating people in a security feed, or guiding a robot toward a tool. Choosing the wrong task type creates avoidable problems. If you need locations but only build a classifier, the output will feel incomplete. If you only need a yes-or-no category and build a full detection system, you may be adding unnecessary complexity.
When evaluating results, think carefully about usefulness. A recognition output of dog: 0.92 may be perfectly useful for photo tagging. It may be useless for self-driving or warehouse automation, where the system must know where the object is. The right question is not just “Was the prediction correct?” but “Was the prediction correct enough, detailed enough, and reliable enough for the task?” That is a core habit in computer vision work.
Object recognition is already part of everyday technology, even if users do not notice it. Phone photo apps group pictures of pets, food, cars, or beach scenes. Shopping platforms identify products from uploaded images. Social media tools suggest alt text or organize image libraries. Security systems detect people or vehicles in camera feeds. Agricultural systems recognize crop diseases from leaf photos. Medical tools may flag suspicious patterns in scans, though those systems require much stricter testing and oversight.
These examples are helpful because they show that image AI is not magic. It is a practical tool for classification, filtering, searching, counting, assisting, and monitoring. But each use case has different requirements. A casual photo search feature can tolerate occasional mistakes. A factory inspection system may need very high accuracy. A medical workflow needs careful validation, human oversight, and awareness of risk.
As a beginner, look for the hidden workflow behind each example. A user supplies an image. The system prepares it, perhaps resizing or normalizing it. A trained model analyzes patterns. The output includes labels, confidence scores, and possibly locations. Then the application decides what to do with that result, such as showing a tag, raising an alert, or asking for human review.
Everyday examples also reveal common mistakes. If a model works well on bright product photos but fails on customer uploads, the training data was probably too clean and too narrow. If it performs well for one style of object but poorly for another, the examples may have been unbalanced. If it keeps confusing similar items, the classes may need better definitions or more distinctive training images. The practical lesson is that model performance depends strongly on the match between training examples and real-world use.
This simple three-part view helps you evaluate outputs realistically instead of treating all predictions as equally trustworthy.
Now we can combine the ideas into one beginner-friendly mental model. An object recognition system usually follows a straightforward pipeline. First, it receives an input image. Second, the image may be prepared by resizing, cropping, adjusting color values, or converting it into the format expected by the model. Third, the trained model processes the pixels and extracts learned patterns. Fourth, it produces outputs such as labels, confidence scores, and sometimes object locations. Finally, an application or human user interprets the result and decides what action, if any, should be taken.
This pipeline sounds simple, but each stage affects quality. A poor input can harm the result before the model even begins. A mismatch between training data and real-world images can make pattern recognition unreliable. A high confidence score can still be misleading if the model learned biased shortcuts. And a technically correct prediction may still be operationally useless if it does not answer the real business or user need.
That is why engineering judgment matters from the start. Do not ask only whether the system produced an answer. Ask whether the answer is actionable. Ask whether uncertainty should trigger a fallback, such as requesting another photo or sending the case to a human reviewer. Ask whether the model was trained on enough variation in lighting, angles, backgrounds, object sizes, and object types.
Many beginner mistakes happen because people focus only on the model and ignore the data. Poor data quality, weak labels, missing examples, and biased sampling often cause more trouble than the algorithm itself. If nearly all training photos of mugs are white ceramic mugs on kitchen counters, the model may struggle with metal travel mugs in cars. The problem is not that AI cannot learn. The problem is that it learns from what it is shown.
The practical outcome of this chapter is a solid first framework: a photo is numeric data, the model learns patterns from labeled examples, the output is a prediction rather than human understanding, and the value of that prediction depends on context, confidence, and data quality. With that mental model, you are ready to go deeper into how object recognition systems are trained, evaluated, and improved.
1. What does object recognition mean in this chapter?
2. What is the key difference between human seeing and AI predicting?
3. Which example best matches the basic workflow of many computer vision systems?
4. Why might an AI model give a wrong or uncertain result on a photo?
5. What is the most responsible way to think about a high-confidence prediction?
When people first hear that an AI system can recognize objects in a photo, it can sound mysterious. In practice, the process is much more understandable: the system learns from many examples. If you show a model enough photos with correct labels, it starts to notice patterns that repeat. A beginner can think of this like teaching a child with flashcards. You point to many pictures of apples, mugs, shoes, and chairs, and over time the learner begins to separate one group from another. The machine does not “understand” objects the way humans do, but it can still become very good at matching visual patterns to names.
This chapter explains the foundation of that learning process in simple language. You will see why examples matter so much, what labels really are, and how a model improves during training. You will also learn an important practical lesson: more data does not automatically mean better results. If the examples are confusing, biased, or poorly labeled, the model may learn the wrong lesson. In real object recognition work, engineering judgment matters just as much as collecting large files of images.
At a high level, the workflow looks like this: collect photos, assign labels, split the data into training, validation, and test sets, train a model, review predictions and confidence scores, and decide whether the results are useful. Along the way, we must ask practical questions. Are the labels correct? Are the photos similar to the real-world images the model will see later? Is the model confident for the right reasons, or is it being fooled by background details? These questions are part of responsible beginner practice.
By the end of this chapter, you should be able to explain in plain words how training data helps an AI model learn visual patterns. You should also be able to tell the difference between an image, its label, the model’s prediction, and the confidence score attached to that prediction. Most importantly, you should begin to develop judgment: sometimes a result is useful, sometimes it is uncertain, and sometimes it is likely wrong. Learning to notice that difference is a key step in computer vision.
The six sections in this chapter build from the simplest idea—learning by example—to a more practical understanding of why data quality controls model quality. As you read, keep one idea in mind: object recognition systems do not become accurate by magic. They improve because examples, labels, and feedback are organized carefully.
Practice note for See why examples are the foundation of AI learning: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand labels in plain language: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Learn how a model improves during training: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Connect data quality to final results: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for See why examples are the foundation of AI learning: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
A useful way to understand AI training is to compare it to a beginner student learning with many examples. Imagine teaching someone who has never seen a bicycle before. You do not begin with a complicated mathematical definition. Instead, you show many pictures: bicycles from the side, bicycles from the front, large bicycles, small bicycles, red ones, blue ones, and bicycles partly hidden behind other objects. After enough examples, the student starts to notice repeated visual patterns such as wheels, handlebars, and a frame shape. A machine learning model works in a similar way. It learns from repeated exposure to examples that have been labeled correctly.
This does not mean the model memorizes every photo in a human-like way. What it tries to do is adjust itself so that photos with similar patterns lead to similar outputs. At first, a beginner model is usually poor at the task. Its predictions may look random or overconfident. During training, it is shown an image, makes a guess, compares that guess with the correct label, and then changes its internal settings slightly. This happens again and again over many examples. Little by little, the model improves.
The main lesson here is that examples are the foundation of AI learning. If the examples are too few, too narrow, or too messy, the model will not build a reliable understanding of the visual task. If the examples are representative of the real world, learning becomes much more useful. For a beginner, this is an important mindset shift: when a model fails, the problem is often not just “the AI,” but the examples it learned from.
In object recognition, practical success comes from asking simple questions early. Do the example photos cover different lighting conditions? Different object sizes? Different camera angles? Different backgrounds? If the training set only contains studio product images on white backgrounds, the model may struggle when shown a phone photo from a kitchen or street scene. Good example-based learning depends on variety that matches the job you want the model to perform later.
To work with object recognition, you need a clear vocabulary. The photo or image is the raw visual input. The category is the group you care about, such as cat, dog, bottle, or backpack. The label is the name attached to an image to tell the model what is correct. If a photo shows a banana and the label says “banana,” that image-label pair becomes one training example. Over many examples, the model learns to connect image patterns with category names.
Beginners often mix up labels and predictions. A label is the known answer used during teaching. A prediction is the model’s answer after it has learned from data. For example, you may input a photo of a cup. The label in your dataset might be “cup.” After training, the model may predict “cup” with a confidence score of 0.91. That score does not mean the prediction is guaranteed correct. It only means the model strongly prefers that answer compared with its alternatives.
Labels sound simple, but they require careful thinking. What should count as a “car”? Do toy cars count? Does a partial view count? What about blurry images? If two people label the same kind of image differently, the model receives confusing instructions. In practice, strong projects define categories clearly and create simple rules for labeling. This improves consistency and reduces noise in the data.
Another useful beginner habit is checking whether categories are visually distinct. Some tasks are easy because categories look different, such as apple versus bicycle. Others are harder, such as different dog breeds or similar-looking electronic devices. When labels represent categories that even humans find difficult to separate, expect the model to need more careful data and more realistic evaluation.
In plain language, labels are the teacher’s notes written next to each example. If those notes are wrong, vague, or inconsistent, the model learns from bad instruction. That is why label quality is one of the most important hidden factors in any object recognition project.
Once you have labeled images, the next practical step is splitting them into separate groups. Beginners should understand three common sets: training, validation, and testing. The training set is used to teach the model. The model repeatedly sees these images and adjusts itself based on mistakes. The validation set is used during development to check how learning is going and to compare different settings or approaches. The test set is kept aside until the end to estimate how well the final model performs on unseen data.
This split matters because a model can appear to do well while actually just memorizing training examples. If you judge performance only on images the model already saw during learning, you may get a false sense of success. Validation and testing help answer the more realistic question: can the model handle new photos? That is the real goal in object recognition.
Here is a simple workflow. First, collect and label images. Second, divide them into the three sets. Third, train the model on the training data. Fourth, check validation results to see whether the model is improving or starting to overfit. Overfitting means the model is becoming too specialized to the training images and less useful on new ones. Finally, once decisions are finished, evaluate the final version on the test set.
When reading results, do not focus only on a single number. A model may have decent overall accuracy but still fail badly on one important category. Also review confidence scores. A high-confidence wrong answer can be more dangerous than a low-confidence uncertain one, especially in real applications. Engineering judgment means looking beyond “good” or “bad” and asking whether the result is useful for the actual task.
A practical beginner mistake is leaking similar images across splits. For example, if nearly identical photos from the same burst of camera shots appear in both training and test sets, the test score may look unrealistically high. Good evaluation depends on honest separation between what the model learns from and what it is later judged on.
People often say that AI needs more data, and that is partly true. A model usually benefits from enough examples to learn a pattern reliably. However, more data is not automatically better data. If you add thousands of poor-quality or misleading examples, you may actually reduce performance. Quantity helps only when it supports the task with relevant, accurate, and balanced information.
Imagine training a model to recognize reusable water bottles. You collect 500 clear phone photos of bottles in everyday settings. Then you add 10,000 blurry online images, many mislabeled, many showing packaging instead of the bottle itself. Even though the dataset is now much larger, the added noise may confuse the model. It may begin learning shortcuts that do not match the real use case. Bigger is not always smarter.
Bias is another reason more data can fail to help. Suppose almost all your training images of bicycles are outdoors in daylight, while most non-bicycle images are indoors. The model may accidentally learn “outdoor scene” as a clue for bicycle. If you then use it on indoor bicycle photos, performance may collapse. More examples of the same bias only make that shortcut stronger.
Practical projects aim for useful coverage, not just large file counts. Good questions include: Does the dataset include different object positions, backgrounds, lighting conditions, and camera types? Are some categories overrepresented while others are rare? Are there duplicate images that add little value? Could low-quality examples be reviewed or removed?
The engineering lesson is simple: collect data with purpose. Add examples that expand the model’s understanding of the real world, not just examples that make the spreadsheet larger. A smaller, cleaner, more representative dataset can often outperform a much larger careless one.
Not all training examples are equally helpful. Some are clear and informative. Others are messy and difficult even for humans. A clear example might show one object in focus with good lighting and an accurate label. A messy example might be blurry, dark, partly blocked, mislabeled, or filled with distracting objects. Real datasets usually contain both kinds, but the balance matters.
Clear examples are especially useful early in a project because they help the model learn strong basic patterns. Once those basics are in place, adding moderate difficulty can make the model more robust. But if too many examples are messy from the start, the model may struggle to learn what matters. Beginners sometimes assume that every real-world image must be included immediately. In practice, it is often smarter to first build a clean foundation and then gradually include harder cases.
Messiness is not only about image quality. It can also come from inconsistent labeling. For instance, if one image with a visible backpack is labeled “bag,” another is labeled “backpack,” and a third is labeled by the scene instead of the object, the model receives mixed messages. This weakens training and makes results harder to interpret later.
When reviewing model failures, inspect the underlying examples. Ask whether the mistaken images were difficult, ambiguous, or mislabeled. This turns error analysis into a practical habit. Sometimes the model is at fault, but often the data is sending confusing signals. Correcting labels, removing unusable images, or rewriting category rules can improve results more than changing the model itself.
A strong beginner workflow is to sample your dataset manually before training. Look at dozens or hundreds of images. You will often spot obvious issues quickly: wrong folders, screenshots mixed with photos, severe blur, duplicates, unrelated objects, or systematic bias. This simple review can prevent many downstream problems.
Although a beginner does not need deep mathematics yet, it is helpful to understand the general idea of what a model learns. The model searches for visual clues that help separate one category from another. These clues might include edges, curves, textures, repeated shapes, color patterns, and spatial arrangements. For example, a model learning to recognize a soccer ball may respond to round shape, surface pattern, and typical contrast areas. For a keyboard, it may pick up rows of small repeating keys and a rectangular overall form.
Importantly, the model does not always choose the clues a human would choose. Sometimes it learns useful signals, and sometimes it learns shortcuts. If every photo of a cat in the training set happens to include a particular sofa, the model may start using the sofa as a clue for “cat.” That may produce high confidence scores in training but poor real-world performance. This is why model results must be evaluated with judgment, not blind trust.
From photo to result, the workflow remains practical. The image is fed into the model. The model extracts patterns and compares them to what it learned during training. It then outputs one or more predictions with confidence scores. A human reviews whether that result is useful, uncertain, or likely incorrect. This final step matters because confidence is not the same as truth. Models can be confidently wrong.
As a beginner, your goal is not to inspect every internal detail but to connect outcomes back to data. If a model consistently fails on side views, nighttime images, or crowded scenes, that suggests the training data did not teach enough about those situations. If it confuses two similar categories, perhaps the labels are too broad, too narrow, or not visually distinct enough. The clues a model learns are shaped by the examples you provide.
This is the key practical message of the chapter: object recognition quality depends on example quality, label clarity, careful evaluation, and thoughtful judgment. Machines learn from examples, but humans decide whether those examples are teaching the right lesson.
1. According to the chapter, what is the main way an AI object recognition model learns?
2. In plain language, what is a label?
3. What does it mean when a model improves during training?
4. Why does the chapter say that more data does not automatically lead to better results?
5. Which sequence best matches the workflow described in the chapter?
When a beginner first sees an object recognition system, it can feel magical: a photo goes in, and a label comes out. But useful computer vision is not magic. It is a process of making a best guess from patterns learned during training. In this chapter, you will learn how to read that guess carefully instead of accepting it blindly. That means understanding the difference between a prediction and the real answer, reading a confidence score in plain language, and noticing when the result might be shaky or wrong.
A model prediction is not a fact. It is the model saying, “Based on what I learned from past images, this is the object I think is most likely here.” Sometimes that guess is very helpful. Sometimes it is uncertain. Sometimes it is confidently wrong. Good beginners learn to inspect results with calm engineering judgment. They ask simple questions: Does this result fit the image? Is the score strong or weak? Could lighting, angle, blur, or messy backgrounds be confusing the model? Was the training data broad and fair enough to prepare the model for this kind of photo?
These questions matter because object recognition workflows are built from many moving parts. First there is an image. Then the model compares visual patterns in that image with patterns it learned during training. Next it produces one or more labels with scores. Finally, a person or application decides what to do with that output. If you understand only the final label, you miss half the story. If you understand the prediction, the score, and the possible failure modes, you can judge whether a result is useful, uncertain, or likely incorrect.
In this chapter, we will look at the most common ways model outputs can go right and wrong. You will see how an AI can be unsure, why mistakes happen even when the software seems confident, and how to do a quick quality check before trusting a result. This is one of the most practical skills in computer vision: not just getting an answer, but reading the answer wisely.
As you read the sections, keep one idea in mind: beginners do not need advanced math to become careful users of AI. You mainly need a clear mental model of what the system is doing and a practical checklist for judging outputs. That is exactly what this chapter provides.
Practice note for Read a model prediction with confidence: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand why AI can be unsure: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Spot common types of recognition errors: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Use simple checks to judge result quality: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Read a model prediction with confidence: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
A prediction is the label an AI model chooses after examining an image. If the model sees a photo and outputs “dog,” that does not mean the machine has proven there is a dog. It means the model found visual patterns that look most similar to what it learned as “dog” during training. This is an important difference. The image is the input. The label is a human-defined category such as dog, cat, car, or apple. The prediction is the model’s output. The real-world object in the photo may match that output, or it may not.
Beginners often treat a prediction like a final answer on a test. In practice, it is better to treat it like a suggestion from a very fast assistant. Sometimes the assistant is excellent. Sometimes it is guessing from incomplete clues. For example, if you show the model a close-up of fur and part of an ear, it may predict “cat” because those patterns match its training examples. But if the photo actually shows a fox toy, the prediction is not truly correct even if the visible texture looked cat-like.
This is why context matters. A model does not understand a scene the way a person does. It compares patterns. If the training data taught it that round red objects with stems are usually apples, it may predict “apple” for a red ornament or a tomato in unusual lighting. The model is not lying. It is applying what it learned.
When reading a prediction, ask practical questions: What label was returned? What other labels were close behind? Does the image clearly show the object? Is the object centered, large enough, and visible? Could another class look similar? These checks help you judge whether the prediction is likely useful. The key lesson is simple: a prediction is a model’s best learned guess from visual evidence, not a guaranteed statement of truth.
After a model makes a prediction, it often returns a confidence score. For beginners, the easiest way to read this score is: how strongly does the model favor this label compared with the alternatives? If the model says “banana: 0.92,” that usually means banana is its strongest choice by a wide margin. If it says “banana: 0.38” and “plantain: 0.34,” the model is much less sure. It sees competing possibilities.
A common mistake is thinking the score is a direct measure of truth. It is not. A score of 0.92 does not mean there is a 92% chance the object is truly a banana in the real world. It means the model’s internal comparison landed strongly on that class. Models can still be confidently wrong, especially if the training data was limited or biased. They can also be cautiously right when an image is blurry or unusual.
Confidence is helpful when used with judgment. High confidence on a clear, well-lit image of a common object is often reassuring. Low confidence is a signal to slow down and review the image or request a better one. In real workflows, teams often set simple thresholds. For example, a result above 0.85 may be accepted automatically, a result from 0.50 to 0.85 may be flagged for review, and a result below 0.50 may be treated as uncertain. These numbers vary by project, but the idea is practical: scores help decide how much trust to place in the output.
It also helps to compare the top few results rather than staring at one score alone. If the first and second labels are very close, the model is effectively saying, “I am torn between these options.” For a beginner, that is one of the clearest signs of uncertainty. So read confidence scores as clues about model preference, not as promises. They are useful, but only when combined with common sense and image inspection.
One of the trickiest problems in object recognition is that a model can produce the correct label for the wrong reason. This happens when it learns a shortcut from the training data instead of learning the object itself. Imagine a model trained to recognize cows. If many training photos of cows happen to include green grass, the model may begin to associate grass with “cow.” Later, it might predict “cow” whenever it sees a grassy field, even if no cow is present. Or it may correctly label a cow photo mainly because of the background rather than the animal’s shape.
This matters because shortcuts fail when conditions change. A cow in snow, indoors, or at night may confuse a model that relied too heavily on background clues. Beginners are often surprised by this. They assume that if a model gives the right answer many times, then it must understand the object properly. But models learn from examples, and examples can accidentally teach bad habits.
There are practical ways to spot this issue. Review groups of successful predictions, not just failures. Ask what patterns repeat in the images. Does the model only perform well when the object is centered? Does it succeed when a certain logo, surface, or color appears? Does it fail when the same object appears in a new setting? These are signs the model may be using shortcuts.
The fix usually begins with better training data. Include wider variety: different backgrounds, camera angles, lighting, sizes, and object positions. Make sure labels are correct. Remove accidental patterns that strongly tie one class to one environment. Engineering judgment here is simple but powerful: do not ask only, “Did the model get the answer right?” Also ask, “Would it still get the answer right if the easy background clue disappeared?”
Two of the most important error types in AI recognition are false positives and false negatives. A false positive means the model says an object is present when it is not. For example, it predicts “cat” in a photo of a fuzzy blanket. A false negative means the object is present, but the model misses it or labels it as something else. For example, there really is a bicycle in the image, but the model predicts “motorbike” or nothing useful at all.
Both error types matter, but the bigger problem depends on the task. In a casual photo app, a few wrong labels may be annoying but not serious. In a safety or quality-check setting, the cost can be much higher. A false positive might trigger unnecessary action. A false negative might miss something important. Good beginners learn to think beyond accuracy and ask which type of mistake hurts more.
Confidence scores can help here, but they do not eliminate the problem. A false positive can still arrive with high confidence if the model has learned the wrong pattern strongly. A false negative can happen when the object is small, hidden, blurred, or shown from an unusual angle. This is why reviewing only correct predictions gives an incomplete picture. You need to inspect mistakes too.
A practical review method is to keep simple examples of each error type. Build a small folder of images the model gets wrong. Group them into false positives and false negatives. Then look for patterns. Are false positives caused by similar textures? Are false negatives happening in dark photos? Are certain classes confused with each other? This habit turns random mistakes into useful feedback. Once you see the pattern, you can often improve data collection, retraining, or threshold settings more effectively.
Even a well-trained model can struggle when the image itself is difficult. Three common troublemakers are lighting, angle, and clutter. Poor lighting can hide important edges, colors, and textures. A bright glare may wash out details. Deep shadows may remove them. An object photographed from an unusual angle can look very different from the examples the model saw during training. Background clutter can distract the model, especially if the object is small or partly blocked.
Think of a simple example: a coffee mug. In a clear front-facing photo on a plain table, recognition may be easy. But if the mug is upside down, half hidden behind a laptop, photographed in dim yellow light, and surrounded by many objects, the same model may hesitate or fail. This does not always mean the model is bad. It may mean the photo quality or scene complexity is outside what the model learned to handle.
Beginners should learn to inspect the image before blaming the AI. Is the object large enough in the frame? Is it blurry from motion? Is part of it cropped out? Is the background crowded with similar shapes? Is the color changed by lighting? These checks often explain why a result looks uncertain or incorrect.
The long-term fix is usually better and more varied training data, but there are also simple workflow improvements. Ask for clearer photos. Standardize camera distance if possible. Reduce background mess. Capture multiple angles. Include difficult examples during training rather than only neat, perfect ones. The lesson is practical: image conditions strongly affect recognition. When results worsen, first look at what the camera captured, not just what the model output.
You do not need advanced tools to judge whether model results are useful. A few simple checks can dramatically improve your decisions. First, always look at the image and the top prediction together. Do not read labels in isolation. If the object is unclear to you, the model may also be struggling. Second, check the confidence score and compare the top few labels. A close race between classes is a clear sign of uncertainty.
Third, review results in small batches rather than one by one. Patterns appear faster when you inspect many outputs together. You may notice that the model often fails on dark images, side views, reflective surfaces, or cluttered scenes. Fourth, separate “useful,” “uncertain,” and “likely incorrect” results. This three-part judgment is practical for beginners. Useful means the output matches the visible object and the score seems strong. Uncertain means the image is difficult, the score is moderate, or competing labels are close. Likely incorrect means the result clashes with obvious visual evidence.
Fifth, keep notes about repeated mistakes. You do not need a complex spreadsheet at first. Even a short list helps: wrong class, image condition, likely reason. Over time, these notes point toward fixes such as collecting more diverse examples, cleaning labels, or changing review thresholds. Sixth, be alert to bias in the examples. If one object class was mostly trained in one setting, the model may behave unfairly or weakly in other settings.
A practical mini-checklist for every output is useful:
These simple review habits turn model outputs into something you can manage wisely. The goal is not to expect perfection. The goal is to know when a result is trustworthy enough to use, when it needs a second look, and when it should be rejected as likely wrong.
1. What does a model prediction represent in object recognition?
2. What does a confidence score tell you?
3. Which situation is most likely to make an object recognition model unsure or wrong?
4. Why is it risky to look only at the final label and ignore the score?
5. What is a good simple quality check before trusting a model output?
In the previous chapters, you learned the basic ideas behind object recognition: a computer looks at images, compares visual patterns, and returns predictions with confidence scores. In this chapter, we connect those ideas into a practical beginner workflow. The goal is not to turn you into a machine learning engineer overnight. The goal is to help you see the full path from a simple problem to a usable result, using sensible choices and realistic expectations.
A beginner object recognition workflow usually starts with a question such as, “Can I tell whether a photo contains a banana or an apple?” It then moves through a series of steps: define the task, choose the object categories, gather examples, organize labels, use a tool to train or test a model, and evaluate whether the result is useful. That sounds straightforward, but many beginner mistakes happen when one of those steps is vague or rushed. For example, a project may fail not because AI is “bad,” but because the photos were blurry, the labels were inconsistent, or the project goal was too broad.
Think of the workflow as a chain. If one link is weak, the whole chain becomes unreliable. A model can only learn from what it is shown. If your image examples are narrow, biased, or confusing, the predictions will reflect those problems. If your test photos are too similar to your training photos, you may think the model is excellent when it has only memorized a pattern in the background. Good engineering judgment begins with asking practical questions: What exactly am I trying to recognize? What counts as success? What should the model ignore? How will I know when a prediction is uncertain or likely wrong?
This chapter walks through a beginner-friendly workflow in six steps. You will learn how to choose a realistic project, prepare image examples in a sensible way, understand the role of tools without getting lost in coding details, and evaluate outputs in a way that matches real use. By the end, you should be able to describe a complete object recognition process from problem to result in simple words and make better decisions about your own first project.
Remember that object recognition is not magic. It is a structured process. The more clearly you define the task and the more thoughtfully you prepare examples, the more useful the final predictions will be. A simple project done carefully is much more valuable than an ambitious project done carelessly.
Practice note for Map the full workflow from problem to result: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Choose a realistic beginner project goal: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Prepare image examples in a sensible way: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand the role of tools without coding detail: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Map the full workflow from problem to result: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
The first step in any beginner workflow is to define a clear goal. A weak goal sounds like, “I want AI to recognize objects.” A better goal sounds like, “I want a model to tell whether a photo shows a mug, a bottle, or neither.” The clearer the goal, the easier it becomes to collect the right images, choose labels, and judge whether the final result is good enough.
A realistic beginner goal should be narrow. Limit the number of object types, and choose classes that are visually different enough to separate. For example, telling apples from bananas is easier than telling three similar brands of headphones apart. If the categories look almost the same, you may need many more examples and more advanced methods. Beginners often choose a project that is too broad, such as “recognize everything in a kitchen.” That sounds exciting, but it introduces too many categories, too much visual variation, and too many chances for labeling mistakes.
It also helps to define the use case. Ask yourself where the photos will come from. Will they be phone photos taken on a desk? Will they be bright product images? Will the object appear large and centered, or small and partly hidden? These questions matter because a model learns from examples that reflect the environment you care about. If your goal is to recognize fruit in everyday kitchen photos, polished online catalog images may not prepare the model well.
A practical goal includes a success rule. For instance, “If the model is correct most of the time on new phone photos and avoids overconfident mistakes, it is useful for learning.” This kind of statement keeps expectations realistic. AI results are rarely perfect. You are trying to build something helpful, not magical. A clear goal gives the rest of the workflow direction and helps you avoid collecting random data that does not support the task.
Once the goal is clear, decide exactly which object categories matter. These categories become your labels. A label is the name you assign to an image example, such as apple, banana, or background. Good labels are specific enough to be useful but simple enough to apply consistently. If you cannot explain your categories in a sentence, they may be too confusing for a beginner project.
It is often wise to start with just two or three object classes. Add a “none of these” or “other” idea only if it is truly needed and supported by examples. Beginners sometimes create too many labels too early, such as red apple, green apple, sliced apple, apple in bowl, and apple on table. That usually creates unnecessary complexity. If the real goal is simply to recognize an apple, keep the label as apple.
You should also decide what the model should ignore. Backgrounds, lighting differences, table surfaces, and camera angles should not become hidden clues that the model relies on. For example, if every banana photo is taken on a wooden table and every apple photo is taken on a white plate, the model may learn the table or plate instead of the fruit. This is a common beginner mistake. The object category matters; accidental patterns should not.
A useful habit is to write a short label guide. It can be as simple as a few rules in plain language: “Use bottle when a bottle is the main object and visible enough to identify. Do not label a heavily hidden bottle as bottle if even a person would struggle to tell.” This keeps your decisions consistent. Consistent labels are important because the model learns from the choices you make. If similar images receive different labels for no good reason, the model receives mixed signals and performance drops.
After choosing labels, gather image examples that fit the project goal. Training data is how the model learns visual patterns. Each example teaches something: shape, color, edges, texture, typical viewpoints, and the range of variation within a category. For a beginner, the most important idea is not collecting a huge number of images. It is collecting sensible images.
Beginner-friendly image examples are clear, varied, and relevant. Clear means the object can actually be seen. Extremely blurry, dark, tiny, or cut-off images are usually poor teaching material unless your real use case includes those conditions. Varied means you do not want every image to look nearly identical. Include different positions, backgrounds, distances, angles, and lighting conditions. Relevant means the images should resemble the photos you expect in real use.
A small but thoughtful dataset is better than a larger careless one. If you are building a mug-versus-bottle recognizer, try to include multiple mugs and bottles, not just one mug photographed twenty times. Include plain objects and patterned ones. Include some side views and top-leaning angles. Include different rooms if possible. This helps the model learn the category rather than memorizing one specific object.
You do not need coding knowledge to understand the role of tools at this stage. A tool helps you upload images, assign labels, train a model, and see predictions. The tool does not replace judgment. You still choose the examples. You still decide whether the images are balanced and whether they reflect the real problem. In object recognition, the tool is the workshop bench, but the quality of the project still depends on the care of the builder.
Once you have images, organize them so the workflow stays understandable. Good organization reduces mistakes and makes testing much more meaningful. At a simple level, organization means keeping photos grouped by label, using consistent names, and separating the images used for learning from the images used for checking performance later.
Many beginner tools let you create labeled folders or collections. For example, one group might be apple, another banana, and another orange. The exact software matters less than the logic behind it. Every image should have one clear purpose and one clear label. If you are unsure how to label an image, set it aside instead of forcing a bad decision. Messy labels create messy learning.
It is also important to look for imbalance. If you have 200 bottle photos and only 30 mug photos, the model may become better at bottles simply because it has seen many more examples. Balance does not need to be mathematically perfect, but large gaps should make you pause. You should also scan for duplicates or near-duplicates. Ten almost identical photos do not teach ten times as much as one useful photo.
Another important organizational idea is metadata in your own notes, even if the tool hides the technical details. You may note where photos came from, what conditions they represent, and whether some examples are difficult. These notes help when results are confusing. If the model struggles on dim lighting, you can check whether your dataset included enough dim photos. This is the beginning of engineering thinking: use evidence to understand model behavior instead of guessing.
In simple words, organization turns a pile of pictures into training data. The model does not understand your intentions. It only sees the examples and labels you provide. Clean organization helps the tool do its job and helps you trust the results more.
Testing is where many beginners learn the most. A model may appear excellent when shown images it has already seen or images that are almost identical to them. That is why you must test with new unseen images. These are photos the model did not use during learning. They show whether the model has learned a general visual pattern or simply memorized the training examples.
When you test, look at more than just whether the top prediction is correct. Also notice the confidence score. A correct prediction with moderate confidence may still be useful. A wrong prediction with very high confidence is more concerning because it suggests the model is confidently relying on the wrong visual clues. You should ask: Is the result useful, uncertain, or likely incorrect? This practical judgment matters more than chasing a single percentage.
Test images should reflect real use. If your project is meant for casual phone photos, then your test set should include casual phone photos. Include some easier examples and some harder ones. Try different backgrounds and lighting. You may discover that the model does well when the object is centered but struggles when it is partly hidden. That is valuable information. It tells you where the workflow is strong and where it is fragile.
A common beginner mistake is to celebrate too early. If the model scores highly on images that are extremely similar to the training data, the result may not hold up in practice. Another mistake is to treat every wrong answer as failure. Some errors are reasonable when the image is blurry or the object is tiny. The key is to interpret errors carefully. Are mistakes random, or do they follow a pattern? If the same type of mistake appears again and again, the workflow probably needs better data or clearer labels.
A beginner workflow improves through small, evidence-based changes. Do not respond to weak results by throwing everything away or adding random complexity. Instead, inspect what went wrong and make one sensible improvement at a time. This is how practical computer vision work often feels: not dramatic breakthroughs, but steady refinement.
Suppose your model confuses mugs and bowls. You might ask whether your images include enough side views, whether handles are clearly visible, or whether labels were applied consistently when objects were partly hidden. If banana photos were mostly bright and apple photos mostly dark, then better lighting variety may help. If all examples came from one room, gathering images from additional locations may reduce hidden bias.
Common beginner improvements include adding more varied examples, removing poor-quality images, correcting labels, simplifying categories, and improving balance between classes. Sometimes the best improvement is narrowing the goal. A project that tries to recognize ten objects badly may become useful when reduced to three objects done well. This is good engineering judgment: choose a scope that matches the data and tools you have.
Tools can retrain models quickly, show confusion between labels, and display predictions on test images. You do not need deep coding knowledge to benefit from this. What matters is learning how to read the feedback. If the model is uncertain, ask why. If confidence is high but wrong, look for background shortcuts or biased examples. If one class consistently performs worse, check whether it has fewer examples or greater visual variety.
Over time, you should be able to explain the whole workflow in simple words: start with a clear problem, choose the right labels, gather relevant image examples, organize them carefully, test on unseen photos, and improve based on the mistakes you observe. That is the foundation of object recognition for beginners. It is not just about using AI tools. It is about making practical decisions so the results become trustworthy enough to learn from and useful enough to apply.
1. What is the main purpose of the beginner object recognition workflow in this chapter?
2. Which project goal best fits the chapter’s advice for beginners?
3. According to the chapter, why might a project fail even if AI itself is not the problem?
4. Why is it risky if test photos are too similar to training photos?
5. What key idea does the chapter use to describe the workflow as a chain?
By now, you know the basic workflow of object recognition: an image goes into a model, the model compares visual patterns it has learned during training, and it returns one or more predicted labels with confidence scores. That sounds powerful, but it is also where beginners can get the wrong idea. A model that can identify objects in many photos is not the same as a system that truly understands the world. It does not see like a human, and it does not think through context, intention, or fairness. This chapter helps you build realistic expectations so you can use object recognition carefully and responsibly.
A beginner-friendly way to think about this is simple: object recognition is pattern matching under uncertainty. The model has learned from past examples, and it tries to guess what is in a new image. Sometimes it works well. Sometimes it is uncertain. Sometimes it is confidently wrong. These mistakes are not random in every case. They often follow patterns. For example, a model may perform worse on low-light images, unusual camera angles, cluttered scenes, or object types it saw less often during training. If the training data was unbalanced, the errors may also be unfair, affecting some groups, places, or situations more than others.
Responsible use begins with understanding where errors come from. Poor data quality is one major source. Blurry, cropped, noisy, or badly labeled images teach the model the wrong lessons. Bias is another source. If most training images show one kind of background, one region, one style of object, or one demographic context, the model may quietly learn shortcuts that do not generalize. Privacy matters too. Just because a photo can be collected does not mean it should be used. Consent and safe handling are part of responsible computer vision work, even for small beginner projects.
Another key idea is engineering judgment. In real use, you should not ask only, “Did the model give an answer?” You should also ask, “Is this answer useful? Is the confidence score high enough for this situation? What happens if it is wrong?” A wrong prediction in a photo-sorting hobby app may be annoying but harmless. A wrong prediction in a safety, health, security, or access decision can cause real harm. That is why real systems often include human review, fallback rules, limited deployment, and careful testing before being trusted.
As you read this chapter, focus on four practical goals. First, understand why object recognition can fail unfairly. Second, see how bias enters through data, labels, and collection choices. Third, learn safe practices that beginners can follow right away. Fourth, set realistic expectations for what these models can and cannot do in the real world. Responsible AI is not only about avoiding harm. It is also about building systems that are honest about uncertainty, tested on the right examples, and used only where they make sense.
In the sections that follow, you will learn how to spot common risks early. You will see why unfair failure happens, how privacy and consent affect image projects, why wrong predictions can become safety problems, and how human review improves outcomes. Most importantly, you will leave with a simple set of rules for beginner projects so you can practice object recognition without promising more than the technology can reliably deliver.
Practice note for Understand why object recognition can fail unfairly: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
It is tempting to imagine object recognition as digital eyesight, but that picture is misleading. A computer vision model does not experience the scene the way a person does. It does not know why an object is present, what happened before the photo was taken, or what common sense says should be nearby. It receives pixel values and produces predictions based on patterns learned from training data. That means it can be very good in familiar conditions and surprisingly weak when conditions change.
Several practical factors make performance drop. Lighting can change colors and shadows. Motion blur can hide edges. A camera angle from above may look very different from the front view that appears often in training images. Small objects may be overlooked. Busy backgrounds can distract the model. Partial occlusion, where part of the object is blocked, can also confuse the prediction. Even a simple crop can remove the detail the model needs. None of this means the model is broken. It means the model has limits.
Confidence scores can also mislead beginners. A high confidence score does not mean the model has “understood” the scene. It only means that, among the choices it knows, one answer appears strongest according to its learned patterns. If the true object is rare, missing from training, or visually similar to another class, the model may still be confident and wrong. That is why you should evaluate predictions in context rather than trusting the number alone.
A useful beginner habit is to ask three questions every time you review results: What conditions was the model trained for, how similar is this new image to those conditions, and what would happen if the prediction is wrong? This turns object recognition from magic into an engineering task. You stop asking for perfection and start measuring reliability in realistic situations.
Bias enters object recognition long before a model makes its first prediction. It starts when people choose what photos to collect, what labels to use, and what examples to include more often than others. If your training dataset contains many clear daytime street photos but very few nighttime scenes, the model may seem strong during testing and then fail after sunset. If one object type appears mostly in clean studio images while another appears in messy real-world scenes, the model may learn the background differences instead of the object itself.
Labels are another common source of trouble. Beginners often assume labels are facts, but labels are created by people, and people make mistakes. A photo may be mislabeled, labeled too broadly, or labeled inconsistently across the dataset. One person may mark an image as “dog,” another as “pet,” and another as a specific breed. If the rules are unclear, the model learns confusion. Poor labeling quality does not just lower accuracy. It can produce unfair outcomes if some categories are labeled more carefully than others.
Bias can also appear through missing examples. Suppose a model is trained to detect bicycles, but most images show adult bicycles in cities. It may perform poorly on children's bikes, unusual bike designs, rural settings, or bikes partly covered by bags. The model is not intentionally unfair, but the outcome is still uneven. In real-world use, that unevenness matters.
Practical prevention starts with dataset review. Check whether the images cover different lighting conditions, viewpoints, backgrounds, sizes, and real-world contexts. Write down labeling rules before annotation begins. Review samples from every class, not just the biggest ones. If possible, compare performance across conditions rather than using a single overall accuracy number. Responsible engineering means asking not only “How accurate is the model?” but also “Where does it fail, and who or what is affected by those failures?”
Image projects often begin with excitement about collecting data, but responsible work starts with a simpler question: do you have the right to use these photos? Privacy and consent matter even in beginner projects. A photo can contain faces, homes, license plates, screens, personal belongings, or sensitive locations. Even if your project is “only for practice,” people may not want their images stored, labeled, or shared. Respect for privacy is part of good technical work, not a separate legal problem to think about later.
Consent means people understand how their images will be used and agree to that use. If you photograph friends for a practice dataset, explain the purpose clearly. Will the images be stored? Shared with classmates? Uploaded to a cloud service? Used in a demo? If the answer changes, consent should be revisited. Publicly visible content is not automatically safe to collect for any purpose. Beginners should avoid scraping random images or using photos with unclear rights.
There are also practical ways to reduce risk. Collect only the images you truly need. Avoid sensitive personal content. Remove metadata if it is not required. Blur or crop identifying details when possible. Store data securely and limit access. If your project does not require real people, use non-personal objects or open datasets with clear usage terms. These habits make projects safer and easier to manage.
A good rule is data minimization: keep less, share less, and retain data for less time. This not only protects people but also helps beginners stay organized. Responsible AI work is not just about model outputs. It includes the full workflow from image collection to storage, labeling, testing, and deletion. Treat images with care from the very beginning.
Not all model mistakes have the same importance. In a casual app that suggests labels for vacation photos, an occasional wrong answer may be a minor inconvenience. In contrast, if a model is used to help with safety, access control, driving, healthcare, or emergency response, a wrong prediction can lead to harm. That is why responsible use depends not only on accuracy but also on consequences.
Beginners should learn to separate low-risk from high-risk applications. If your model sometimes confuses a cat with a dog in a hobby project, the impact is limited. But if a model fails to detect an obstacle, misidentifies equipment, or incorrectly flags a person or object in a sensitive setting, the mistake may trigger unsafe actions. Confidence scores do not remove this risk. A model can be confidently wrong, especially when faced with unusual situations.
One practical tool is failure planning. Before deployment, imagine the most likely wrong predictions and what happens next. Does the system stop safely, ask for human review, or continue as if the output were correct? Safe systems are designed with fallback behavior. They do not assume perfect recognition. They handle uncertainty explicitly.
For beginners, the safest path is to avoid using object recognition as the only decision-maker in important situations. Use it to assist, sort, suggest, or flag for review rather than to make final high-stakes choices. Test on realistic examples, including difficult ones. If the cost of failure is high, lower your ambitions or keep a human firmly in control. Good engineering is not only about what the model can do on a demo image. It is about what the system should do when the model is wrong.
One of the simplest ways to improve responsible object recognition is to keep a human in the loop. Human review does not mean the model is useless. It means the model is treated as a tool that helps people work faster or notice patterns, while people still apply context, judgment, and common sense. This is especially important when predictions are uncertain, surprising, or high-impact.
In practice, human review can be lightweight. You might send low-confidence predictions to a person for checking. You might require a manual confirmation before saving a label. You might review a sample of predictions each day to catch drift or labeling errors. These small workflow choices often produce better outcomes than trying to force full automation too early.
Common sense is also a quality check. If a kitchen photo is labeled as “boat,” something is probably wrong, even if the confidence score looks high. If the model reports an object that is tiny, hidden, or inconsistent with the scene, a person can notice that mismatch quickly. Humans are also better at handling unusual cases the model has never seen before. They can recognize when the output does not pass a simple reality test.
Beginners often make the mistake of trusting the model more as soon as it seems to work on a few examples. A better habit is to assume every model has blind spots. Build review into your workflow from the start. Keep examples of common errors. Track where the model succeeds and where it struggles. This creates a feedback loop: the human catches mistakes, the project team learns from them, and future data collection or labeling can be improved. Human review is not a sign of failure. It is part of responsible system design.
Responsible AI can feel like a big topic, but for a beginner project, a small set of rules goes a long way. Start with a narrow goal. Do not claim your model recognizes “everything.” Define exactly which objects, conditions, and image types it is meant to handle. This makes testing easier and prevents unrealistic promises. Next, use data you have the right to use, and document where it came from. If the dataset is small or unbalanced, say so clearly.
Then, inspect your data before training. Look for blurry images, duplicates, wrong labels, missing categories, and overly similar backgrounds. Write simple labeling guidelines and follow them consistently. After training, evaluate the model on examples it has not already seen. Include difficult images, not only easy ones. Review results by condition: bright versus dark, near versus far, simple versus cluttered backgrounds. This helps reveal hidden weaknesses.
Another rule is to be honest about uncertainty. If confidence is low, do not present the output as a fact. Use language such as “possible match” or “needs review.” Avoid high-risk uses unless there is strong oversight. Never use a beginner object recognition model as the sole basis for decisions that could affect safety, rights, or access. Keep a person responsible for final judgment.
If you follow these rules, you will do more than build a working demo. You will build good habits. Those habits matter because the strongest beginner skill is not squeezing out one more point of accuracy. It is learning when to trust a model, when to question it, and when not to use it at all. That is the foundation of responsible computer vision.
1. Why can object recognition systems fail unfairly in real-world use?
2. What is the best beginner-friendly description of object recognition?
3. Which situation is most likely to teach a model the wrong lessons during training?
4. Why are confidence scores not enough by themselves when using a model's prediction?
5. What is the most responsible beginner practice for higher-risk uses of object recognition?
This chapter brings everything together. Until now, you have learned the basic language of object recognition: images, labels, predictions, confidence scores, and the role of training data. The next step is to use those ideas in a small project that feels real. A beginner does not need a giant dataset, a complex model, or advanced math to complete a useful first project. What you do need is a clear goal, a simple workflow, and good judgment about whether the result is helpful.
A real-world photo project starts with a practical question. Maybe you want to identify whether a photo contains a reusable plastic bottle, detect fruit on a kitchen counter, or sort pictures of pets into cats and dogs. The best first projects are narrow, visual, and easy to test. They should solve one small problem well instead of trying to recognize hundreds of objects at once. This is an important engineering habit: reduce the problem until it becomes manageable.
In a beginner workflow, you usually move through the same stages again and again. First, you define the task. Then you gather sample images. Next, you run a model or tool to make predictions. After that, you compare the predictions with what is actually in the image. Finally, you decide whether the result is useful, uncertain, or likely incorrect. That last step matters a lot. AI output is not automatically true. A confidence score is not a guarantee. It is a clue that helps you judge the strength of a prediction.
As you work on your first project, remember that perfect accuracy is not the only goal. A model can still be helpful even if it makes some mistakes. For example, a recycling helper app might not correctly label every object, but it could still save time by identifying common items most of the time. The question is not only “Is it right?” but also “Is it useful enough for this situation?”
This chapter focuses on four practical lessons: planning a simple object recognition use case, choosing success measures a beginner can track, presenting results clearly to others, and knowing what to learn next after this course. These are not just project steps. They are the foundation of real AI practice. Strong projects come from clear goals, honest testing, understandable communication, and steady improvement.
Another important lesson is to expect imperfection. Many beginners think a wrong prediction means total failure. In reality, mistakes are valuable because they reveal data problems, edge cases, and blind spots. A blurry photo, poor lighting, unusual camera angle, or biased training examples can all confuse a model. When you notice these patterns, you are thinking like a computer vision practitioner. You are no longer just using AI; you are evaluating it.
By the end of this chapter, you should be able to design a very small object recognition project from start to finish. You will know how to set a realistic target, test it using ordinary photos, explain the results to someone without technical knowledge, and identify the next improvements that matter most. That is a strong beginner milestone, and it turns abstract ideas into something concrete you can build on.
A first real-world AI photo project should feel small enough to finish and rich enough to teach you something. If you can answer, “What is the task, how will I test it, what counts as useful, and what should improve next?” then you are already working in a disciplined and practical way.
Practice note for Plan a simple object recognition use case: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Your first project should be small, specific, and useful. Beginners often make the mistake of choosing a task that is too broad, such as “recognize everything in any photo.” That sounds exciting, but it makes it hard to gather the right images, judge quality, and understand mistakes. A much better first project is something like “detect whether a lunch photo contains fruit” or “classify pet photos as cat or dog.” These tasks are limited enough to test quickly and clear enough to explain.
A useful project usually has three qualities. First, the object classes should be visually different enough that a model has a fair chance. Second, you should be able to collect or find example photos without too much effort. Third, the result should matter in some small way, even if it is informal. For example, maybe you want to sort family pet photos, organize kitchen images, or make a simple demo for school or work. A project becomes more motivating when it connects to something real.
When planning, write your project idea as a plain sentence: “I want the AI to look at a photo and tell me whether it contains a recyclable bottle.” That sentence helps you avoid confusion later. It also forces you to define the input and the output. The input is the photo. The output might be one label, several labels, or a yes/no answer. Keeping this simple is part of good engineering judgment.
Think about what could make the task harder. Will photos be blurry? Will objects be partly hidden? Will lighting change? Will backgrounds be messy? These questions matter because a model trained or tested only on clean examples may fail on normal everyday images. Even before collecting data, you should imagine the conditions where the system will actually be used.
If you can describe the task in one sentence, list a few object labels, and imagine ten test photos you could take today, your project idea is probably at the right beginner size.
Once you have a project idea, the next step is to define what success means. This sounds obvious, but many beginners skip it. They run a model, look at a few predictions, and decide based on feeling. A better approach is to choose simple measures before testing. You do not need advanced statistics. You just need a few checks that tell you whether the system is useful.
A strong beginner success measure is something countable. For example: “Out of 20 everyday photos, the model should correctly identify bottles in at least 16.” That is simple, concrete, and easy to track. Another measure could involve confidence scores: “If confidence is below 60%, I will treat the result as uncertain rather than correct.” This is useful because it separates strong predictions from weak guesses. It also teaches you that confidence should guide interpretation, not replace judgment.
Try to define success from the user’s point of view. If the project is for sorting pet photos, maybe it only needs to be right most of the time on clear images. If it is for a recycling helper, maybe wrong answers are more serious, so you want the system to say “not sure” when confidence is low. Different use cases need different standards. A model that is acceptable for a fun demo may not be acceptable for anything important.
It also helps to track common failure types. Count false positives, where the model says an object is present when it is not, and false negatives, where it misses an object that is there. This matters because the same overall score can hide different weaknesses. A system that often misses bottles is different from one that incorrectly sees bottles everywhere.
Simple success measures turn AI from a vague impression into something you can evaluate honestly. That is a key beginner skill. When you can say what “good enough” means, you can improve the project with purpose instead of guessing.
Testing with everyday photos is where many beginner assumptions are challenged. A model may perform well on clean sample images but struggle on ordinary pictures taken in a kitchen, bedroom, classroom, or street. Real use includes shadows, cluttered backgrounds, tilted angles, partial views, and objects that look different from the examples in training data. That is why testing should include normal conditions, not only ideal ones.
A practical test set might include photos taken at different times of day, from different distances, and with different backgrounds. If your project is about recognizing fruit, do not test only one shiny apple centered on a white table. Include a banana in a bag, an orange partly hidden behind a cup, and fruit in dim light. This gives you a better sense of whether the system understands the object or has simply learned one narrow pattern.
As you test, record four things for each image: what is actually in the photo, what the model predicted, the confidence score, and your judgment about usefulness. This final judgment matters because not every mismatch is equally important. Sometimes the top label is wrong but a second label is close enough to be helpful. Other times a high-confidence wrong answer is more concerning because it looks trustworthy even when it is not.
Be careful about testing only on images similar to your training examples. That creates a false sense of success. If all your bottle images are blue plastic bottles on a desk, the system may fail on a clear glass bottle outdoors. This is one form of data bias. The model is not seeing “bottle” in a broad sense; it may be seeing “blue object on desk” instead.
Testing should also include a few negative examples, meaning photos where the target object is absent. This helps you see whether the model invents objects that are not there. In the real world, many mistakes come from overconfident false alarms.
Everyday testing is where you learn whether the project is genuinely useful. It is also where you begin to think like an evaluator rather than a spectator of AI output.
A good project is not complete until you can explain it clearly. Many people who see your results will not care about model names, training settings, or technical terminology. They want to know what the system does, how well it works, and when they should trust it. Your job is to present the outcome in plain language without hiding important limits.
Start with the problem: “This tool looks at a photo and tries to tell whether a bottle is present.” Then explain the output: “It gives a label and a confidence score, which is the model’s estimate of how sure it is.” After that, share the evidence: “We tested it on 20 everyday photos and it was correct on 16, uncertain on 2, and wrong on 2.” This style is easy to follow because it connects the task, the result, and the quality level.
When presenting results, avoid saying the AI “knows” or “understands” in a human sense. It is better to say it “predicts” based on visual patterns learned from training data. This keeps expectations realistic. Also make sure to mention failure conditions. For example: “It works best on clear photos and struggles when the object is partly hidden or when the lighting is poor.” That is not a weakness in your presentation; it is honest reporting.
Visual examples can help a lot. Show one correct prediction, one uncertain example, and one incorrect example. Add a short note below each image explaining what happened. People understand AI limits much faster when they can see them. This also makes confidence scores easier to interpret. A number like 92% becomes more meaningful when paired with a real photo and a correct label.
Clear communication is part of responsible AI practice. If others can understand what your system does and where it may fail, they are more likely to use it appropriately.
After your first round of testing, you will probably notice patterns in the mistakes. That is a good sign. It means you are ready to improve the project in a targeted way. Beginners sometimes react by changing everything at once, but the smartest approach is to improve one area at a time. Small, focused changes help you see what actually works.
The most common improvement is better data. If the model struggles with dark images, collect more dark images. If it fails on side views, add side-view examples. If one label is underrepresented, gather more samples for that class. Better variety often helps more than simply adding large numbers of similar photos. Diversity in training and testing matters because it teaches the model broader visual patterns.
Another improvement is cleaning your labels. If some training images are mislabeled, the model learns confusion. A photo of a can marked as a bottle can damage learning, especially in a small dataset. Beginners also improve results by removing very low-quality images that are too blurry or ambiguous even for a person to judge clearly. Poor data quality creates poor model behavior.
You can also improve by adjusting the decision process around the model. For example, you might set a rule that predictions below a certain confidence score are labeled “uncertain” instead of treated as final. This does not make the model smarter, but it can make the system more trustworthy in practice. A modest model with honest uncertainty can be more useful than a bolder model that gives wrong answers confidently.
Watch for bias as well. If all your pet photos are indoor cats and outdoor dogs, the system may learn background clues instead of the animals themselves. That kind of shortcut is common. Adding more balanced examples is one of the best beginner fixes.
Improvement is usually less about magic settings and more about clearer data, fairer testing, and better decisions about how to use predictions.
Finishing a first photo project is an important milestone because it gives you a practical frame for future learning. You now understand the basic workflow from image to prediction, and you have seen how labels, confidence scores, and training data affect results. The next stage is to deepen that understanding gradually rather than trying to learn everything at once.
A useful roadmap starts with strengthening the basics. Continue practicing with small object recognition projects until you can reliably plan the task, choose success measures, test honestly, and explain results clearly. Then expand into related topics. One natural next step is learning the difference between image classification and object detection. Classification answers “What is in this image?” while detection also answers “Where is it?” Another next step is understanding how datasets are split into training, validation, and test sets so that evaluation is more reliable.
As your confidence grows, explore practical tools. You might try no-code or low-code computer vision platforms, simple Python notebooks, or beginner-friendly libraries. The goal is not to become highly technical overnight. The goal is to connect the concepts you already know to real tools that let you inspect predictions, compare images, and improve datasets.
You should also keep developing your judgment. In computer vision, technical output is only part of the job. You need to ask whether a model is fair, useful, and trustworthy for the intended context. That means checking for biased examples, understanding uncertainty, and resisting the temptation to overclaim what the system can do.
A good beginner roadmap might look like this:
Computer vision becomes much less mysterious when you work step by step. You do not need to master every detail now. If you can define a problem, evaluate predictions, present results honestly, and improve with evidence, you already have the foundation needed to keep growing in this field.
1. What makes the best first real-world object recognition project for a beginner?
2. Why should you define a simple measure of success before testing?
3. How should a beginner treat a model's confidence score?
4. What is the most useful way to present project results to non-technical people?
5. According to the chapter, what should you do with wrong predictions or mistakes?

- Learning Evolved.
- Intelligence Amplified.

