Career Transitions Into AI — Beginner
Turn design instincts into scalable microcopy for AI chat experiences.
Chatbots and copilots are now core product surfaces—but many teams still treat microcopy as an afterthought. This course is a short, technical, book-style path for UX designers and product designers who want to transition into AI UX writing. You’ll learn how to design microcopy as a system: reusable patterns, voice and tone rules, safety-aware messaging, and spec-ready documentation that engineering teams can implement.
Instead of focusing on generic “prompt tips,” you’ll build the foundations that make conversational experiences feel coherent across intents, screens, and edge cases. The result is practical: you’ll leave with a portfolio-ready microcopy system for a chatbot or copilot, plus the evaluation and measurement plan that proves it works.
Across six chapters, you’ll create artifacts that mirror real product workflows—briefs, intent maps, conversation flows, pattern libraries, and QA checklists. Each chapter adds a new layer, so by the end you have a complete package you can show in interviews or apply directly on the job.
This course is designed for individuals transitioning into AI-facing UX writing roles: product designers, UX designers, content designers, and UX writers who want stronger system thinking for AI interfaces. You don’t need to code. You do need a willingness to think in flows, states, and constraints—because AI outputs change, but product expectations don’t.
AI experiences break when teams rely on one-off clever phrasing. You’ll learn to design microcopy like a design system: patterns that scale, rules that reduce ambiguity, and language that earns trust. The chapters progress from role clarity, to conversation foundations, to systemization, then to edge cases and safety, then to copilot integration, and finally to measurement and portfolio packaging.
Along the way, you’ll practice writing that is:
If you’re ready to move from designing screens to designing AI conversations—and you want a portfolio artifact that demonstrates real product thinking—start here. Register free to access the course, or browse all courses to compare learning paths across AI careers.
AI UX Writer & Conversation Design Lead
Sofia Chen is an AI UX writer and conversation design lead who builds microcopy systems for chatbots and copilots in SaaS and enterprise workflows. She specializes in scalable content patterns, safety-aware messaging, and cross-functional delivery with design and engineering teams.
As a UX designer, you already know how to reduce friction, set expectations, and guide users through uncertainty. AI products amplify those same responsibilities because the interface is no longer a set of static screens: it responds, interprets, and occasionally misunderstands. This chapter defines what AI UX writing is (and is not), shows where your existing design skills transfer, and gives you a practical starting workflow: set the product context (chatbot vs. copilot vs. agent), write an AI UX writing brief with success metrics, and adopt a shared glossary so you can collaborate with engineering and legal without translating every conversation from scratch.
One mindset shift matters most: in AI, you do not “ship strings.” You ship behavior. Microcopy becomes part of a system—voice, tone, patterns, UI states, and recovery paths—that must work across unpredictable inputs. The goal is not clever phrasing; it’s reliable comprehension, calibrated trust, and task success even when the model is uncertain. The rest of this chapter turns that idea into practical deliverables you can use immediately.
Practice note for Define AI UX writing vs. content design vs. conversation design: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Audit your transferable design skills and identify gaps: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Set product context: chatbot vs. copilot vs. agent: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create your first AI UX writing brief and success metrics: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Establish a working glossary (intent, turn, slot, grounding): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Define AI UX writing vs. content design vs. conversation design: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Audit your transferable design skills and identify gaps: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Set product context: chatbot vs. copilot vs. agent: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create your first AI UX writing brief and success metrics: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Establish a working glossary (intent, turn, slot, grounding): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Traditional UX writing supports known states: empty, loading, error, success. Conversational UIs introduce a moving target: user intent arrives in natural language, and the system must infer what they mean, ask follow-ups, and sometimes refuse. That “talk back” capability changes scope. You’re no longer writing isolated labels; you’re designing turns—each exchange between user and system—and ensuring the product behaves coherently across branches.
AI UX writing sits adjacent to content design and conversation design, but it’s not identical to either. Content design focuses on end-to-end content across a product (navigation, onboarding, settings), often spanning multiple surfaces. Conversation design focuses on dialog structure and flow logic (prompting, turn-taking, repair). AI UX writing is microcopy + behavioral guidance for model-mediated interaction: onboarding prompts, clarifying questions, confirmations, citations/grounding language, refusals, and “what to do next” nudges. In practice, you’ll often do pieces of all three, but it helps to label your output so teams know what’s being specified: words, flows, or both.
Common mistakes when designers first move into AI UX writing: (1) assuming one “perfect” response exists instead of defining patterns for variability; (2) letting the model “handle it” rather than specifying how the product should recover; (3) writing friendly text that over-promises capability; and (4) ignoring the difference between a model’s confidence and a user’s trust. Your leverage comes from designing constraints and recovery: how the UI asks for missing info, how it confirms risky actions, and how it communicates limitations without sounding broken.
In AI products, microcopy “lives” in more places than a chat bubble. You’ll write text embedded in UI chrome (placeholder prompts, suggested chips), inside orchestrated flows (handoff to human support, authentication steps), and within system-controlled wrappers (safety messages, policy-based refusals). Treat microcopy as a set of components with rules, not a doc of one-off lines.
Start by naming your deliverables. A practical set for your first projects: (1) a microcopy inventory (every user-visible string, grouped by state); (2) a conversation pattern library (clarify, confirm, refuse, recover, cite); (3) a voice-and-tone spec tuned for AI (how direct, how transparent, when to apologize); and (4) UI state copy for uncertainty (ambiguous request, missing required slots, partial results). If your team has a design system, think of this as the “content system” layer that aligns with components like chat message, card, toast, and modal.
Map microcopy to intent and entity requirements early. For each top user goal, define the user intent (what they’re trying to do) and the key entities/slots (the variables needed to fulfill it). Then write the microcopy that: elicits missing slots (“Which account should I use?”), validates risky entities (“Send $500 to Sam—correct?”), and offers alternatives when the system can’t comply. This is where UX designers transfer well: you already do form design and validation; slots are conversational form fields.
Engineering judgment shows up in how you parameterize copy. Avoid hardcoding specifics (“I found 3 flights”) without robust data wiring; instead define templates with variables and fallback text. Specify when to show streaming indicators, when to summarize, and when to link out. Microcopy is not just what the model says; it’s what the product guarantees regardless of model output.
To write effectively, you need a mental model of the conversational UX stack. Layer 1 is the UI: chat surface, input affordances, suggested replies, citations, and any non-chat controls (filters, drawers, file pickers). Layer 2 is the model: the LLM that generates or transforms text, with strengths (language) and weaknesses (hallucination, ambiguity). Layer 3 is orchestration: prompt templates, tool calls, retrieval/grounding, memory rules, policy filters, and fallback logic. Most “copy problems” are actually stack problems—text is compensating for missing orchestration or unclear UI.
Set product context before you write: chatbot vs. copilot vs. agent. A chatbot is primarily conversational Q&A or task routing. A copilot sits inside a workflow and helps draft, decide, or summarize with the user in control. An agent can execute actions autonomously (or semi-autonomously) across tools. Your microcopy patterns differ: chatbots need routing and containment (“Here’s what I can help with”); copilots need collaboration language and verification (“Review and edit before sending”); agents require explicit confirmations, audit trails, and strong failure recovery (“I couldn’t access the calendar—try reconnecting”).
Workflow tip: write from orchestration constraints outward. Ask engineering: What tools can the model call? What data is grounded? What are the refusal policies? What is the latency budget? Then write microcopy that matches reality. If retrieval can fail, you need a grounded fallback response pattern. If actions are irreversible, add confirm-and-summarize steps. A common mistake is treating the model as a magic black box; the best AI UX writers design with the wiring in mind.
Finally, define how ambiguity is handled: when the product asks a clarifying question versus presenting options versus making an assumption. Document it as a pattern so the system is consistent across intents. Consistency is a trust feature.
AI UX writing succeeds or fails at handoffs. The PM needs clear scope boundaries (“what we will and won’t support”), engineering needs spec-ready patterns and variables, legal needs risk-aware language and policy alignment, and support needs predictable escalation triggers. Your job is to make conversational behavior legible across disciplines.
Create your first AI UX writing brief as a shared artifact. Keep it short but explicit: target users and primary jobs-to-be-done; top intents; required entities/slots; allowed actions; disallowed content; grounding sources; tone principles; and non-goals (what the assistant should not attempt). Include a “failure modes” section listing expected problems (ambiguous asks, missing data access, policy refusals, low confidence retrieval). Then map each failure mode to a microcopy pattern and UI state. This is how you prevent last-minute copy scrambling when QA finds edge cases.
Practical documentation that engineers can implement: a table for each intent with trigger examples, required slots, clarifying questions, confirmation copy, success response template, and fallback/hand-off copy. For legal, annotate where policy language is mandatory versus flexible. For support, specify when to offer human escalation and what context to pass along (conversation summary, user selections, error codes). A common mistake is writing “polite” refusals that don’t explain next steps; support teams then inherit confused users.
Use a working glossary to keep meetings efficient. When everyone shares definitions for intent, entity/slot, turn, grounding, tool call, and refusal, you reduce rework and misinterpretation. Treat the glossary as part of the spec, not a separate wiki nobody reads.
AI UX writing is measurable. If you can’t evaluate it, you can’t improve it. Define success metrics in your brief and align them with what the team can instrument. Start with three outcome categories: task success (did the user accomplish the goal), comprehension (did the user understand what happened and what to do next), and trust (does the user feel the system is competent and appropriately cautious).
Task success metrics can be completion rate for key intents, time-to-complete, and reduction in handoffs. Comprehension can be proxied by fewer “what do you mean?” follow-up turns, fewer repeated questions, or higher correctness in confirmations. Trust is trickier; look for signals like reduced user over-reliance (“are you sure?” loops), fewer complaints about misinformation, and higher acceptance rates of suggested actions when confidence is warranted.
Engineering judgment matters in setting the bar. If the model is probabilistic, your microcopy must calibrate expectations without undermining usefulness. Avoid absolutes (“This is correct”) unless grounded; prefer transparent, action-oriented phrasing (“Based on the document you shared…”). For uncertainty, define patterns: acknowledge limits, ask for missing details, offer safe defaults, and provide recovery paths. For refusals, keep them specific, policy-aligned, and helpful: state that you can’t comply, briefly why (when allowed), and what you can do instead.
Common evaluation mistake: reviewing copy in isolation. Evaluate full conversations with realistic user inputs, including messy ones. Use a rubric that checks clarity, tone consistency, safety alignment, and whether the conversation converges on a resolution. Microcopy that reads well but doesn’t steer the interaction is not doing its job.
To transition from UX designer to AI UX writer, position your existing skills as system-building: information architecture becomes intent architecture; form validation becomes slot elicitation; error handling becomes repair design; and interaction design becomes turn design. Your gaps are usually (1) technical literacy in the AI stack, (2) writing spec-ready patterns with variables and edge cases, and (3) evaluation thinking for probabilistic outputs.
A practical 30–60–90 plan: In the first 30 days, build your glossary and learn the stack vocabulary well enough to ask good questions (intent, entity/slot, turn, grounding, orchestration). In days 30–60, produce a microcopy system: voice-and-tone principles, pattern library, and a small inventory for one feature. In days 60–90, run evaluations: create a test set of prompts, score conversations with a rubric, and propose iterations tied to metrics.
Portfolio targets should look like shipped specifications, not writing samples. Include: an AI UX writing brief with success metrics; an intent-to-microcopy mapping table; a pattern library (clarify/confirm/refuse/recover) with templates and examples; and annotated conversation flows showing UI states (empty, loading, tool failure, policy refusal, escalation). Show one “before/after” iteration where you improved task success or reduced confusion based on evaluation results. Hiring teams want evidence that you can collaborate with engineering and legal and still protect user experience.
Finally, be explicit about product context in each case study: was it a chatbot, copilot, or agent? What actions were allowed? What was grounded? The more clearly you connect microcopy choices to system constraints, the more you demonstrate the core competency of an AI UX writer: designing language that behaves reliably in the real world.
1. What is the key mindset shift the chapter emphasizes for UX designers moving into AI UX writing?
2. Why does the chapter say AI products amplify traditional UX responsibilities like reducing friction and setting expectations?
3. Which workflow is presented as a practical starting point for AI UX writing in this chapter?
4. What is the chapter’s stated goal for AI UX microcopy?
5. How does establishing a working glossary (e.g., intent, turn, slot, grounding) help an AI UX writer, according to the chapter?
Moving from traditional UX design into AI UX writing starts with a mindset shift: you are no longer designing a screen-first path, you are designing a sequence of turns. Each turn is a contract between user and system about what happens next, what is understood, and what the system needs to proceed. This chapter builds the foundation for that contract by connecting user research to intent inventories, then turning those intents into flows, context strategies, and a reusable microcopy system your team can ship.
A practical way to think about conversation design is as “microcopy with state.” The same line—“Sure, I can help”—means different things depending on whether the system has enough context to act, whether it is uncertain, or whether it must ask a follow-up. Your job is to make those states explicit, choose the minimum number of turns to reach task success, and write microcopy that is resilient when reality is messy (missing info, ambiguous requests, partial permissions, API failures).
Throughout this chapter, you will translate research into an intent taxonomy, draft flows for top intents, design what the system knows and when, and write first-pass microcopy for greetings, prompts, and confirmations. You will also create a conversation spec format that an engineer can implement and a QA partner can test.
Practice note for Turn user research into intent inventories and job stories: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Draft conversation flows for the top intents: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design context strategy: what the system knows and when: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write first-pass microcopy for greetings, prompts, and confirmations: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a conversation spec format your team can ship: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Turn user research into intent inventories and job stories: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Draft conversation flows for the top intents: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design context strategy: what the system knows and when: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write first-pass microcopy for greetings, prompts, and confirmations: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
An intent taxonomy is your bridge from research to buildable scope. Start with user research artifacts you already know—interview notes, support tickets, search logs, task analyses—and translate them into “what the user is trying to do in this moment.” Intents should be phrased as actions (e.g., “Reset password,” “Track order,” “Summarize meeting notes”), not as features (“Password,” “Orders,” “Notes”).
Use job stories to keep the taxonomy grounded: “When I’m locked out, I want to reset my password so I can regain access.” Job stories clarify triggers and success criteria, which later become acceptance criteria in your spec. For each intent, capture: primary user goal, typical entry utterances, required inputs (entities/slots), dependencies (APIs, permissions), and risk level (legal, safety, brand).
Prioritization for MVP is usually a three-factor decision: volume (how often), value (business and user impact), and viability (engineering complexity and risk). A common mistake is to prioritize “cool” intents that demo well but fail under real-world ambiguity. Your MVP should focus on intents that can be completed reliably with clear constraints. If an intent requires too many permissions or depends on brittle integrations, design it as “informational guidance” first, then promote it to “actionable automation” later.
Deliverable outcome: an intent inventory table with an MVP column, plus a short list of the top intents you will draft flows for next.
Turn design is where UX writing becomes conversation engineering. A turn is not just a message; it includes the system’s goal, the user’s expected response space, and the UI affordances available (free text, chips, buttons). Good turns reduce cognitive load by asking one clear thing at a time and by signaling what the system will do with the answer.
Draft conversation flows for your top intents using a consistent pattern: entry → understanding → gather missing info → confirm → execute → close. For each step, write first-pass microcopy for greetings, prompts, and confirmations, but keep it tightly coupled to state. A greeting is not a slogan; it should set expectations (“I can help you track orders or start a return”). Prompts should be specific and scoped (“What’s the order number?” is better than “Tell me more”). Confirmations should be calibrated to risk: confirm more when the action is irreversible or high-impact.
Common mistakes: stacking multiple questions in one turn (“What’s your email and order number and shipping ZIP?”), using vague acknowledgments (“Okay.”), and confirming everything (which makes the bot feel slow and insecure). Engineering judgment here is about balancing accuracy and friction: confirm when the cost of being wrong is high, or when the model’s confidence is low; otherwise proceed and allow easy correction (“If that’s not right, tell me the correct order number”).
Deliverable outcome: a first-pass flow for each top intent with turn-level copy, including happy path and at least one repair path.
Users assume conversation equals memory, but AI systems have constraints: session context limits, privacy rules, and product decisions about persistence. Your context strategy defines what the system knows, what it can infer, what it should ask, and what it must never retain. This is both a UX and an engineering alignment task.
Start by listing context sources: the current chat (recent turns), user profile (name, plan, locale), device/app signals (platform, logged-in state), and external systems (orders, calendar). Then decide when each source is available. For example, an anonymous web chat cannot “remember” a past purchase without authentication; a logged-in copilot might access project metadata but not private documents unless explicitly granted.
Design memory expectations in microcopy. If the system cannot remember across sessions, say so when it matters (“I can’t see past chats, but I can help if you share the order number again”). If it can store preferences, offer control (“Want me to remember this for next time?”). A common mistake is overpromising (“I’ll remember that”) when the backend does not support it, which breaks trust fast.
Engineering judgment: be explicit about the “context window” you assume for intent resolution. If the model typically uses the last N turns, avoid flows that require the user to reference something far back without restating it. When tasks are long, recap key facts in-system (“So far: return item A, reason: wrong size, refund to original payment”). Recaps are both usability and robustness tools.
Deliverable outcome: a context map documenting sources, availability conditions, retention rules, and user-facing expectations copy.
Most task chatbots succeed or fail on slot filling: collecting the minimum required information to complete an intent. Slots are the entities your system needs (dates, amounts, locations, account identifiers). Progressive disclosure means you do not ask for everything upfront; you ask only for what you need next, based on what you already know.
Begin by defining each intent’s required vs optional slots. Then write slot prompts that are understandable, secure, and easy to answer. Prefer user language (“order number”) over internal language (“transaction ID”). If a slot has a format constraint, teach it in the prompt (“Enter the 6-digit code from your email”). If a user might not have the info, provide alternatives (“If you don’t have the order number, you can search by email and ZIP”).
Common mistakes include asking for sensitive data unnecessarily, failing to handle partial answers (“Tomorrow afternoon” without a timezone), and not anticipating ambiguity (“Paris” could be multiple locations). Engineering judgment comes from knowing when to disambiguate immediately versus proceeding with a best guess and giving the user a chance to correct. For example, you might proceed with a default locale but surface it: “I’ll use Paris, France—tell me if you meant a different Paris.”
Practical outcome: for each intent, produce a slot schema (slot name, type, required/optional, validation rules, prompt copy, and error message copy). This becomes the backbone of reusable microcopy patterns: ask, validate, confirm, recover.
Conversation does not always mean “text only.” Modern assistants live in multimodal surfaces: quick-reply chips, buttons, inline forms, file uploads, and voice. Each modality changes what “good microcopy” looks like because it changes how much the user can or should type, and how errors are prevented.
Buttons and chips are best for constrained choices and high-confidence disambiguation. They reduce language variability and are often easier to instrument. In your turn design, treat them as part of the copy: button labels should be verbs (“Track order,” “Start return”), not nouns. Keep labels short and parallel. When using chips, pair them with a prompt that explains the decision (“Choose a refund method”).
Forms can replace multiple chat turns when the user expects structured entry (addresses, payment details). The microcopy shift is from conversational questions to field labels, helper text, and inline validation. Don’t duplicate the same instruction in chat and in the form; decide which surface owns which explanation.
Voice introduces different constraints: users cannot scan history easily, so recaps and confirmations matter more, and prompts must be shorter. Avoid long lists; offer two or three options at a time. Also plan for interruptions and barge-in: write responses that can be resumed (“I can help with that. First, what’s your booking ID?”).
Deliverable outcome: modality-aware copy variants (text, chip labels, form helper text, voice-friendly phrasing) for the same intent turns, documented so engineering can implement consistently.
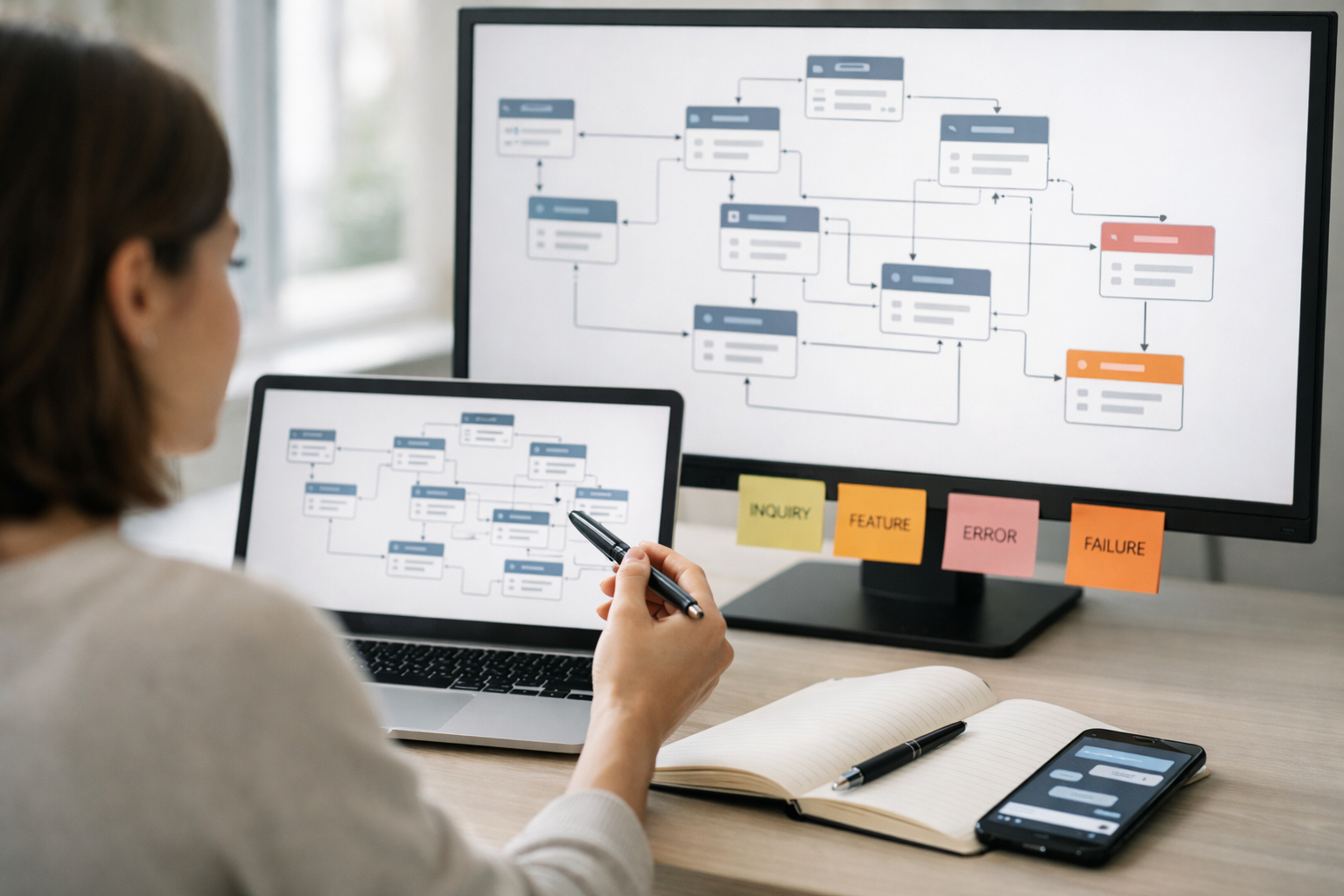
To collaborate with product, legal, and engineering, you need spec-ready documentation—not just scripts. A shippable conversation spec makes intent logic explicit, ties microcopy to states, and defines how success will be evaluated. The goal is to reduce interpretation risk: two different engineers should implement the same behavior from your artifact.
Use three complementary artifacts. First, a flow diagram (or state diagram) for each top intent: entry points, decision nodes (known/unknown slots), error branches, escalation, and exit conditions. Keep it readable: prefer a few deep flows over a single unreadable poster. Second, a turn table: one row per system/user turn with columns for state, system goal, expected user input, slots affected, UI modality, and microcopy. Third, acceptance criteria: testable statements that define correct behavior, including edge cases.
Include criteria for uncertainty and failure: timeouts, API errors, low-confidence intent matches, ambiguous entities, and refusal scenarios where applicable. Write acceptance criteria in user-centered terms (“If the user provides an invalid order number, the system explains the format and asks again”) and pair them with instrumentation notes when useful (“Log event: order_lookup_failed with reason=invalid_format”).
Common mistake: leaving “magic” to the model (“The assistant figures it out”). Instead, specify guardrails: when to ask clarifying questions, when to confirm, and when to escalate. Practical outcome: a conversation spec package your team can implement sprint by sprint, with copy that maps cleanly to UI states and backend requirements.
1. In this chapter’s mindset shift, what replaces a “screen-first path” as the primary thing you design?
2. What does the chapter mean by each turn being a “contract” between user and system?
3. Why is conversation design described as “microcopy with state”?
4. Which approach best matches the chapter’s guidance for reaching task success?
5. Which set of outputs best reflects the end-to-end workflow described in the chapter?
When designers transition into AI UX writing, the biggest mindset shift is moving from “writing good strings” to building a system that keeps those strings good under pressure: new features, new locales, model updates, policy changes, and different teams shipping UI in parallel. In chatbots and copilots, microcopy is not decoration—it is operational control. It signals what the system can do, asks for the right information, manages uncertainty, and prevents the conversation from breaking.
This chapter shows how to turn your design instincts—consistency, components, states, and governance—into a microcopy system for AI. You’ll define voice principles that survive edge cases, tune tone per scenario, build a pattern library for common conversational moves, write UI state microcopy (including system messages like loading and progress), and set the rules and workflows that make reuse safe at scale.
The goal is not to freeze language; it’s to create repeatable decisions. A good microcopy system reduces cognitive load for users and reduces rework for teams. It becomes a shared interface between product, engineering, legal, and support: clear enough to implement, flexible enough to evolve, and grounded enough to build trust when the model is uncertain.
As you read, notice the recurring theme: the best AI microcopy anticipates failure modes. Ambiguity, missing inputs, latency, refusals, and partial answers are normal. Systems that plan for those moments feel “smart.” Systems that don’t feel random—even if the model is powerful.
Practice note for Define voice principles and tone sliders for AI interactions: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build a pattern library for common conversational components: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write system messages: loading, status, and progress states: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a style guide for brevity, clarity, and inclusivity: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Set governance: naming, versioning, and review workflows: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Define voice principles and tone sliders for AI interactions: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build a pattern library for common conversational components: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write system messages: loading, status, and progress states: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Voice is your product’s stable personality across contexts. For AI, voice principles must handle uncertainty without sounding evasive or overconfident. A practical starting set is: helpful, humble, and precise. These are not brand adjectives; they’re behavioral constraints that guide wording choices in every UI state and conversation turn.
Helpful means the assistant does work, not just talk. Microcopy should propose next steps (“I can draft, summarize, or help you troubleshoot—what’s the goal?”) and reduce decision burden with options. Humble means it acknowledges limits and avoids implying authority it doesn’t have. Replace “I know” with “Based on what you shared…” and avoid definitive claims when the model is guessing. Precise means it uses concrete language, scoped promises, and clear requests for missing inputs.
Common mistake: teams define voice as “friendly and fun” and discover it fails in high-stakes flows (payments, health, account recovery). For AI, voice principles should be testable: can reviewers consistently label a response as helpful/humble/precise? If not, tighten the rules. Treat voice like a design system foundation—small set of durable constraints, not a long list of vibes.
Deliverable tip: document voice principles as Do/Don’t pairs with examples in your spec. This becomes the rubric for conversation design reviews and model prompt tuning, and it helps legal and support align on the same behavior.
Tone is voice plus context. In AI interactions, tone needs explicit controls because the same assistant may handle routine tasks, sensitive issues, and occasional moments of delight. One practical tool is a set of tone sliders—dimensions you intentionally dial up or down per scenario. Common sliders include: formality, directness, warmth, confidence, and verbosity.
Routine scenarios (summaries, scheduling, content tweaks) benefit from low ceremony: direct, brief, and option-oriented. Your microcopy should minimize friction: short confirmations, skimmable suggestions, and “undo” language that reduces fear. High-stakes scenarios (account access, financial actions, regulated advice, content moderation) require calmer pacing, higher precision, and lower playfulness. Increase formality and explicitness: state what will happen next, what data is used, and how to get help. Delight scenarios (celebratory success states, small wins) can allow a touch more warmth, but avoid jokes that could land poorly or undermine trust.
Engineering judgment shows up when tone interacts with model generation. If you allow free-form tone in prompts, you risk inconsistency. Instead, encode tone sliders as structured variables (e.g., tone.directness=high, verbosity=low) that drive templates, UI copy, and constraints on generated text length. This makes tone a controllable part of the system rather than a fragile instruction.
Common mistake: “delight” becomes a default tone. In AI, small uncertainty moments happen frequently; playful language during errors or refusals can feel dismissive. Make tone scenario-based, not personality-based.
A pattern library is where AI UX writing becomes scalable. Instead of writing every response from scratch, you define reusable conversational components with intent, rules, and examples. Start with five high-leverage patterns: ask, suggest, summarize, confirm, and handoff. Each pattern should specify: when to use it, required inputs (entities/slots), optional variants, and the failure mode it prevents.
Ask patterns collect missing information without overwhelming the user. Specify the “one question” rule and provide constrained choices when possible. Suggest patterns offer next actions (chips, buttons, or short bullets), keeping the assistant helpful without rambling. Summarize patterns compress long context and reduce hallucination risk by reflecting back what the system believes is true. Confirm patterns prevent irreversible mistakes—especially for destructive or high-stakes actions. Handoff patterns route to humans or other channels with clear expectations and preserved context.
Common mistake: pattern libraries that only store copy, not logic. Your library should include interaction constraints: character limits, button labels, whether to include citations, and when to avoid free-form generation. This is where you translate UX design skills into AI deliverables: map intents and entities to microcopy requirements, then attach patterns to those requirements so teams implement consistently.
Practical outcome: reviewers can evaluate new features by checking “Which pattern are we using?” If the answer is “none,” the experience will likely drift.
Chat UIs still have UI states: empty views, loading, partial results, failures, and reversals. State microcopy is where trust is won or lost because it frames what the system is doing and what the user should do next. Treat these as system messages: short, consistent, and more deterministic than model-generated content.
Empty states should orient and invite: what the assistant is for, what inputs work, and a few example prompts. Avoid generic “Ask me anything” unless it’s true and safe. Loading/status/progress messages reduce anxiety during latency: say what’s happening (“Searching your files…”) and, when possible, show progress steps. Keep them calm; don’t over-apologize for normal processing. Error states must be actionable: what failed, whether anything was saved, and what the user can do now.
Engineering judgment: decide which states are generated vs fixed. Loading, error, retry, and undo should typically be fixed strings (or tightly templated) to avoid unpredictable wording and to support localization. For AI failures, distinguish model limitation (can’t do), policy refusal (won’t do), and system error (didn’t work). Each needs different microcopy and different recovery paths.
Common mistake: error messages that blame the user (“You entered invalid…”), or vague failures (“Something went wrong”). In conversational UX, vagueness reads like deception. Be specific without leaking sensitive internals: provide a reason category and a next step.
A microcopy system needs a style guide that is optimized for AI: brevity, clarity, and inclusivity, plus constraints that keep model outputs readable. Consistency is not aesthetic—it improves comprehension, reduces perceived randomness, and makes evaluation possible. Start with three rule sets: terminology, formatting, and constraints.
Terminology rules define canonical words for the same concept (e.g., “workspace” vs “project”), and banned synonyms that confuse. Include product nouns, verbs for actions, and how you refer to the assistant (“I” vs brand name). Formatting rules define how lists, steps, dates, times, file names, and links appear. If the assistant often outputs multi-step guidance, decide when to use numbered steps versus bullets. Constraints cover length limits, reading level targets, and when to avoid hedging.
Common mistake: style guides that ignore model behavior. AI can over-produce text, invent headings, or vary terminology. Add “AI-specific” constraints such as: maximum bullets, limit to one follow-up question, avoid speculation, and always separate facts from suggestions. If you work with engineers, encode these constraints into prompt templates, response validators, or UI truncation rules so the style guide is enforceable.
Practical outcome: you can evaluate conversational UX with consistent criteria—clarity, trust, and task success—because outputs are structured enough to compare across versions.
Reuse at scale requires more than copy-pasting. You need componentization: modular microcopy that can be assembled reliably across intents, channels, and UI surfaces. Think in three layers: tokens, templates, and components, supported by governance (naming, versioning, and reviews).
Tokens are small, controlled variables: product names, plan names, timeouts, counts, and user-specific fields. Define formatting rules (e.g., {file_name} always in sentence case; numbers localized). Templates are parameterized strings that implement patterns and states, such as refusal + alternative, or confirm + consequence. Components bundle template + UI behavior: message text, buttons, helper links, telemetry events, and fallback behavior if required fields are missing.
handoff.support.unavailable, state.error.file_permission).Engineering judgment: decide where dynamic generation is allowed. A robust approach is “fixed frame, flexible fill”: the system message provides structure (what happened, what’s next), and the model fills controlled slots (e.g., a short summary) under strict length limits. This preserves voice and reduces the chance of policy or factual drift.
Common mistake: governance that’s too heavy to use. If adding a new template requires a long meeting, teams will bypass the system. Keep a lightweight intake: a change request with context, examples, risk level, and acceptance criteria. Then schedule periodic audits—look for duplicate templates, inconsistent terminology, and failure-state gaps. Over time, your microcopy system becomes a living asset: it speeds shipping, improves quality, and makes AI behavior feel intentionally designed rather than accidentally generated.
1. What is the biggest mindset shift Chapter 3 describes for designers becoming AI UX writers?
2. In this chapter, microcopy in chatbots and copilots is described primarily as what?
3. Which combination best represents the “spec-ready microcopy toolkit” outcome described in the chapter?
4. Why does the chapter stress defining voice principles and tuning tone per scenario (e.g., via tone sliders)?
5. According to the chapter, what distinguishes AI systems that feel “smart” from those that feel random, even with powerful models?
As a designer transitioning into AI UX writing, your most valuable instinct is already in your toolkit: you design for real-world messiness. Chatbots and copilots are not deterministic interfaces. They interpret intent, guess missing context, and sometimes fail in ways that look confident. This chapter turns “uncertainty” into a writing system you can specify, test, and ship.
Safety and trust are not just legal requirements or policy checkboxes. They are product qualities users can feel in the first five seconds: Does this assistant overpromise? Does it ask smart questions when it’s unsure? Does it recover gracefully? Does it respect privacy? Your microcopy is the control surface for all of that.
We’ll build a practical set of patterns for calibrated language, refusals and safe completion, clarifying questions, hallucination recovery, privacy/consent messaging, and escalation to humans. Along the way you’ll learn how to document edge cases in spec-ready terms—so engineering, product, and legal can implement consistently.
The guiding principle: write as if the model is sometimes right, sometimes wrong, and often incomplete. Your job is to help users make good decisions anyway.
Practice note for Design refusal and safe-completion messaging that preserves trust: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write clarifying questions for ambiguous user inputs: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create recovery paths for wrong answers and hallucinations: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Handle privacy, data sensitivity, and consent microcopy: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build an edge-case checklist and escalation playbook: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design refusal and safe-completion messaging that preserves trust: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write clarifying questions for ambiguous user inputs: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create recovery paths for wrong answers and hallucinations: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Handle privacy, data sensitivity, and consent microcopy: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Calibrated language means the user can accurately predict how much to trust an answer. In traditional UX, you avoid ambiguity; in AI UX, you also avoid false certainty. Your microcopy should signal when the system is reasoning, retrieving, or guessing—and what the user should do next.
Start by defining three “confidence bands” in your microcopy system: (1) high confidence (the assistant has authoritative inputs or strong constraints), (2) medium confidence (reasonable inference, but missing context), and (3) low confidence (insufficient info, multiple plausible interpretations). Map these bands to consistent phrasing. For example: high confidence can be direct (“Here’s the status…”), medium confidence can include a light hedge plus a next step (“It looks like… want me to confirm?”), and low confidence should pivot to clarification (“I’m not sure which you mean—choose one”).
Engineering judgment matters here: don’t sprinkle generic disclaimers (“may be inaccurate”) everywhere. Overuse trains users to ignore warnings, and it reads like legal cover instead of helpful guidance. Instead, place calibrated microcopy at decision points: before irreversible actions, when data is incomplete, and when the model is likely to hallucinate (e.g., citations, numbers, medical/legal claims).
Common mistake: using confidence language that sounds like personality (“I think maybe…”) rather than system behavior (“I don’t have enough information to confirm…”). The first erodes trust; the second sets expectations and invites user participation. Practical outcome: users understand the assistant’s role and reduce reliance on unverified outputs.
Refusals are part of the product, not an exception. A good refusal preserves user dignity, explains the boundary in plain language, and offers a safe alternative path (“safe completion”). Your goal is to prevent harm while maintaining momentum.
Design refusals as a structured template with slots you can reuse across categories (self-harm, violence, hate, illegal activity, medical/legal advice, private data requests). A robust refusal includes: (1) a clear “no” that doesn’t debate, (2) a brief reason framed as policy or safety, (3) what the assistant can do instead, and (4) optional escalation if risk is high.
Policy-aligned wording should be consistent and non-accusatory. Avoid “You are trying to…” or moralizing language. Also avoid providing partial instructions “just in case,” which can still enable harm. Safe completion is not “answering less”; it’s answering a safer neighboring intent.
Workflow tip: write refusal variants by user intent, not by policy category alone. The same policy boundary can appear in different contexts (e.g., “How do I hack my ex’s email?” vs. “I forgot my password”). Your microcopy should distinguish malicious intent from legitimate recovery by offering compliant alternatives (account recovery steps, security best practices). Practical outcome: fewer dead ends, fewer escalations, and a system that feels firm but helpful.
Ambiguity is the default in conversation. Users omit context, switch goals midstream, and use shorthand that means different things in different domains. Your job is to convert ambiguity into a small number of clarifying questions that are easy to answer.
A practical rule: ask the minimum number of questions needed to proceed safely. Don’t interrogate. Use an “assume + confirm” pattern when risk is low (“Do you mean X?”) and an “options set” when multiple paths are equally likely. Options sets work best when they are mutually exclusive, short, and phrased as outcomes rather than internal system terms.
Design the microcopy so users can answer with a tap/click when possible. Even in text-only chat, you can simulate “chips” by numbering options and accepting “1/2/3.” This reduces cognitive load and improves intent classification downstream.
Common mistake: asking open-ended questions that reintroduce ambiguity (“Can you tell me more?”). Replace them with scoped questions tied to the task model: goal, audience, format, constraints, and timeframe. Practical outcome: higher task success and fewer hallucinations because the model is guided by explicit constraints rather than guessing.
Users will encounter wrong answers, outdated information, and hallucinated details. Trust is not built by being perfect; it’s built by recovering well. Your recovery microcopy should do three things quickly: acknowledge the failure, correct course, and keep the user moving.
Create a recovery ladder with escalating responses depending on severity. For low-severity mistakes (tone, minor formatting), a brief acknowledgment plus a fix is enough. For factual errors or fabricated citations, the assistant should explicitly retract the uncertain claim and propose verification steps. For high-impact domains (medical, financial, legal), recovery should include stronger guardrails and referral language.
Engineering judgment: decide when to proactively offer uncertainty checks. For example, after generating numbers, add a lightweight verification step (“If you share the inputs, I can recompute”) rather than asserting precision. Also define “undo” and “audit” microcopy for actions: confirm before sending, show what changed, and offer reversal (“Undo last edit”).
Common mistake: over-apologizing. One clear acknowledgment is enough; repeated apologies read like stalling. Practical outcome: users feel respected, can correct the system efficiently, and learn how to collaborate with it (provide inputs, validate outputs) rather than abandon it.
Privacy microcopy is where trust becomes measurable. Users need to understand what data is used, what is stored, and what is optional. The best privacy messaging is contextual: it appears at the moment a user is about to share something sensitive or trigger data access.
Define “sensitivity triggers” with your product and legal partners: account numbers, government IDs, health details, children’s data, passwords, and private third-party information. For each trigger, specify: (1) a warning, (2) a safer alternative, and (3) a consent step when access or retention changes. Keep language plain; avoid policy jargon unless linked.
Workflow tip: maintain a privacy microcopy matrix by UI state (onboarding, first sensitive ask, settings, export/delete, incident messaging). Pair each line with implementation notes: where it appears, required buttons (“Allow / Not now”), and any logging implications (e.g., redact inputs in transcripts). This is where collaboration becomes spec-ready documentation.
Common mistake: burying consent in long paragraphs. Consent needs clear choices and neutral phrasing, not nudges that feel coercive. Practical outcome: reduced risk, fewer support tickets, and users who feel in control of their data.
No matter how strong your AI is, some situations require a human: billing disputes, account access failures, safety concerns, regulated advice, or repeated misunderstanding. A good handoff is not “Contact support.” It is a guided transition that preserves context, sets expectations, and reduces repetition.
Write a handoff playbook with clear triggers. Examples: the user asks the same question three times, the system confidence stays low after clarification, the user reports harm, the assistant detects high-stakes topics, or the user explicitly requests a person. Your microcopy should confirm what will be shared, how long it will take, and what the user can do while waiting.
Engineering judgment: decide whether the assistant should create a structured ticket (fields: intent, entities, transcript snippet, device/app version) or route to live chat. Your writing should align with the actual system behavior—nothing erodes trust faster than promising a handoff that drops the user into a generic form with no context.
Common mistake: treating escalation as failure. Instead, frame it as an efficient next step for complex cases. Practical outcome: faster resolution, smoother collaboration between AI and humans, and a user experience that remains trustworthy even when the assistant can’t complete the task.
1. In this chapter, what is the primary role of microcopy in safety and trust for AI chatbots?
2. What writing behavior best reflects the chapter’s guiding principle for uncertainty?
3. When the assistant is unsure what the user means, what does the chapter recommend you write?
4. What is the intended outcome/deliverable of Chapter 4’s approach to safety and edge cases?
5. Which evaluation lens does the chapter emphasize for judging the quality of safety-and-trust microcopy, especially when the system is wrong?
As a designer moving into AI UX writing, you’ll quickly discover that “a chat experience” is not one thing. A chatbot is typically a destination: users arrive, ask, and expect the system to route, answer, and recover when it can’t. A copilot is more often an instrument: it lives inside an existing product flow and helps the user act, decide, or write without leaving context. Your microcopy system has to reflect that difference, because the user’s tolerance for uncertainty, their expectations of control, and the product’s risk profile shift dramatically depending on the interaction model.
This chapter gives you practical patterns for choosing the right model (chat, assistive, or embedded), writing next-best actions and guided prompts, designing “promptable UI” elements (placeholders, examples, constraints), and formatting outputs for decision support (summaries, diffs, citations). Finally, you’ll learn how to document end-to-end flows across screens and channels so product, legal, and engineering can ship consistently.
Think of your role here as translating user goals into controllable, testable UI states. When AI is involved, microcopy becomes part of the safety system: it sets expectations, narrows ambiguity, and ensures users understand what will happen before they click “Run,” “Send,” or “Apply.”
Practice note for Choose the right interaction model: chat, assistive, or embedded: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write actionable suggestions and next-best actions: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design promptable UI: placeholders, examples, and constraints: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write summaries, diffs, and citations for decision support: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Document end-to-end flows across screens and channels: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Choose the right interaction model: chat, assistive, or embedded: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write actionable suggestions and next-best actions: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design promptable UI: placeholders, examples, and constraints: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write summaries, diffs, and citations for decision support: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Document end-to-end flows across screens and channels: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
A chatbot excels when the user’s goal begins with a question or request, and when the product can route that request to a clear capability. Your first writing job is intent routing: helping the system and the user agree on “what kind of thing this is.” Microcopy does that through greetings that set scope, menu options that label common intents, and clarification questions that are narrow and answerable.
Containment is the companion concept: keeping the user inside the chat experience long enough to reach task success, without trapping them when the chatbot is the wrong tool. Practical containment relies on three microcopy moves: (1) upfront scope (“I can help with billing, plan changes, and troubleshooting”), (2) quick pivots (“Try ‘Track refund’ or ‘Update payment method’”), and (3) graceful exits (“Talk to an agent,” “Open settings,” “Email me the steps”).
Engineering judgment matters because routing often maps to backend constraints: intent classifiers, knowledge base retrieval, or tool calls. Your microcopy should reduce ambiguity so those systems can behave reliably. Common mistakes include asking open-ended clarification (“Can you tell me more?”), which increases token cost and user frustration, or overpromising capability (“I can fix that”) before the system has enough information. A practical deliverable is an intent-to-microcopy table: each intent has an entry prompt, disambiguation question(s), success confirmation, and a fallback path when confidence is low.
When you document this, specify the triggers for containment vs escalation (e.g., “If user expresses legal threat,” “If confidence < 0.6,” “If repeated failure twice”). That is spec-ready writing, not just UX copy.
Copilots live in context. Instead of “Ask me anything,” the user expects “Help me do this thing here.” That changes how you write both guidance and affordances. Inline assistance (tooltips, empty states, in-field helpers) should be short, specific, and tied to the UI object. Side panels (or drawers) can hold longer guidance, previews, and settings without interrupting the user’s main workflow.
The key design decision is where the user’s attention should stay. Inline patterns work best for small, reversible tasks: rewriting a sentence, suggesting a filter, generating tags. Side panels suit larger tasks that benefit from preview and control: drafting a whole email, summarizing a report with citations, or proposing multi-step edits.
Copilot microcopy should be action-forward: verbs that map to tools (“Summarize,” “Rewrite,” “Create tasks,” “Find anomalies”). It also must be honest about agency. Users need to know whether the copilot is merely suggesting text or actively changing data. A common mistake is using chat-style politeness that obscures the action boundary (“Sure, I updated that for you”) when the system only prepared a draft.
Practical outcome: write a “copilot contract” panel header and state language: what it can do, what it cannot do, where results will appear, and how to apply changes. Include a persistent control: “Apply,” “Insert,” “Save draft,” or “Run,” plus “Cancel” and “Undo” where applicable. In specs, note where the copilot reads from (current document, selected rows) and writes to (draft only, live record), because that determines the microcopy for risk and confirmation.
Suggestions are your bridge between uncertainty and action. They reduce the user’s blank-page problem and make the model’s “next-best action” concrete. In chatbots, suggestion chips keep the conversation on rails; in copilots, menus and guided prompts make capabilities discoverable without training.
Write suggestion chips like mini-commands: start with a verb, keep them parallel, and make them mutually exclusive when possible. Avoid vague chips like “Help” or “More.” Prefer “Track shipment,” “Change address,” “Cancel order.” For guided prompts in a copilot, include constraints directly in the copy: “Summarize in 5 bullets,” “Rewrite in a friendly tone,” “Draft a reply under 120 words.” This is “promptable UI”: the UI teaches users how to ask in ways the system can reliably fulfill.
Placeholders and examples are not decoration; they’re behavior shaping. A good placeholder shows structure, not content: “e.g., ‘Compare Q2 vs Q3 churn and call out top drivers’.” Pair it with lightweight constraints (“No PII,” “Use the selected rows only”) when your product must limit what the model can use. Common mistakes include giving examples that are too complex (users copy them verbatim and get poor results) or too open-ended (users don’t learn the pattern).
In documentation, tie suggestions to user goals and states: “If empty state → offer ‘Import,’ ‘Create sample,’ ‘Explain this page.’ If error state → offer ‘Retry,’ ‘View logs,’ ‘Contact support.’” This is how you make suggestions systematic rather than ad hoc.
The difference between a chatbot and a copilot becomes most visible when the AI can take actions: send an email, update a record, file a ticket, delete a workspace. Action microcopy is where trust is either earned or lost. Your goal is to make actions legible: what will change, where, and whether it can be reversed.
Use a two-step pattern for high-impact actions: preview → confirm. The preview should summarize the proposed changes in user language (“3 contacts will be updated”) and include a detail view (diff, list, or highlighted fields). The confirmation button must name the action (“Update 3 contacts,” “Send email,” “Delete project”), not a generic “Confirm.” For irreversible actions, say so plainly and early: “This can’t be undone.” Then provide an alternative if possible: “Archive instead,” “Export first.”
Undo is the most powerful trust mechanism you can write. If engineering supports it, prefer post-action confirmation with a clear undo affordance (“Sent. Undo”) over pre-action warnings for low-risk actions. When undo isn’t possible, be explicit about what can be edited after the fact (“You can edit recipients before sending,” “You can restore within 30 days” if true). Common mistakes include stacking multiple warnings (users ignore them) or hiding scope (“This will update your settings” without listing which settings).
Spec-ready deliverables include: confirmation modal copy, toast copy, error recovery copy, and the rules for when each appears (risk tier, affected objects, permission level). Add legal review flags for regulated actions (financial transfers, medical advice, HR decisions) and note required citations or disclosures.
Decision support is not just about “the right answer”; it’s about making the answer easy to evaluate. AI outputs often fail because they are verbose, unordered, and hard to scan. Your microcopy system should define default formats: bullets for lists, tables for comparisons, and short summaries when the user needs a fast read.
Start with a rule: lead with a summary, then details. A practical template is: (1) one-sentence conclusion, (2) 3–5 bullets of supporting points, (3) optional table or expanded explanation. In copilots, add “show more” affordances so the default view stays compact. In chatbots, keep paragraphs short and use headings when the response exceeds a screenful.
When the user is making a choice, use tables. Columns should match decision criteria (“Option,” “Pros,” “Cons,” “Cost,” “Risk”). If the model is comparing revisions, use a diff-style presentation: “Before / After” or “Changed” with highlighted edits. For factual claims, use citations or source labels when available (“From: Q3 Sales Report (May 12)”) and be transparent when you can’t cite (“No source found in your documents”). Avoid fake precision: do not invent page numbers or links.
Document formatting requirements like you would a component: maximum bullet count, truncation behavior, and fallback formats when the UI can’t render tables (e.g., mobile). This turns “good writing” into consistent product behavior.
AI experiences rarely live in one place. A user might start in a web app, get a push notification, and later receive an email summary of what the copilot did. Cross-channel continuity means your microcopy keeps the same promises, names, and controls across these surfaces—while respecting each channel’s constraints.
On web, you can support rich previews, side panels, and detailed citations. On mobile, you must prioritize scannability and safe tap targets; long outputs should collapse into summaries with a “View details” deep link. Email is asynchronous: it should restate context (“You asked the copilot to…”) and include a clear call to action (“Review and approve changes”) rather than dumping raw model output. Notifications must be even tighter: communicate status and next step (“Draft ready to review,” “Approval needed,” “Action failed—tap to retry”).
Continuity also includes identity and state language. Use the same labels for objects (“workspace,” “project,” “invoice”) everywhere, and keep action verbs consistent (“Apply,” “Insert,” “Run”). A common mistake is channel drift: the email says “Your report is complete,” but the in-app state says “Generating,” or the notification says “Sent” when the action is only queued.
Practical documentation: create an end-to-end flow map that spans screens and channels. For each step, specify: user trigger, system state, microcopy, and recovery. Include rules for handoff: when chat escalates to email, what transcript is included, what privacy redactions apply, and what the user can do next. This is where designers-turned-AI-writers shine: you can see the whole journey, not just the message.
1. Which statement best captures the difference between a chatbot and a copilot in this chapter?
2. Why must a microcopy system change depending on whether the experience is chat, assistive, or embedded?
3. What is the primary purpose of writing actionable suggestions and next-best actions?
4. Which set of elements best represents “promptable UI” as described in the chapter?
5. How do summaries, diffs, and citations support decision-making in AI-assisted interfaces?
You can write excellent microcopy and still ship a chatbot that confuses users, escalates too late, or quietly erodes trust. The difference between “good writing” and “good conversational UX” is measurement: the ability to define quality, test it, iterate based on evidence, and present the work as a system that others can maintain.
This chapter focuses on how to operationalize your craft. You’ll define rubrics and scorecards, plan testing from usability sessions to red-teaming, build iteration loops using analytics and qualitative feedback, and package the work into a portfolio case study with artifacts that look “spec-ready” to product and engineering. Finally, you’ll translate your experience into interview stories and a pragmatic 30-60-90 plan that signals you can ship.
Think like an engineer without losing your writer’s sensitivity: choose metrics that reflect user goals, design evaluation methods that reveal failure modes, and create a repeatable workflow so “improving the bot” isn’t a vague aspiration—it’s a weekly practice.
Practice note for Define quality rubrics and scorecards for conversational UX: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Plan testing: usability sessions, red-teaming, and QA scripts: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create iteration loops with analytics and feedback: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Assemble a portfolio case study with artifacts and rationale: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Prepare interview stories and a 30-60-90 plan for the role: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Define quality rubrics and scorecards for conversational UX: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Plan testing: usability sessions, red-teaming, and QA scripts: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create iteration loops with analytics and feedback: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Assemble a portfolio case study with artifacts and rationale: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Prepare interview stories and a 30-60-90 plan for the role: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Start measurement by choosing metrics that reflect user outcomes and conversational health—not just engagement. The most common operational set for chatbots and copilots includes containment (how often the bot resolves without human handoff), CSAT (explicit rating or proxy sentiment), task completion (did the user achieve the goal), and rephrase rate (how often users restate the request because the bot missed it).
Use metrics as a scorecard with definitions and thresholds. For example: containment should be segmented by intent, because a high containment rate can hide harmful failures if the bot incorrectly “completes” a request. Task completion should be tied to an observable event (submitted form, generated file, policy explanation acknowledged), not simply “conversation ended.” Rephrase rate is a leading indicator for microcopy issues: unclear prompts, missing constraints, or misaligned intent labels. A practical heuristic is to flag turns where the user repeats the same request with different wording within two turns; that’s often a writing, disambiguation, or NLU coverage problem.
Common mistake: chasing a single global KPI. A well-designed microcopy system often trades off containment for trust—handing off sooner in high-stakes intents can reduce containment but increase CSAT and reduce risk. Engineering judgment means deciding which metric is primary per intent. For billing disputes you may prioritize safe escalation and comprehension; for store hours you may prioritize containment and speed.
Document the metric map: which intents are measured by which metrics, how they’re computed, and what “good” looks like. That document becomes a shared contract with product and data partners and prevents your writing work from being evaluated as subjective taste.
Metrics tell you where to look; evaluation methods tell you what to change. Combine human review with heuristic checks so you can scale quality assessment beyond one writer’s opinion. Build a rubric that scores clarity, trust, and task success—the same outcomes stakeholders care about. Keep it simple: a 1–5 scale with anchored definitions and example behaviors works better than a long checklist nobody uses.
Human review can be done through targeted transcript sampling. Pull conversations from the worst-performing intents (high rephrase, low completion) and label failure modes: missing slot/entity, ambiguous user goal, refusal wording too blunt, excessive verbosity, or policy mismatch. Pair each label with a microcopy action: add a clarifying question, tighten a system prompt, adjust refusal language, or insert a confirmation step.
Heuristic checks give you repeatable “linting” for conversations. Examples include: every prompt includes a clear next step; the bot states constraints before asking for input; error states offer recovery options; refusals explain what it can do instead; and sensitive intents include escalation and disclaimers. Run these heuristics on new flows during design review, similar to UI heuristic evaluation in traditional UX.
Common mistake: treating red-teaming as separate from writing. Red-teaming is a form of evaluation: ask adversarial, ambiguous, and policy-edge questions and score how the bot responds. Your rubric should include safety, helpfulness within policy, and graceful recovery. This is where “writing for uncertainty” becomes measurable: does the bot admit limits, ask clarifying questions, and offer alternatives without sounding evasive?
Iteration loops are how microcopy becomes a system rather than a one-time deliverable. Treat every change as an experiment: define the hypothesis, the metric you expect to move, and the segment where the effect should appear. For example: “If we add a one-sentence constraint before the upload prompt, rephrase rate for ‘file type not supported’ will decrease and task completion will increase.”
A/B testing is ideal when you have sufficient traffic and can isolate a single variable. Keep variants minimal: change one prompt, one confirmation step, or one refusal template at a time. Ensure instrumentation is ready—if task completion isn’t logged reliably, you will end up optimizing for easy-to-measure proxies like conversation length.
For lower-traffic products, use sequential testing: ship a change, monitor for regressions, and compare week-over-week with comparable cohorts. Supplement with qualitative review of transcripts; often microcopy improvements show up as “fewer confused follow-ups” before they show up in CSAT.
Common mistake: iterating only on the “happy path.” The fastest wins often come from fixing the first-turn onboarding, ambiguity handling, and recovery after errors. Another mistake is overfitting to power users; segment by new vs returning users, by intent complexity, and by channel (in-app vs web vs voice) because tone and brevity expectations differ.
Operationally, create a weekly cadence: (1) review dashboard + transcript sample, (2) pick top two issues, (3) draft microcopy changes with rationale, (4) implement and annotate release notes, (5) monitor and report. This cadence is the backbone of “ship, evaluate, improve.”
Quality assurance for AI UX writing is not proofreading; it’s validating behavior across scenarios. Create QA scripts that include scenarios (user goals), assertions (what must be true in the response), and coverage (how many intents and edge cases you’re testing). This aligns directly with engineering practice and makes your work “testable.”
Write scenarios as short stories: persona, context, intent, and constraints. Then specify assertions such as: the bot asks for the missing entity (date, account ID), the bot uses the approved tone, the bot does not claim to have performed an action it can’t perform, the bot offers escalation for regulated content, and the bot provides at least one recovery option after failure.
Coverage should be explicit. Map tests to intents and UI states: onboarding, clarification, success, failure, refusal, handoff, and follow-up. Include ambiguity (“I need help with my bill”), conflicting instructions, and partial inputs. If you’re working with a generative model, include prompt-injection and policy-boundary attempts as part of routine QA, not a once-a-quarter event.
Common mistake: relying only on “golden conversations.” AI systems drift with model updates, retrieval changes, or policy revisions. Maintain a regression suite: a set of high-risk prompts and expected behaviors. When the system changes, re-run the suite and compare results. Even if responses vary, your assertions can remain stable (e.g., must cite sources when using retrieval; must not provide medical diagnosis; must ask a clarifying question when confidence is low).
Deliverable tip: store QA scripts in the same repo or workspace as conversation specs, and write them in a format engineers can automate later (tables with scenario ID, input, expected assertion tags). That collaboration detail is often what distinguishes senior-level conversation design.
Your portfolio needs to prove you can ship and improve, not just write clever lines. Package one case study around a measurable problem: “high rephrase in password reset,” “low trust in refund policy answers,” or “handoff too late for account lockouts.” Show the baseline, the diagnosis method (metrics + transcript review), the system-level changes, and the impact.
Include before/after artifacts. Before: messy transcript snippets, ambiguous prompts, inconsistent tone, missing recovery. After: revised microcopy with pattern names (Clarify, Confirm, Refuse-with-Alternative, Escalate), plus the rationale tied to your rubric (clarity/trust/task success). Stakeholders love seeing how a pattern scales across intents, so demonstrate reuse: one updated clarification pattern applied to three different intents.
System docs are your differentiator for career transition. Add a lightweight “microcopy system” appendix: voice and tone principles, a pattern library with do/don’t examples, UI state copy (loading, error, empty), and policy-sensitive templates (disclaimers, refusals, handoff). Include your scorecard and QA approach so reviewers can see how quality is maintained.
Common mistake: hiding constraints. If legal required specific wording, say so. If engineering limited data access, describe the workaround. Mature portfolios show tradeoffs and collaboration: how you negotiated with legal, aligned with product on success metrics, and gave engineers spec-ready copy with variables, conditions, and fallback behaviors.
End the case study with “what I’d do next”: next experiments, additional intents to cover, and known risks. This signals you think in iteration loops, not one-off deliverables.
Interview success in AI UX writing often depends on demonstrating process under uncertainty. Prepare stories that follow a consistent structure: context, user goal, failure mode, your method (rubric + testing + iteration), the artifact you produced (spec, pattern, QA script), and the measured outcome. Emphasize collaboration moments: aligning metrics with product, validating constraints with legal, and writing implementable requirements for engineering.
Expect prompt-based interviews: you may be asked to improve a confusing bot message, design a refusal for a policy edge case, or draft a short conversation flow with clarifying questions. Practice thinking aloud: name the intent, identify missing entities, define what “success” means, and propose two variants with evaluation criteria. For take-homes, deliver in a format that looks production-ready: a mini spec with states, copy, conditions, and a small QA checklist.
Bring a 30-60-90 plan tailored to the role. First 30 days: audit intents, map metrics, establish a scorecard, and create a transcript review cadence. Days 60: ship top microcopy fixes, implement pattern library, and stand up regression QA. Days 90: run experiments, expand coverage to edge cases/red-teaming, and formalize system documentation. Keep it concrete; hiring managers want to see you can drive operational improvements.
Negotiation is easier when you can articulate scope and impact. Tie your level to responsibilities: owning evaluation criteria, building reusable systems, and partnering cross-functionally. Ask about access to analytics, ownership of tone/policy templates, and release cadence—these determine whether you can actually measure and iterate. The goal is to land in an environment where your craft is supported by the right tooling and decision-making structure.
1. According to the chapter, what most clearly separates “good writing” from “good conversational UX” in chatbot work?
2. Why does the chapter emphasize defining quality rubrics and scorecards for conversational UX?
3. Which testing plan best matches the chapter’s approach to revealing chatbot failure modes?
4. What is the purpose of creating iteration loops using analytics and qualitative feedback?
5. In a strong portfolio case study for this chapter, what should artifacts and rationale primarily demonstrate?

- Learning Evolved.
- Intelligence Amplified.

