AI In EdTech & Career Growth — Intermediate
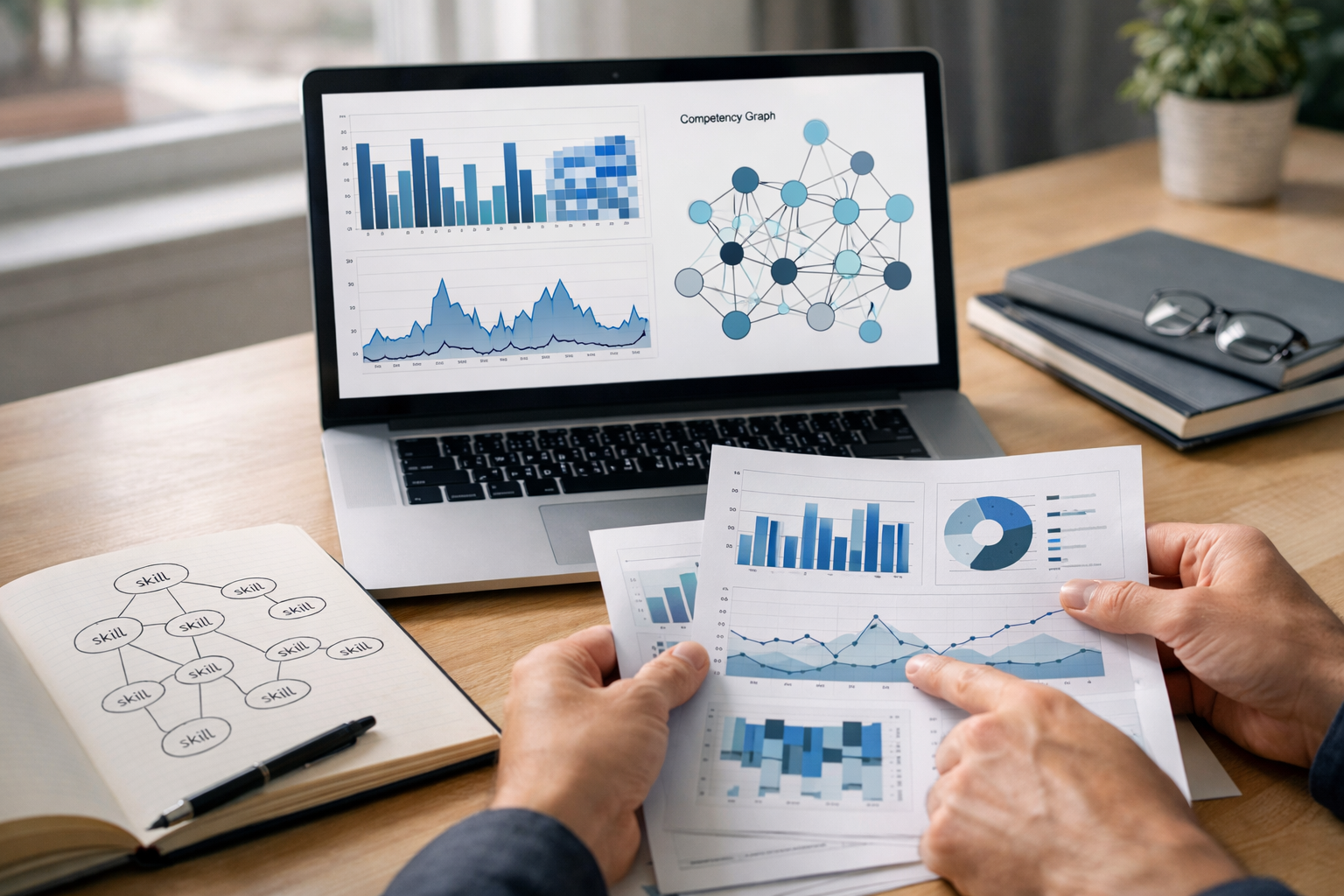
Turn LMS clickstream logs into a validated, job-ready skills map.
Learning platforms collect a huge amount of behavioral data—page views, quiz attempts, time-on-task, retries, forum interactions, completions—but most organizations still report only course completion. This course shows you how to convert LMS logs into a competency map that is credible, explainable, and useful for career growth, talent mobility, and targeted learning design.
You will build a book-style, end-to-end blueprint: start with raw LMS exports, define what counts as evidence, design a competency framework, infer skills with interpretable methods, and validate the results with human review and measurable reliability. The result is not just a model—it’s a defensible process that stakeholders can trust.
This course is built for L&D leaders, learning analysts, EdTech product teams, and HR/Workforce partners who want skills signals that go beyond “completed course X.” If you work with corporate academies, universities, bootcamps, or credential programs and you have access to LMS data (even basic CSV exports), you can apply the approach.
Chapter 1 clarifies the competency use case and turns messy LMS logs into structured evidence. You will define acceptance criteria for what your organization is willing to treat as a “skill claim.”
Chapter 2 builds the competency framework: measurable skill statements, proficiency levels, and a skill graph that reflects prerequisites and clusters—so the map supports pathways, not just labels.
Chapter 3 covers instrumentation and data modeling. You will normalize LMS events into a canonical schema, engineer features, and prepare datasets for inference and validation while handling identity and privacy constraints.
Chapter 4 focuses on inference methods you can explain to non-technical stakeholders. You’ll start with transparent rules, then layer in probabilistic updates and interpretable models to produce confidence-weighted skill estimates.
Chapter 5 makes your map defensible. You will run validation studies, set up human-in-the-loop reviews, measure agreement, and audit subgroup performance to reduce the risk of biased or brittle skill conclusions.
Chapter 6 turns the model into a product: dashboards for learners and managers, role-based gap analysis, recommendations, and integration patterns for HR systems and credentialing—all backed by a governance and privacy playbook.
If you want a practical, audit-ready approach to competency mapping from LMS logs, this course will guide you step by step. When you’re ready, Register free to access the full curriculum, or browse all courses to compare related tracks in learning analytics and career growth.
Learning Analytics Lead & Applied Machine Learning Specialist
Sofia Chen designs learning analytics systems that translate digital learning traces into measurable skills and workforce signals. She has led competency mapping and LRS implementations across corporate academies and higher-ed, focusing on transparent models, validation, and governance.
Learning platforms are very good at recording what happened—clicks, submissions, views, attempts—but they are not automatically good at proving what a learner can do. The gap between “activity” and “capability” is where competency mapping lives. In this course, you will build a pipeline that turns raw LMS logs into defensible skill claims: claims that are explainable, auditable, and useful to HR, L&D, instructors, and learners.
This chapter establishes the working mindset and the practical foundation. You will start by defining the business question and competency use case (who needs the map, for what decision, with what risk tolerance). Next, you will inventory the LMS data sources and event types you can realistically access. You will then create an evidence table from raw logs—a structured dataset that makes inference possible without “reading tea leaves” from scattered events. Finally, you will set acceptance criteria for what counts as a defensible skill claim and draft your first end-to-end pipeline sketch. By the end, you should be able to describe, in plain language and in data terms, how a learner’s interactions become evidence and how that evidence becomes a competency statement with confidence and uncertainty.
A recurring theme: engineering judgment matters. You will make tradeoffs between coverage and precision, between automation and human review, and between sophistication and interpretability. The goal is not to build the fanciest model; it is to build a map that stakeholders can trust and that can survive scrutiny.
Practice note for Define the business question and competency use case: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Inventory LMS data sources and event types: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create an evidence table from raw logs: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Set acceptance criteria for a “defensible” skill claim: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Draft the first end-to-end pipeline sketch: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Define the business question and competency use case: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Inventory LMS data sources and event types: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create an evidence table from raw logs: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Set acceptance criteria for a “defensible” skill claim: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Most LMS reporting defaults to completion tracking: did the learner finish a module, watch a video, or pass a quiz. Completion tracking is valuable for compliance and operations, but it is a weak proxy for competency. Competency mapping asks a different question: what can the learner demonstrate, and what evidence supports that claim? The difference is not semantic—it changes what you measure, how you model it, and how you validate it.
Start by defining the business question and use case. Examples: “Can we recommend project roles based on demonstrated skills?” “Can managers trust a skill badge to waive prerequisite training?” “Can we identify learners who need coaching on a specific competency?” Each use case implies different acceptance criteria. High-stakes decisions (promotion eligibility) demand stricter evidence and more human review; low-stakes personalization (content recommendations) can tolerate more uncertainty.
Common mistake: mapping a competency directly to a course completion. A course can include multiple skills, and learners can complete it with shallow engagement. A better approach is to link competencies to tasks and evidence: specific activities, assessment items, and artifacts that require the skill. Practically, you will define a competency framework (even a minimal one) that connects (1) competencies, (2) the learning objectives or tasks that elicit them, and (3) the observable signals that count as evidence. This becomes the spine of your pipeline.
LMS logs look deceptively straightforward: timestamped events tied to a user and a resource. In practice, fields differ across vendors and integrations, and the meaning of a field can change by context. Inventorying data sources and event types is not busywork; it prevents downstream misinterpretation and reduces the odds of building a model on sand.
Typical fields you can expect include: user_id (sometimes multiple identifiers across systems), course_id, content_id or resource_id, event_type (view, click, launch, submit, attempt, grade-posted), timestamp, session_id (often missing), device/browser metadata, and sometimes duration or time-on-task. Assessment logs may include attempt_number, item_id, score, max_score, feedback_shown, and rubric-level results if you are lucky.
Common pitfalls are predictable. First, identifiers: the LMS user_id may not match HRIS or SSO IDs, and course content may be duplicated or versioned without clear lineage. Second, timestamps: time zones, clock skew, and batch ingestion can reorder events. Third, event semantics: “view” might mean a page loaded in the background; “completion” may be triggered by a rule (e.g., scrolling) rather than understanding. Fourth, missingness: mobile offline activity, ad blockers, and external tool launches (LTI) can create blind spots.
Practical advice: write a “data dictionary + assumptions” document early. For each field, specify source table, type, known null rates, and interpretation rules. For each event_type, specify whether it indicates intent, exposure, effort, or outcome. This document becomes part of the defensibility of your competency map because it shows how evidence was defined and what limitations were acknowledged.
Raw events are granular and noisy. Competency inference usually needs structure: sessions, sequences, and learning episodes that approximate meaningful learner behavior. Think of it as moving from “atoms” (events) to “molecules” (episodes) that can be analyzed and compared.
An event is a single log record: “opened lesson,” “submitted quiz,” “downloaded file.” A session groups events close in time for a user (often using an inactivity timeout such as 30 minutes). A sequence preserves order across events, enabling features like “attempted practice before assessment” or “revisited feedback after failing.” A learning episode is a higher-level unit aligned to a task or objective, such as “worked through Module 3 exercises” or “completed Project Draft 1.” Episodes are what you will typically attach to competency evidence, because they create context: effort + outcome + artifact.
To build sequences that stakeholders can trust, be explicit about rules. Define your sessionization logic (timeout, cross-device handling, whether to split on course changes). Define how to handle out-of-order events (ingestion timestamps vs. event timestamps). Decide what counts as “engaged time” rather than raw duration (e.g., excluding idle periods or background tabs, if you can detect them). These decisions affect fairness and bias: learners who download materials to study offline may look “inactive” unless you account for it.
When you create your evidence table later, you will usually compute features at multiple levels: event counts, time distributions, attempt patterns, and transitions (e.g., view → practice → attempt → review). Keep it interpretable. In early versions, prefer simple sequence features—first attempt score, number of retries, time between feedback and retry—over opaque embeddings. Interpretable features make it easier to validate competencies with rubrics and human review workflows.
Competency claims should be supported by evidence that is as direct as possible. In LMS-driven systems, evidence typically falls into three categories: behavioral signals, assessment outcomes, and learner artifacts. The art is combining them without over-claiming.
Behavioral evidence includes patterns like repeated practice attempts, time spent on targeted tasks, help-seeking (opening hints, revisiting lessons), and persistence after failure. Behavioral evidence is abundant but indirect: it suggests engagement and strategy, not necessarily mastery. Use it to support or contextualize other evidence, or to infer sub-competencies like “self-regulated learning” cautiously.
Assessment evidence is usually the strongest structured signal: quiz items, coding tests, simulations, rubric scores, and mastery checks. It can still be misleading if items are poorly aligned or if retakes allow memorization. Practical move: link each assessment item (or rubric criterion) to the competency framework. Even a lightweight mapping (item_id → competency_id) enables interpretable inference such as: “Competency X supported by 6 items across 2 assessments; most recent score 85% with stable performance.”
Artifact evidence includes projects, essays, uploaded files, discussion posts, and portfolios. Artifacts can be high validity but require rubric-based evaluation and sampling. Here is where validation workflows become central: define rubrics, sample artifacts for human review, and use those results to calibrate automated signals. A common mistake is treating artifact submission as proof of skill; submission is a behavioral event, not an evaluation.
When you build the evidence table from raw logs, plan for evidence granularity: store references to the underlying event_ids, attempt_ids, and artifact_ids so any skill claim can be audited. This is what makes a claim “defensible”: you can show the trail from skill → evidence types → concrete records.
Competency inference is only as credible as the data pipeline. Data quality checks are not a one-time gate; they are continuous tests that protect against silent failures, vendor changes, and evolving course designs. In competency mapping, the biggest risk is making confident claims from incomplete or biased data.
Start with basic integrity checks: uniqueness of primary keys, valid foreign keys (user_id exists, course_id exists), and timestamp sanity (no future dates, no impossible negative durations). Then move to distribution checks: event volumes by day, by course, by event_type. Sudden drops often indicate logging changes or broken integrations. Next, check join coverage: what percent of events can be linked to a course module, assessment item, or competency mapping table? Unmapped events become “dark matter” that can skew engagement metrics.
Missingness is rarely random. Mobile learners may generate fewer events; external tool usage may produce “launch” events without detailed interactions; some courses may log granular events while others only log completions. Treat missingness patterns as part of uncertainty. For example, if artifact evaluations are missing for a cohort, your skill inference should reflect lower confidence, not a default assumption of competence or incompetence.
Practical technique: attach a data completeness score to each learner-course window (e.g., expected vs. observed key events) and propagate it into skill confidence. Also maintain a “known limitations” register: which event types are unreliable, which courses lack item-level data, and where manual review is mandatory. This supports acceptance criteria for defensible claims because it formalizes when the system must abstain or escalate to human review.
A minimum viable competency map (MVCM) is the smallest end-to-end system that produces useful, reviewable competency evidence without pretending to cover everything. MVCM thinking prevents stalled projects caused by overly ambitious frameworks or perfect-data fantasies. Your first goal is not completeness; it is a defensible pipeline you can iterate.
Define scope in three dimensions. Competency scope:Course/task scope:Evidence scope:
Set acceptance criteria for a defensible skill claim before modeling. Examples: minimum number of aligned assessment items, recency window, required rubric criteria, and a confidence threshold that triggers human review. Also define abstention rules: when data is too incomplete or conflicting, the system should say “insufficient evidence.” This is a hallmark of responsible competency inference.
Finally, draft the first end-to-end pipeline sketch. At MVCM level, it can be simple and still robust: (1) ingest logs and assessment tables, (2) normalize identifiers and timestamps, (3) build sessions and episodes, (4) create an evidence table keyed by learner-course-competency, (5) compute interpretable features and provisional skill levels, (6) attach confidence/uncertainty and data completeness, (7) validate via rubric sampling and reviewer workflow, and (8) publish a competency map as a dashboard/export with an audit trail. If you can run this loop on a small scope and get stakeholder sign-off, you have a foundation that can scale.
1. What is the core problem Chapter 1 says competency mapping must solve when using LMS logs?
2. When defining the business question and competency use case, what key consideration is emphasized?
3. Why does Chapter 1 recommend creating an evidence table from raw logs?
4. Which set of qualities best matches the chapter’s definition of “defensible” skill claims?
5. What tradeoff mindset does Chapter 1 highlight as necessary for building a trustworthy competency mapping pipeline?
Competency mapping from LMS logs only works when the “skill language” is stable, measurable, and connected to learning evidence. In Chapter 1 you modeled raw events into learning activity sequences; in this chapter you’ll build the scaffolding those sequences will map onto: a competency framework (what you claim learners can do) and a skill graph (how those claims relate and accumulate).
Think of this chapter as creating the contract between your data pipeline and your reporting layer. The framework defines the vocabulary and proficiency levels. The alignment matrix defines which course activities can produce evidence for which skills. The competency graph then organizes those skills into clusters and prerequisites so you can reason about progression and gaps. Finally, rubric anchors ensure you can validate inferred skills with human review and consistent scoring.
Engineering judgment matters here. If you make skills too broad, you’ll get inflated claims that are hard to validate (“Data Science”). If you make them too granular, you’ll drown in maintenance and produce brittle analytics (“Can set a specific parameter in tool X version Y”). Your goal is a usable middle: skills that are observable in course behavior and meaningful to employers, HR/L&D, and learners.
Practice note for Select a framework strategy (internal, ESCO, O*NET, hybrid): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write measurable skill statements and proficiency levels: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Map courses and activities to skills (alignment matrix): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a competency graph with prerequisites and clusters: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Establish rubric anchors for validation: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Select a framework strategy (internal, ESCO, O*NET, hybrid): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write measurable skill statements and proficiency levels: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Map courses and activities to skills (alignment matrix): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a competency graph with prerequisites and clusters: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Establish rubric anchors for validation: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Before choosing a framework strategy (internal, ESCO, O*NET, or hybrid), align on definitions. A task is a concrete action a learner performs: “Submit a SQL query that joins two tables.” A learning activity is the LMS representation of tasks and practice: video watch, quiz attempt, coding lab run, peer review. A learning outcome is what the course promises: “Explain join types and apply them.” A skill is a reusable capability that transfers across contexts: “Write relational joins.” A competency is a broader bundle of skills plus context and standards: “Analyze structured datasets to answer business questions.”
In competency mapping, your inference engine will connect evidence (observed behavior + results) to skill claims. That only works if each skill statement is measurable and has clear boundaries. Use wording that implies an observable artifact: “Can implement X” beats “Understands X.” Avoid mixing outcomes (course promises) with skills (transferable capabilities). Also avoid embedding tools unless your program is explicitly tool-specific. “Create a pivot table in Excel” is tool-specific; “Summarize data using pivot-style aggregations” is transferable.
Framework strategy is often political as much as technical. An internal framework fits your courses but may not translate to job roles. ESCO and O*NET improve external portability but can be mismatched to your curriculum granularity. A hybrid approach is common: adopt external identifiers where they match, keep internal skills where you need specificity, and maintain crosswalk tables. Practical outcome: decide what is the “source of truth” identifier for each skill and how you will export skill claims (internal IDs plus optional ESCO/O*NET mappings).
Your framework is effectively a taxonomy: a controlled list of skills/competencies with naming conventions, hierarchy, and lifecycle rules. Start with granularity. A useful rule is to design skills at the level where multiple activities in the LMS could produce evidence, and where employers would recognize the claim. For example, “Write basic SELECT queries” is often a better skill than “Use WHERE clause,” because you can observe it across quizzes, labs, and projects.
Naming should be consistent and action-oriented. Use a verb + object format: “Configure access controls,” “Interpret confidence intervals,” “Write unit tests.” Avoid synonyms and overlapping labels (“Debug code” vs “Troubleshoot code”) unless you explicitly define a relationship. Add short descriptions and exclusions (what it is not) to reduce drift when multiple SMEs tag content.
Versioning is non-negotiable once you start producing analytics and reports. Treat the taxonomy as a product artifact: every skill has an immutable ID and a mutable label/description. When meaning changes materially, create a new version (or a new skill) rather than editing in place. Maintain a change log with: who changed what, why, which courses are impacted, and how historical skill claims should be interpreted. This is crucial for auditability when learners use competency maps for career mobility.
From an engineering perspective, implement a simple schema: Skill(skill_id, name, description, status, version, external_refs, created_at, retired_at). Keep statuses like Draft/Active/Deprecated/Retired. Practical outcome: your alignment matrix and graph edges can reference stable skill_ids, and dashboards can filter by Active skills only.
Skill statements become actionable when paired with proficiency levels and observable indicators. Choose a proficiency scale that matches your evidence quality. A 3-level scale (Foundational/Intermediate/Advanced) is often enough for LMS-based inference; 5+ levels can imply a precision you cannot defend with clickstream and typical assessments.
Write each level as a measurable performance statement and attach indicators you can actually observe. For “Write relational joins,” indicators might include: correctness on join questions, successful lab execution, ability to resolve ambiguous requirements in a project rubric. Avoid indicators that require mind-reading (“understands,” “appreciates”). Use rubric anchors: concrete examples of what work looks like at each level (sample submissions, common errors, borderline cases). Anchors enable validation workflows later—reviewers can calibrate quickly and score consistently.
Design levels to be non-overlapping. A practical approach is: Level 1 = performs with scaffolding (templates, hints), Level 2 = performs independently on standard problems, Level 3 = adapts to novel constraints and explains tradeoffs. Then map which LMS evidence types can support each: quizzes may support Level 1–2; capstone projects and peer-reviewed artifacts better support Level 2–3.
Engineering judgment: don’t force every skill into the same depth. Some skills are binary in your program (e.g., “Complete mandatory compliance module”). Others are nuanced. It’s acceptable to have different scales by skill family if you document it and keep reporting consistent.
The alignment matrix links courses, modules, and activities to skills and expected proficiency levels. You can build it via SME tagging, automated suggestions, or a hybrid. SME tagging is higher precision initially but slow and inconsistent without guidelines. Automated suggestions (NLP over item text, metadata, and outcomes; clustering of activity sequences; similarity to previously tagged items) scale better but must be explainable and reviewable.
A practical hybrid workflow is: (1) SMEs tag a seed set of representative activities per course, (2) the system suggests skills for the remaining activities with confidence scores and rationales (keyword matches, embedding similarity, historical co-tag patterns), (3) SMEs accept/reject in a review UI, and (4) your pipeline writes the approved mappings to a versioned alignment table.
When mapping, be explicit about the mapping type: teaches (instructional content), practices (formative), assesses (summative). Many teams incorrectly treat a video watch as evidence of skill; it’s usually “teaches,” not “demonstrates.” For inference, prioritize “assesses” and high-quality “practices” (graded labs, simulations) as evidence edges.
Practical outcome: your alignment matrix becomes the lookup layer used by your inference models—when an event occurs (quiz_attempt, lab_pass, project_score), you can attribute it to a skill with an intended level and evidence weight. Common mistakes include over-tagging (everything maps to everything) and failing to record negative mappings (activities that should not contribute).
Once you have a stable taxonomy and alignment matrix, model the competency framework as a graph to support pathway reasoning: prerequisites, clusters, and progression. Start simple. Use nodes for skills (and optionally competencies as higher-level aggregates). Use edges for relationships such as prerequisite-of, part-of, related-to, and co-occurs-with. Keep relationship types limited and well-defined; too many edge types confuse both humans and downstream algorithms.
Prerequisites deserve special care. A prerequisite is not “usually taught before,” it is “required to succeed.” Validate prerequisites by combining SME input with data: learners who fail skill B often show weak evidence for skill A. Represent prerequisites as directed edges (A → B). Then you can compute learning paths, detect missing foundations, and create cluster views (e.g., “SQL Foundations” community).
Implementation options: a property graph (Neo4j), a relational adjacency table, or a graph layer built in your analytics warehouse. For many teams, a relational model is sufficient: SkillEdge(from_skill_id, to_skill_id, type, weight, source, version). Add fields for source (SME, inferred, imported from ESCO/O*NET) and weight (strength of relationship). Clustering can be derived (community detection) or curated as “skill families.”
Practical outcome: the graph lets you roll up evidence. If a learner demonstrates several leaf skills, you can infer higher-level competencies with transparent logic (e.g., threshold rules) and show “because” explanations in dashboards: “Claimed competency X because skills A, B, C were demonstrated in assessed artifacts.”
Competency frameworks fail more often from governance gaps than from modeling errors. Assign clear ownership: a product owner for the taxonomy, SMEs for domain accuracy, and an analytics/ML owner for alignment and inference integration. Define a release cadence (monthly/quarterly) and a lightweight request process for adding, deprecating, or changing skills.
Change control must be explicit because your skill claims affect learners and stakeholders. For every proposed change, require: rationale, impacted courses/activities, backward compatibility plan, and migration steps for mappings. Store an audit trail for taxonomy versions, alignment approvals, and graph edits. If you later need to explain why a learner’s competency map changed, you should be able to trace it to a specific release and mapping decision.
Governance also includes validation readiness. Rubric anchors (from Section 2.3) should be stored alongside skill definitions and referenced in reviewer workflows. When you run sampling-based audits (e.g., review 50 artifacts that triggered “Intermediate SQL joins”), reviewers need consistent anchors to accept/reject claims. Record reviewer decisions as labeled data; over time, this becomes training data for better automated suggestions and for monitoring bias across cohorts.
Practical outcome: with governance in place, you can confidently publish dashboards and HR/L&D-friendly exports knowing that each skill has a stable ID, documented meaning, approved mappings, and traceable evidence. Without it, competency maps become a moving target and lose trust—even if the underlying data pipeline is excellent.
1. Why does competency mapping from LMS logs require the chapter’s “skill language” to be stable and measurable?
2. In Chapter 2, what is the main purpose of the alignment matrix?
3. Which pairing correctly matches each component to its role in the chapter’s “contract” between the data pipeline and reporting layer?
4. Which skill statement granularity best fits the chapter’s guidance for usable analytics?
5. What problem do rubric anchors primarily solve in this chapter’s process?
Before you can infer competencies from learning data, you need instrumentation you can trust and a data model your analytics can grow with. In practice, LMS exports are messy: they differ by vendor, change over time, and often blur the line between “what the learner did” and “what the system logged.” This chapter focuses on turning those raw logs into an event stream you can analyze as sequences of learning activities, while staying compatible with xAPI/LRS patterns and (where relevant) Caliper-style events.
The goal is not to build a perfect, universal schema. The goal is a canonical event model that is stable, interpretable, and traceable back to raw sources. Your downstream tasks—feature engineering for engagement and mastery, time-based signals like spacing and recency, and validation workflows that involve rubrics and human review—depend on this foundation. A mis-modeled “attempt,” a missing identifier, or inconsistent time handling can make skill claims look precise while being wrong.
We will make concrete engineering choices: how to normalize exports, how to design identifiers (learner, content, attempt), how to compute features (dwell time, retries, hints), how to represent assessments (items, partial credit), and how to prepare analysis-ready datasets for inference and validation. The practical outcome is a pipeline that yields dependable learning activity sequences and evidence tables that can be joined to a competency framework later without rework.
As you read the sections, think like an auditor: for any metric you plan to show on a dashboard, can you explain exactly which events created it, which assumptions were made, and which cases are excluded?
Practice note for Normalize LMS exports into a canonical event model: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design identifiers for learners, content, and attempts: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Engineer features for engagement and mastery signals: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Handle time: pacing, spacing, and recency: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Prepare datasets for inference and validation: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Normalize LMS exports into a canonical event model: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design identifiers for learners, content, and attempts: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Engineer features for engagement and mastery signals: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
LMS exports are typically batch files (CSV, JSON, database extracts) built for operations, not for inference. They might include tables like “course progress,” “gradebook,” “quiz attempts,” “content views,” and “forum posts.” Each table has its own implicit semantics and often lacks a consistent event grain. For example, “time spent” may be computed by the LMS using idle-time heuristics you cannot verify, while “views” might be aggregated counts rather than individual interactions.
xAPI and Caliper aim to represent learning interactions as event statements. xAPI uses an actor–verb–object pattern with optional result and context; Caliper has an event envelope with actors, actions, and objects aligned to IMS profiles. The advantage of these standards is conceptual clarity: a learner (actor) did something (verb/action) to something (object), at a time, in a context. The drawback is that most LMS exports are not truly emitted as xAPI or Caliper, and vendor implementations can be partial or customized.
Your engineering judgment: treat LMS exports as raw facts, and map them into a canonical event stream that resembles xAPI/Caliper enough to support an LRS-style design, without forcing every field to match the spec. Common mistake: over-fitting your schema to one vendor’s tables, then discovering a second LMS cannot populate key fields. Another mistake: importing “progress percentage” as if it were an event; it is usually a derived state and should be computed from lower-level events when possible.
Practical workflow: inventory every source table, decide the event grain you want (e.g., “attempt submitted,” “item responded,” “content opened,” “hint requested”), and build deterministic mapping rules. Keep the original record IDs and file lineage so that any analyst can trace a modeled event back to the source export. This is what makes later competency validation defensible.
A canonical schema is your contract between instrumentation and analysis. A reliable pattern is a simplified xAPI-like event model with five parts: actor, verb, object, result, and context. You will store this as an append-only event table, even if your raw data arrives as multiple relational exports.
Actor identifies the learner (and sometimes instructor or system). Verb is a controlled vocabulary of actions you will analyze (opened, started, attempted, submitted, answered, hinted, completed, posted). Object is what the action is performed on: course, module, page, video, quiz, question item, assignment, forum thread. Result captures outcomes such as score, correctness, completion status, duration, or response. Context provides the “where/when/why”: course run, enrollment, device, session, attempt number, and any competency tags available from the LMS or content system.
Design for sequences: store event_time, ingest_time, and a monotonically increasing event_id. Then you can build learning activity sequences by sorting events per actor within a course run. Common mistake: storing only date-level timestamps (or only the “last updated” field), which destroys pacing and spacing signals. Another mistake: mixing derived features (like “total time in week”) into the event table; keep events atomic and compute rollups in a feature layer.
Practical outcome: once all sources map into the same columns, you can compute features consistently across content types. For example, “attempt_count” becomes a generic metric derived from verb=attempted/submitted regardless of whether it came from a quiz engine or an assignment tool. This consistency is what makes your later competency mapping comparable across courses and cohorts.
Skill inference is only as trustworthy as your identifiers. In LMS exports, learners may appear as numeric IDs, emails, usernames, or SIS identifiers, and the same person can change email or have multiple accounts. Identity resolution is the process of linking these representations to a stable learner key. Do it explicitly and document the rules; otherwise, you will silently split a learner’s evidence across keys (false under-performance) or merge two learners (false competence).
Start with a hierarchy of identifiers: prefer an immutable SIS/student ID if available, then LMS internal user ID, and use email/username only as a last resort. Maintain an identity_map table with: raw_identifier, identifier_type, canonical_learner_id, first_seen_time, last_seen_time, and source_system. Use deterministic matching (exact matches, normalized emails) before probabilistic methods (name similarity). When you use probabilistic linking, store the match score and require human review for uncertain links.
Pseudonymization is essential for privacy and for safe analysis environments. Replace direct identifiers with a stable pseudonymous key (e.g., HMAC-SHA256 of the canonical ID with a rotating secret). Common mistake: using a plain hash without a secret, which is reversible via dictionary attacks on emails. Another mistake: generating a new pseudonym per export, which breaks longitudinal analysis. Your goal is stable within the analytics environment, but not reversible outside it.
Practical workflow: build two zones—(1) a restricted “PII vault” holding the identity map and secrets, and (2) an analytics dataset where actor_id is pseudonymous. Ensure event data carries only the pseudonymous actor_id plus minimal demographics needed for segmentation (and only where policy allows). This separation makes later validation workflows (sampling for human review) possible without exposing full identities broadly.
Once events are normalized, you can engineer features that act as engagement and mastery signals. The key is to define features that are interpretable and robust to logging noise. Start with “attempts” as first-class: an attempt is not just a score row; it is a sequence of events that begins with started/attempted and ends with submitted/completed/timeout. Create an attempt_id that groups those events for a specific actor and object (e.g., quiz or item). If the LMS does not provide attempt IDs, derive them using rules: new attempt when a start event occurs after a submission or after a long inactivity gap.
Dwell time is useful but fragile. Prefer event-based duration: time between “opened” and “closed/completed,” with caps to avoid idle inflation (e.g., clamp single-page dwell at 20 minutes unless there is interaction). If you only have periodic “heartbeat” pings, compute sessionized duration: define sessions per actor with an inactivity threshold (commonly 15–30 minutes) and allocate time to the last active object carefully. Common mistake: summing overlapping durations across tabs or devices; if concurrency is possible, treat total time as an upper bound and store both “active_time_estimate” and “elapsed_time.”
Retries and hints are powerful mastery indicators when interpreted correctly. A high retry rate can mean persistence, confusion, or poor item quality. So store both counts and outcomes: retry_count, time_between_retries, and whether the final attempt was correct. For hints, store hint_count and hint_timing (before first response vs. after an incorrect response). A learner who requests a hint after an error may be calibrating; a learner who requests immediately may be gaming or may need scaffolding.
Practical outcome: these features become evidence inputs to your competency framework later. They also support validation: when reviewers sample learners for a rubric-based check, you can show the attempt timeline and hint/retry patterns that led to the inferred skill claim.
Assessments often carry the strongest signals for competency inference, but only if modeled at the right level. Course-level grades are too coarse: they mix participation, deadlines, collaboration, and instructor discretion. Instead, model assessments as a hierarchy: assessment (quiz/assignment) → attempt → item (question/rubric criterion) → response. When you can reach item level, you can connect evidence to specific skills (e.g., “SQL joins” rather than “Module 4 quiz”).
Represent scores with both raw_score and max_score, and compute percent_score downstream. Store scoring status (graded, pending, dropped, exempt). For partial credit, store per-item points earned and the rubric/criterion ID if available. If the LMS provides only overall attempt score, still store it, but mark item-level coverage as missing so later inference can weight it appropriately.
Be careful with multiple attempts and policies: highest-score, latest-score, average, or mastery-based rules. Do not bake the policy into the raw evidence table. Store all attempts, then compute policy-specific rollups in a feature layer. Common mistake: keeping only the final gradebook value, which erases learning trajectory and retries—critical signals for both mastery and pacing.
Practical workflow: build an assessment_items dimension table with stable item identifiers, item type (MCQ, numeric, short answer), tags (learning objective/competency), and version. Versioning matters: if an item changes, scores are not comparable. The practical outcome is a dataset that supports interpretable methods later (e.g., per-skill evidence aggregates) and makes human review feasible because reviewers can see exactly which items supported a skill claim.
Competency inference requires context: the same behavior can mean different things in different cohorts. A learner with low dwell time might be highly proficient (fast reader) or disengaged; without baselines, you cannot tell. Segmentation lets you compare like with like and detect bias. Typical segments include course run (term), modality (self-paced vs. instructor-led), program track, prior knowledge proxies (placement test), and access constraints (time zone, device type) where ethically and legally appropriate.
Start by defining a cohort_id in context, tied to a specific course offering and time window. Then compute baseline distributions for key features: attempt_count, median item score, retry_rate, hint_rate, spacing (days between sessions), and recency (time since last activity). Store baselines as summary tables by cohort and, when needed, by segment (e.g., new vs. returning learners). Common mistake: comparing learners across different course versions or instructors without accounting for item changes and grading policies.
Baseline comparisons also support validation and fairness checks. If one segment systematically receives fewer hints (because hints are hidden on mobile) or has longer gaps (because of weekend work schedules), your model may incorrectly infer lower competency. The practical outcome is twofold: (1) better features (z-scores within cohort rather than global thresholds), and (2) defensible reporting that communicates uncertainty and avoids overstating skill gaps that are actually artifacts of access or design.
To prepare datasets for inference and validation, finalize three layers: an event layer (canonical events), a feature layer (per actor–object–time aggregates with clear definitions), and an evidence layer aligned to competency tags (per actor–competency evidence rows). This separation keeps your pipeline auditable and makes later human review workflows efficient.
1. Why does Chapter 3 emphasize building a canonical event model instead of aiming for a perfect universal schema?
2. What is the key risk of mixing raw log events with derived signals in the same dataset?
3. Which identifier design choice best aligns with the chapter’s guidance for dependable analytics?
4. According to the chapter, how should time be handled to support competency inference and validation?
5. What is a recommended modeling practice for assessments to avoid misrepresenting learner evidence?
Skill inference from LMS logs succeeds or fails on one thing: whether stakeholders can understand, challenge, and improve the logic. If a manager, instructor, or learner cannot trace a competency claim back to concrete evidence, you will struggle to validate it, calibrate it, or defend it when decisions are made. This chapter focuses on interpretable methods that scale—from a rules-based baseline to probabilistic and sequence-based inference—while keeping the “why” of each score explainable.
You will implement a transparent baseline first, because it establishes shared definitions (what counts as evidence) and surfaces logging gaps early. Then you’ll layer confidence scoring, light psychometrics, and multiple evidence sources into a single skill score without turning your system into a black box. Finally, you’ll run calibration and error analysis so your competency map becomes an auditable product rather than a speculative model.
Throughout the chapter, assume a competency framework already links skills → tasks → observable evidence (lesson completions, time-on-task, quiz items, submissions, peer reviews, external artifacts). Your job is to turn those signals into skill claims with: (1) traceability, (2) uncertainty, and (3) actionable feedback loops for improvement.
Practice note for Implement a rules-based baseline (transparent and fast): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Add probabilistic inference with confidence scoring: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Incorporate assessment psychometrics or IRT-lite signals: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Connect multiple evidence sources into a single skill score: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Run calibration checks and error analysis: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Implement a rules-based baseline (transparent and fast): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Add probabilistic inference with confidence scoring: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Incorporate assessment psychometrics or IRT-lite signals: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Connect multiple evidence sources into a single skill score: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Run calibration checks and error analysis: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
The fastest path to a usable competency map is a rules-based baseline. “Rules-based” does not mean simplistic; it means each skill claim is computed from explicit mappings and thresholds that anyone can inspect. Start with a table that maps evidence events to skills and assigns each event a weight and minimum quality checks. For example: a “passed quiz on joins” event supports SQL Joins; a “viewed video” event supports Exposure but not mastery.
In practice, rules should handle three engineering realities: noisy logs, inconsistent engagement patterns, and missing data. Use thresholds that defend against accidental clicks. For time-on-page, require a minimum dwell time and a maximum cap (to avoid counting idle tabs). For completions, verify both “start” and “complete” events when available. For assessments, prefer item-level evidence (questions tagged to skills) over course-level grades.
Common mistakes include setting thresholds without sampling real learners, mapping course completion directly to mastery, and ignoring alternative pathways (some learners skip videos and rely on projects). The practical outcome of this baseline is not perfect inference—it is a transparent starting point that enables stakeholder review, faster data quality fixes, and a benchmark to compare more advanced methods against.
Once you have rule-based signals, convert them into a probabilistic mastery estimate that includes confidence scoring. Bayesian updating is ideal because it is explainable: you start with a prior belief about mastery and update it as evidence arrives. For each skill, track a probability P(mastery). Initialize it with a prior based on context (e.g., role, pretest, past courses) or a neutral prior (e.g., 0.2 if most learners are novices).
Each evidence event updates the probability using likelihoods: how probable is observing this event if the learner is mastered versus not mastered? A strong signal like “correct on a difficult item tagged to the skill” should shift the probability more than “watched a video.” If you lack psychometric detail, you can still set reasonable likelihood ratios and refine them through calibration. The key is to store, for each update, the evidence that moved the needle so your dashboards can explain: “Mastery increased from 0.55 to 0.72 due to two correct items and a verified project submission.”
Engineering judgment matters most in priors and evidence strength. A common failure mode is overconfident posteriors from overly aggressive likelihood ratios. Treat Bayesian inference as a controlled way to express uncertainty, not a trick to inflate certainty. The practical outcome is a mastery probability you can threshold for decisions (e.g., “≥0.8 = proficient”) while still showing the underlying uncertainty and evidence trail.
Rules and Bayesian updates treat evidence as a set; sequence models treat it as a story. Many learning behaviors are temporal: learners practice, struggle, revisit content, then succeed. Markov models and Hidden Markov Models (HMMs) offer interpretable sequence inference without deep learning complexity. In a Markov model, you model transitions between observable states such as inactive → studying → practicing → testing. In an HMM, you model transitions between hidden states such as not mastered → partial → mastered, while observing events like quiz outcomes and practice attempts.
An HMM is especially useful when you want to explain learning progression: “The model believes the learner is in the ‘partial’ state because they alternate between correct and incorrect responses and frequently rewatch prerequisite content.” You define transition probabilities (how likely a learner moves from partial to mastered) and emission probabilities (how likely each event is in each mastery state). Start with simple, hand-initialized parameters and refine them with data; this preserves interpretability while improving fit.
Common mistakes include fitting sequence models to raw clickstream noise without event abstraction, allowing too many states, and ignoring prerequisite structure (mistaking confusion on an advanced topic for lack of a basic skill). The practical outcome is a progression-aware inference that can drive coaching: identify learners stuck in “partial” and recommend targeted practice or prerequisite review.
LMS logs are indirect; artifacts are direct. When you can score learner work products—projects, essays, code submissions, presentations—you gain evidence that is both explainable and defensible. The key is to align artifact scoring to rubrics that map cleanly to skills. A rubric criterion should be specific enough to evaluate consistently (e.g., “Uses joins correctly and avoids Cartesian products”) and linked to one or more skills in your framework.
Build an “artifact evidence pipeline” that treats rubrics as first-class data. Store rubric version, evaluator type (human, auto-grader, peer), inter-rater agreement metrics if available, and the exact excerpts or outputs that justify the score. This addresses a common stakeholder objection: “Show me what they did.” For interpretability, convert rubric scores into mastery contributions with transparent rules (e.g., a 4/5 on criterion X adds +0.15 to P(mastery) with a confidence modifier based on evaluator reliability).
Common mistakes include using course grades as a proxy for skill, failing to track rubric versions (making longitudinal comparisons invalid), and treating peer scores as equally reliable as expert scores. The practical outcome is skill claims grounded in observable work, enabling HR/L&D-friendly reporting: “Skill verified by rubric-aligned project evidence,” not just “completed the module.”
Interpretable machine learning becomes useful after you have a baseline and reliable features. The objective is not maximum accuracy; it is a model that provides stable, inspectable relationships between evidence and skill outcomes. Logistic regression is the workhorse: it predicts the probability of mastery (or passing a skill check) from features such as tagged item accuracy, number of successful practice attempts, time-on-task within bounds, recency, and artifact rubric scores.
Generalized Additive Models (GAMs) extend this with smooth curves (e.g., the relationship between practice attempts and mastery may plateau). Monotonic models add an important constraint for explainability: they enforce that “more correct answers should not reduce mastery probability,” which prevents counterintuitive behavior caused by spurious correlations. These methods also integrate “IRT-lite” signals: include item difficulty proxies (historical p-values) and discrimination proxies (how well an item separates higher from lower performers) as features or weights, without implementing full IRT.
Common mistakes include throwing in every click feature (creating fragile models), ignoring missing data mechanisms (non-attempts can mean many things), and optimizing for AUC while producing uninterpretable coefficients. The practical outcome is a single, defensible skill score that integrates multiple evidence sources while remaining explainable at the feature level.
A competency map must communicate uncertainty as clearly as it communicates mastery. Two learners with the same score may differ in confidence due to evidence quantity, quality, and agreement. Always separate the estimate (e.g., P(mastery)=0.76) from the confidence in that estimate. Confidence can be driven by: number of independent evidence sources, reliability of each source, recency, and internal consistency (do assessments and artifacts agree?).
Introduce an explicit “unknown” state. If evidence is sparse, contradictory, or low quality, output “unknown” rather than forcing a low mastery label. This is essential for fairness and operational integrity: missing logs, inaccessible content, or alternative learning pathways should not silently penalize learners. Implement guardrails such as minimum evidence requirements before declaring proficiency, and contradiction checks that trigger review workflows (e.g., high quiz performance but failed project rubric).
Common mistakes include presenting a single score without uncertainty, using confidence as a cosmetic number disconnected from evidence quality, and hiding unknowns to satisfy reporting expectations. The practical outcome is a system that supports human review: uncertain cases are routed for sampling and rubric checks, while high-confidence claims are ready for dashboards, exports, and HR/L&D reports that withstand scrutiny.
1. Why does the chapter recommend implementing a rules-based baseline first?
2. What is the main risk if stakeholders cannot trace a competency claim back to concrete evidence?
3. What does adding probabilistic inference with confidence scoring contribute beyond a rules-based baseline?
4. According to the chapter, what combination best describes the goal of turning LMS signals into skill claims?
5. Why does the chapter emphasize running calibration checks and error analysis after combining evidence into a single skill score?
By Chapter 4 you can infer competencies from LMS logs and assessments in a way that is explainable and operational. Chapter 5 answers the next question stakeholders will immediately ask: “How do we know it’s right, for whom is it right, and how do we keep it right as courses evolve?” Validation is not a one-time “accuracy score.” It is a study design problem (what counts as truth), an operations problem (who reviews what, and when), and an engineering judgement problem (how you set thresholds and handle uncertainty).
In practice, competency claims become decisions: whether a learner gets a badge, whether a manager can trust a dashboard, whether HR can use an export for internal mobility, or whether L&D should assign remediation. Your validation approach must therefore be aligned to the decision risk. A low-stakes dashboard can tolerate more uncertainty than an automated credential. This chapter gives you a practical workflow: design a sampling plan, build human-in-the-loop reviews with reliability checks, evaluate metrics aligned to decisions, audit subgroup performance, and establish monitoring and retraining cadence.
The goal is not to prove the system is perfect. The goal is to quantify uncertainty, reduce preventable error, document known limitations, and continuously improve the competency map and inference rules so they remain credible for educators and defensible for workforce use.
Practice note for Design a validation study and sampling plan: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Run human-in-the-loop reviews and inter-rater reliability: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Evaluate accuracy with metrics aligned to decisions: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Audit bias and perform subgroup performance checks: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a model monitoring and retraining cadence: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design a validation study and sampling plan: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Run human-in-the-loop reviews and inter-rater reliability: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Evaluate accuracy with metrics aligned to decisions: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Validation starts with “ground truth,” but in learning analytics ground truth is rarely absolute. Your strategy is to define reference labels that are good enough for the decision and to document what they represent. A robust approach uses multiple label sources because each has blind spots. Rubric-based human scoring captures authentic performance but is time-consuming. Exams are scalable but may overemphasize recall. Workplace signals (tickets closed, code review outcomes, supervisor ratings) are close to real job competence but are often noisy and delayed.
Operationally, write a short “labeling spec” that states: the competency definition, evidence allowed, scoring scale (e.g., not demonstrated / emerging / proficient), and exclusions (e.g., do not infer teamwork from forum quantity alone). Then build a validation study and sampling plan. Avoid convenience samples such as “only top learners” or “only those who finished.” Instead stratify by course module, activity type, inferred competency level, and recency. Oversample edge cases: learners near decision thresholds, learners with sparse logs, and learners with unusual pathways (e.g., high assessment score but low engagement).
Practical sampling recipe: choose a target of 200–500 labeled learner-competency pairs per major course/track for an initial study. Split the sample into (1) a stable baseline cohort for longitudinal comparison, (2) a refresh sample each release cycle, and (3) a “challenge set” of rare or high-risk cases. For each pair, package the rater view as an evidence bundle: key submissions, assessment items, timestamps, and a short narrative of the inferred rationale. Common mistakes include letting raters see the model’s final label (bias), mixing rubric versions, and failing to track which course content version produced the evidence. Treat ground truth as a controlled artifact, not an ad-hoc spreadsheet.
Choose metrics based on what decision you are enabling. If your competency map triggers an intervention (extra practice, tutor outreach), false positives waste time but may be acceptable; false negatives miss support. If it grants a credential or feeds HR systems, false positives are much more expensive. That is why you should report at least (a) classification performance, (b) probability quality, and (c) added value over a baseline.
Precision/recall are your core. Precision answers: when we claim “proficient,” how often is that correct? Recall answers: of truly proficient learners, how many did we detect? Use F1 only if you truly want a single number; otherwise show precision and recall at the threshold used in production. For multi-level rubrics (emerging/proficient), use macro-averaged metrics or evaluate the specific decision boundary (e.g., proficient vs not).
Calibration matters when you output confidence scores. A well-calibrated model means that items predicted at 0.8 confidence are correct ~80% of the time. In dashboards, calibration supports honest uncertainty; in automation, it supports stable thresholds. Use reliability diagrams and compute calibration error (e.g., ECE) by competency and by cohort. If calibration is poor, you can recalibrate with methods like Platt scaling or isotonic regression on a held-out labeled set, without changing the underlying interpretable rules.
Lift answers the business question: are you doing better than a simple baseline? Compare against heuristics like “completed course = proficient” or “final exam score > 80%.” Lift can be expressed as improvement in precision at a fixed recall, or reduction in review workload: “We can capture 90% of true proficient cases by manually reviewing only the top 30% highest-confidence claims.” A common mistake is celebrating high accuracy in imbalanced settings (most learners are “not yet proficient”). Always include the base rate and a confusion matrix tied to the actual operational threshold.
Human review is not just a checkpoint; it is a measurement system. If raters disagree heavily, you cannot interpret model “errors” reliably because the labels are unstable. Start by training reviewers on the rubric with worked examples and a short calibration session. Then measure inter-rater reliability on an overlapping subset of items before scaling up.
Cohen’s kappa is a practical agreement metric for two raters correcting for chance agreement. For more than two raters, use Fleiss’ kappa or Krippendorff’s alpha, but keep your process simple: two primary raters per item and an adjudicator for conflicts. Interpret kappa cautiously: values around 0.6 can be acceptable in complex performance tasks; lower values indicate the rubric or evidence bundle is ambiguous. Also track raw agreement, because kappa can look low when class prevalence is extreme.
Implement a consensus workflow that improves both quality and speed:
Common mistakes include letting raters use different evidence views, changing rubric wording mid-study, and failing to log rater IDs and timestamps. Your practical outcome should be a repeatable review pipeline that produces: stable labels, an audit trail, and a growing library of exemplars that improve future mapping and inference rules.
Fairness begins with representation: are you validating on the same kinds of learners who will be affected by the system? Your sampling plan should include subgroup coverage across demographics (where legally and ethically collected), access patterns (mobile vs desktop, low bandwidth), learner status (part-time vs full-time), and prior preparation. If you cannot collect sensitive attributes, use proxy groupings cautiously (e.g., time zone, device type) and focus on outcomes like differential error rates rather than identity categories.
Once representation is acceptable, test for differential performance. Report precision, recall, and calibration by subgroup for each high-impact competency. Look specifically for:
Connect the results to plausible mechanisms. LMS logs are affected by access and behavior: learners with limited connectivity may have fewer events; learners using accessibility tools may generate different click patterns; some groups may prefer fewer but longer sessions. If your inference rules treat “frequency of clicks” as evidence, you may inadvertently penalize efficient or constrained learners. Mitigations include reweighting evidence toward outcomes (rubric-scored artifacts), normalizing engagement features (e.g., per active minute), adding “missingness-aware” logic, and requiring multiple evidence types before declaring proficiency.
Common mistakes are reporting a single global fairness score, ignoring uncertainty due to small subgroup sizes, and treating fairness as a one-time pre-launch task. Fairness checks belong in every release review and should produce actionable change requests: update mappings, adjust thresholds, or expand the evidence bundle for certain competencies.
Even if your model is validated today, it will degrade when the learning environment changes. In competency mapping, drift often comes from two sources: content drift (course redesigns, new assessments, changed grading rubrics) and cohort drift (different learner backgrounds, new prerequisites, policy changes, seasonality). Your monitoring plan should explicitly track both.
Start with instrumentation. Version your course content and your competency mapping rules. Log the mapping version used for each inference. Then monitor leading indicators weekly or per cohort:
Use simple, explainable drift detectors first: population stability index (PSI) on key signals, KL-divergence on event types, and control charts on proficiency rates. Set alert thresholds that are tied to investigation, not panic—for example, PSI > 0.25 triggers review of content changes, and a 2-sigma shift in proficiency rate triggers a label spot-check.
Finally, define a retraining or recalibration cadence that matches the pace of change. For many programs, a quarterly review plus an ad-hoc review after major course releases is enough. The common mistake is retraining on new logs without new labels; that can amplify hidden bias. Prefer recalibration and rule tuning backed by fresh human-reviewed samples, and treat major content changes as a “new model” requiring a mini validation study.
Continuous improvement is not “keep tweaking.” It is a controlled feedback loop that updates competency mappings, evidence weights, and thresholds based on validated findings. The most effective loop connects three artifacts: (1) validation results, (2) model decision logic, and (3) stakeholder outcomes (learner support actions, credentialing decisions, HR report usage).
Implement a change management workflow:
Threshold setting deserves explicit engineering judgement. Prefer thresholds that align to action capacity: if mentors can only review 50 learners/week, choose a threshold that yields a manageable queue while maintaining high precision. Use “gray zones” to avoid overclaiming: automatically label only high-confidence proficiency; route medium-confidence cases to human review; label low-confidence as “insufficient evidence” rather than “not skilled.”
Common mistakes include updating thresholds without recalculating calibration, changing mappings without updating rater guidance, and failing to communicate that a proficiency rate shift may be a model change, not a learning change. Done well, your feedback loop produces a competency system that remains interpretable, fairer over time, and trusted enough to be used in dashboards, exports, and HR/L&D reports.
1. Why does Chapter 5 argue that validation is not a one-time “accuracy score”?
2. How should validation be aligned to the way competency claims are used?
3. Which workflow best represents the chapter’s recommended validation approach?
4. What is the purpose of measuring inter-rater reliability in human-in-the-loop reviews?
5. What does the chapter recommend when auditing fairness of competency inference?
By this point in the course, you have a competency model, inference logic, and a validation workflow grounded in evidence from LMS logs and assessments. Chapter 6 is about turning those artifacts into products people can use to make decisions: learners planning next steps, managers coaching, and L&D reporting impact. Deployment is not “publish a dashboard and walk away.” It is an engineering and change-management exercise: designing outputs that match decision contexts, integrating with HR and credentialing systems, and writing governance that keeps the system trustworthy over time.
A strong competency map deployment starts with explicit product boundaries. Your map is not an employee surveillance tool, and it is not a hiring algorithm. It is an evidence-backed learning signal that helps people navigate skill development. That framing should shape everything: what you display, how you express uncertainty, who can see what, and how recommendations are generated. The most common failure mode is shipping “perfectly computed” skill scores that nobody trusts because they are opaque, misaligned to roles, or inconsistent with human observations.
In practice, deployment means designing three layers: (1) data outputs (exports and APIs that other systems can consume), (2) experience outputs (dashboards and reports tailored to stakeholders), and (3) governance outputs (privacy, consent, retention, documentation, and audit trails). This chapter walks you through each layer with concrete workflows and design choices that keep the competency map actionable and defensible.
Practice note for Design outputs: dashboards, exports, and API payloads: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Translate skills into recommendations and pathways: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Integrate with HR systems and credentialing (badges, certificates): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write a governance and privacy playbook: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Deliver a stakeholder-ready competency map report: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design outputs: dashboards, exports, and API payloads: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Translate skills into recommendations and pathways: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Integrate with HR systems and credentialing (badges, certificates): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write a governance and privacy playbook: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Start by designing outputs as “products” with distinct users and decisions. A single generic dashboard typically fails because learners, managers, and L&D ask different questions. Create three primary views and keep each one opinionated.
Learner view should answer: “What can I credibly claim now, and what should I do next?” Keep it constructive and motivational. Show a small set of competencies with (a) current level, (b) confidence band or reliability indicator, and (c) evidence snippets (e.g., “Scored 82% on SQL joins assessment,” “Completed 3 labs with passing rubric on query optimization”). Add a “why” panel that lists the evidence types used so learners can self-correct if something is missing.
Manager view should answer: “How do I coach and staff work responsibly?” Managers need aggregation but must not see unnecessary personal detail. Provide team-level heatmaps (competency vs. proficiency) plus drill-down that reveals evidence categories and timestamps, not raw clickstream. Include a “ready for assignment” indicator for tasks that map to competencies, but gate it with confidence thresholds and validation status (e.g., “validated by rubric sample” vs. “inferred only”).
L&D view should answer: “Is learning moving the needle, and where do we improve content?” Show cohort trends, pre/post changes, and the relationship between learning activities and validated competency gains. Include quality diagnostics: missing evidence rates, bias checks (e.g., confidence disparities across groups), and “content effectiveness” views that compare activities by uplift and uncertainty.
Competency maps become career tools when you connect them to role profiles. A role profile is a curated set of competencies, target levels, and acceptable evidence for a job family (e.g., “Data Analyst II”). Build role profiles with SMEs and HR partners, but keep them modular: shared competencies (communication, data literacy) plus role-specific ones (dashboard design, statistical testing).
Implement gap analysis as a comparison between a learner’s validated competency state and the role target. The key is to separate capability gaps from evidence gaps. For example, a learner may be capable but lacks recent evidence because they did not take an assessment that maps to the competency. Your UI should explicitly label: “Skill gap” vs. “Evidence gap” and provide an action for each (practice task vs. assessment/portfolio submission).
Use pathways to support multiple directions: vertical progression (Analyst I → Analyst II), lateral moves (Analyst → Product Ops), and specialization tracks (Analytics → Experimentation). Pathways should be presented as sequences of competencies with milestone evidence, not just lists of courses. When possible, align milestones to real work artifacts (a reviewed SQL report, a peer-approved dashboard) so the pathway feels career-relevant.
Once gaps are visible, recommendations become the engine of growth. Design recommendations as a decision system with constraints, not as a content carousel. A useful “next best activity” should incorporate: the target role/pathway, the learner’s current evidence, confidence/uncertainty, prerequisites, and time cost.
Start with a simple, interpretable policy before using more complex ranking models. A practical baseline is rules + scoring: prioritize competencies with the largest gap weighted by role criticality, then choose the shortest activity that produces the strongest evidence type. For remediation, map common failure patterns to targeted practice. Example: if assessment item analysis shows repeated errors in SQL GROUP BY logic, recommend a micro-lab focusing on aggregation with immediate feedback, followed by a short re-check assessment that can generate new evidence.
Include recommendation explanations: “Recommended because it addresses your Level 2 gap in X and produces validated evidence via rubric Y.” This reduces distrust and helps learners choose among options. Also add a “not now” or “not relevant” feedback control. Treat that as data for improving mapping, not as a negative signal about the learner.
Deployment rarely succeeds if the competency map stays inside the LMS. Plan interoperability so skills can flow to the systems where career decisions live: LRS for learning records, HRIS for employee profiles, ATS for internal mobility, and credentialing platforms for badges and certificates. Your goal is to expose portable, minimal, and versioned skill claims.
Define three output formats: (1) dashboard-ready tables (denormalized for BI tools), (2) exports (CSV/Parquet for analysts and batch integrations), and (3) API payloads for near-real-time syncing. A common API pattern is a “SkillClaim” object containing learner ID (pseudonymous if needed), competency ID and version, level, confidence, evidence summary, validation status, and timestamps. Do not export raw clickstream unless you have a strong governance reason; most consumers need interpreted outcomes and audit pointers.
For credentialing, decide what qualifies for a badge: typically a validated level threshold plus required evidence types. For example, “SQL Foundations Badge” might require Level ≥ 2 with at least one proctored assessment and one rubric-reviewed lab. Ensure certificates reference the competency framework version and include a verification endpoint so claims remain meaningful after updates.
A competency map can help careers only if people trust it. That trust is earned through governance: privacy-by-design, clear consent, reasonable retention, and transparency about how inferences are made. Write a governance and privacy playbook as a living document and ship it alongside the system, not as an afterthought.
Consent and notice: learners should know what data is used (activity events, assessment outcomes, rubric reviews), what it is used for (learning development and credentialing), and what it is not used for (e.g., disciplinary monitoring). Provide opt-out paths where feasible, and define what happens to recommendations and dashboards for opted-out users (often: show only self-reported skills or completion-based views).
Retention: align retention windows to purpose. Raw events may be retained briefly (e.g., 90–180 days) while aggregated evidence and audit references are retained longer to support career records. Use data minimization: keep what you need to justify a skill claim and delete what you don’t. Also define access controls: managers see summaries; auditors see justification; system operators see logs; no one sees more than necessary.
Transparency: publish model cards or “inference notes” that explain signals used, known limitations, and confidence semantics. If you use interpretable models, expose feature categories at a high level (“assessment performance,” “rubric-reviewed artifacts,” “practice mastery”) rather than raw behavioral traces. Document bias checks and mitigation steps, and be explicit about where the system is uncertain.
Your final deliverable is often a stakeholder-ready competency map report: a narrative that explains what the map says, how it was built, and how it should be used. Treat this as a product artifact with templates and repeatable sections, not a one-off slide deck.
Structure the report in three layers. Executive narrative: key findings (top strengths, priority gaps, pathway readiness rates) and recommended actions (curriculum changes, coaching focus, badge rollout). Operational appendix: definitions of competencies and levels, mapping logic to courses/tasks/evidence, and recommended thresholds for “ready” or “in progress.” Audit appendix: data lineage, validation sampling results, rubric inter-rater reliability, model/version history, and known limitations.
Include limitations prominently. Examples: “Competencies inferred primarily from LMS activity may under-represent on-the-job performance,” “Confidence is lower for learners with sparse evidence,” “Role profiles were calibrated with SMEs from Team A and may need adjustment for Team B.” This protects stakeholders from overuse and signals maturity. Add a maintenance plan: how often mappings are reviewed, how new courses are onboarded, and how drift is detected (e.g., sudden changes in evidence distributions after an LMS update).
When these pieces are in place—products, pathways, recommendations, integrations, governance, and reporting—the competency map stops being an analytics experiment and becomes career infrastructure. The best signal you have deployed well is not a polished dashboard; it is repeated, consistent use in development conversations, credentialing decisions, and curriculum improvements, with clear documentation that keeps the system honest as it evolves.
1. What best describes Chapter 6’s view of “deployment” for a competency map?
2. Which framing should guide what the deployed competency map is (and is not)?
3. According to the chapter, what is a common failure mode in competency map deployment?
4. What are the three layers that deployment should be designed around?
5. Which set of elements belongs in the governance outputs layer described in the chapter?

- Learning Evolved.
- Intelligence Amplified.

