AI In Finance & Trading — Beginner
Understand how AI works in finance without coding
Getting Started with AI in Finance for Beginners is a short, practical course designed like a clear technical book for people who are completely new to the topic. You do not need coding skills, a finance degree, or a background in data science. This course starts with the basics and explains everything in plain language, step by step.
Artificial intelligence is changing how banks, investment firms, insurers, and finance teams work. But for beginners, the topic can feel confusing because many resources are too technical or assume prior knowledge. This course removes that barrier. It focuses on first principles, simple examples, and real-world use cases so you can understand what AI is, how it works in finance, and where its limits are.
The course is structured as six connected chapters, with each chapter building naturally on the previous one. You will begin by learning what AI actually means and how finance depends on information and decisions. Then you will move into the kinds of data financial systems use, how machine learning learns patterns, and where AI shows up in banking, investing, and trading.
You will also learn an important truth: AI is not magic. It can help with speed, pattern recognition, and prediction, but it can also make mistakes. That is why the course includes a full chapter on risk, bias, privacy, fairness, and trust. By the end, you will not only know the opportunities of AI in finance, but also how to think responsibly about its use.
Many introductions to AI in finance jump too quickly into programming, statistics, or advanced trading systems. This course does not. It is made for complete beginners who want a reliable foundation before going deeper. The teaching style is simple, calm, and structured so that you can understand the topic without feeling lost.
Because the course is organized like a short book, the learning journey is coherent and cumulative. Each chapter introduces a small number of ideas, reinforces them with clear milestones, and prepares you for the next concept. This makes it easier to remember what you learn and connect it to real situations.
This course is ideal for curious learners, career changers, students, finance professionals with no technical background, and business users who want to understand what AI can actually do in finance. If you have heard terms like machine learning, prediction models, or algorithmic trading but never really understood them, this course is for you.
It is also useful if you want to speak more confidently with technical teams, evaluate AI tools more carefully, or prepare for more advanced study later. If you are ready to begin, Register free and start learning at your own pace.
By the end of the course, you will be able to explain core AI ideas in simple terms, identify common financial AI use cases, understand the role of data, and recognize major risks and limitations. Most importantly, you will have a practical beginner framework for deciding when AI makes sense in a finance setting and what questions to ask before trusting it.
This course is the right first step if you want confidence before complexity. Once you finish, you can continue your learning journey and browse all courses to explore related topics in AI, finance, and trading.
Financial AI Educator and Machine Learning Specialist
Sofia Chen teaches beginner-friendly courses at the intersection of finance and artificial intelligence. She has helped students and business teams understand how AI supports forecasting, risk analysis, and financial decision-making without heavy technical barriers.
Artificial intelligence can sound mysterious, especially when it is linked to money, markets, banks, and risk. In practice, AI in finance is not magic. It is a way of using data, patterns, and computer systems to support decisions that people already try to make every day: who should get a loan, which card transaction looks suspicious, how much cash a bank should hold, what price seems fair, or what may happen next in a market. This chapter gives you a beginner-friendly foundation for the rest of the course. The goal is not to turn finance into computer science. The goal is to build a simple working mental model that helps you understand what these systems do, where they help, and where they can mislead.
A good starting point is everyday language. AI is often best understood as software that tries to perform tasks that normally require human judgment, pattern recognition, or prediction. In finance, that usually means reading large amounts of information and turning it into a recommendation, a score, a forecast, or a warning. Some systems are simple and rule-based. Others learn patterns from historical examples using machine learning. Understanding the difference between rules, data, and learning is essential because many business problems do not need the most advanced model. In fact, one of the most important ideas in finance technology is that the simplest reliable method is often the best place to begin.
Finance itself is a decision business. Banks, insurers, asset managers, payment companies, and trading firms all use information to decide how to allocate money and how to control risk. That means financial AI always sits inside a larger workflow. Data is collected, cleaned, and checked. A model or a rule system processes that data. A human team may review the result. Then an action is taken: approve, reject, flag, investigate, hedge, rebalance, alert, or monitor. Looking at AI as one part of a process helps beginners avoid a common mistake, which is to assume that the model alone creates value. Usually, value comes from the whole chain: data quality, clear objectives, sensible thresholds, human oversight, and feedback after decisions are made.
Throughout this chapter, keep four practical questions in mind. First, what decision is being supported? Second, what data is available? Third, is the system following fixed rules or learning from examples? Fourth, what can go wrong? These questions are useful in banking, investing, fraud detection, customer service, and forecasting. They also help you read financial data examples without needing advanced math. A customer record, a transaction log, a market price history, or a balance sheet line can all become inputs to an AI system. The system then tries to detect patterns: unusual behavior, likely default, expected return, future demand, or rising risk.
As you read the sections in this chapter, focus on practical understanding. You will see how finance uses information to make decisions, how AI connects to common financial tasks, and why engineering judgment matters as much as technical accuracy. You will also see the limits. Financial AI tools can be useful, fast, and scalable, but they can also be wrong, biased, out of date, or overconfident. A model trained on the past does not automatically understand a crisis, a policy change, or a new kind of fraud. That is why professionals combine data, business knowledge, controls, and skepticism. By the end of this chapter, you should be able to explain AI in simple terms, recognize common use cases, read basic examples of financial data, and describe both the promise and the risks of using AI in financial decisions.
Practice note for Understand what AI means in everyday language: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for See how finance uses information to make decisions: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Artificial intelligence is a broad term, and beginners often hear it used as if it means a human-like machine that can think on its own. In finance, the meaning is usually much narrower and much more practical. AI refers to computer systems that help with tasks such as classification, prediction, ranking, anomaly detection, language processing, or recommendation. For example, a system may estimate the probability that a borrower will miss payments, detect whether a transaction is unusual, or summarize a research note. These are specific tasks, not general intelligence.
A useful way to understand AI is to compare three approaches. First, there are rules. A rule might say, "flag any card transaction above a certain amount made in a new country." Rules are simple, transparent, and easy to audit, but they can be too rigid. Second, there is data analysis. This means looking at numbers, trends, and relationships to understand what is happening. Third, there is machine learning, where a system learns patterns from past examples instead of being told every rule directly. If we show a model many examples of fraudulent and non-fraudulent transactions, it may learn patterns that are hard to write as fixed rules.
Beginners often make the mistake of thinking machine learning is always smarter than rules. In reality, each method has strengths. Rules are useful when the business requirement is clear and stable. Machine learning is useful when patterns are complex and change over time. Strong financial systems often combine both. For instance, a bank may apply hard regulatory rules first, then use a model to rank the remaining cases by risk.
Another important point is that AI does not remove the need for judgment. Someone still has to define the target, choose the data, test the system, set thresholds, and monitor results. If the wrong outcome is measured, the model may optimize for the wrong goal. If the data is incomplete or biased, the output may be misleading. So when you hear "AI," think less about magic and more about structured decision support built from data, logic, and repeated testing.
Finance is the business of moving, pricing, protecting, and allocating money over time. That includes lending, borrowing, investing, trading, insuring, making payments, and managing risk. Every one of those activities depends on information. A lender wants to know whether a borrower is likely to repay. An investor wants to know whether an asset may rise or fall in value. A fraud team wants to know whether a payment is legitimate. A treasury team wants to know how much cash may be needed next week. In each case, better information can lead to better decisions.
Data is the raw material behind those decisions. In finance, common data sources include customer applications, account balances, transaction records, credit history, market prices, company financial statements, interest rates, news, and even text documents such as earnings reports. A very simple financial data example might be a table with columns like customer income, monthly debt payment, credit score, loan amount, and repayment outcome. Another example might be a stream of card transactions with time, amount, merchant, location, and whether the customer later confirmed fraud.
What matters is not just having data, but having usable data. Financial data can be messy. Values may be missing. Dates may be inconsistent. Market data may have outliers. A customer may have multiple accounts under slightly different names. Before any model is useful, teams usually spend significant time cleaning, matching, and validating data. This is where engineering judgment begins. If a dataset includes information that would not be known at decision time, the model may accidentally learn from the future. That creates a misleadingly strong result that will fail in real use.
For beginners, it helps to remember a simple chain: data becomes information when it is organized, and information becomes decision support when it is interpreted correctly. AI works only when that chain is strong. Poor data does not become good decision-making just because it passes through a complex model. In finance, where decisions can affect money, trust, and regulation, data quality is not a side issue. It is the foundation.
To understand AI in finance, you first need to understand how decisions happen without AI. Financial institutions usually operate through workflows. A workflow starts with an objective, such as approving a loan, detecting suspicious activity, forecasting cash needs, or selecting investments. Then data is gathered, checked, and transformed into useful features. A decision method is applied. That method may be a human review, a fixed policy, a scorecard, a statistical model, or a machine learning system. Finally, the organization acts and tracks the result.
Take loan approval as an example. A customer submits an application. The lender collects details such as income, employment status, outstanding debts, and credit history. Some rules are absolute, such as legal or policy requirements. Other factors are judgment-based, such as whether the risk is acceptable at a given interest rate. In some firms, the process ends with a human underwriter. In others, many applications are approved automatically if they meet clear standards, while more complex cases are escalated.
Now consider fraud detection. A payment arrives in real time. The system checks whether the amount, merchant type, device, and location fit the customer’s normal pattern. If the risk appears low, the payment goes through. If the risk appears high, the payment may be blocked or sent for review. The business challenge is balancing false positives and false negatives. Too many false positives annoy customers by blocking good transactions. Too many false negatives allow fraud losses. This trade-off is central in financial AI.
These examples show that financial decisions are rarely just yes-or-no technical events. They are business processes with costs, controls, and consequences. Good engineering judgment means understanding where speed matters, where explanation matters, where human review is needed, and what type of error is most dangerous. AI fits into these workflows, but it does not replace the workflow itself.
AI fits into finance where patterns are large, repetitive, fast-moving, or difficult to capture with simple rules alone. One common use is prediction. A model may estimate default risk, customer churn, future cash flow, or expected market volatility. Another use is classification, such as labeling a transaction as normal or suspicious. A third use is ranking, where the system orders opportunities or alerts so staff can focus on the most important cases first. AI can also help with language tasks, such as extracting information from documents or summarizing financial text.
It is important to see AI as support for decisions, not just automation. In a credit process, an AI system may generate a risk score. That score does not have meaning by itself. The business must decide how to use it. Does a score above a threshold trigger rejection? Does it trigger manual review? Is there a different threshold for new customers than for existing ones? These choices are business design decisions. The model provides inputs, but the organization decides how outputs become actions.
AI is also useful in forecasting, but forecasting in finance is never certain. A model can estimate next month’s cash demand or potential market movement, yet forecasts depend on assumptions and historical patterns. If the environment changes sharply, the model may underperform. Good teams monitor this carefully. They compare predictions with outcomes, retrain when needed, and keep fallback procedures in place. This is one reason financial AI is as much about operations as it is about algorithms.
A common mistake is to ask AI to solve the wrong problem. For example, a team may build a very accurate model for predicting something that does not improve decisions. A practical mindset starts with the business question: what action will change if this prediction improves? If the answer is unclear, the AI project may create little value. The best uses of AI in finance connect directly to workflow improvements, lower losses, faster reviews, better prioritization, or stronger risk control.
Even beginners have likely seen AI in finance without realizing it. If your bank app warns you about unusual account activity, that is often an anomaly detection system. If a payment is declined because the system believes the behavior is suspicious, that is a fraud model or hybrid rule-model system in action. If a lender gives instant pre-approval for a simple loan product, AI or scoring systems may be helping estimate risk in seconds.
In investing, robo-advisors are a familiar example. They ask questions about goals, time horizon, and risk tolerance, then recommend a portfolio. Some of this is straightforward rule-based logic, and some may include optimization models or data-driven components. On trading platforms, AI may assist with price prediction, execution timing, or signal generation, although in real markets these tools are difficult to build well and are never guaranteed to outperform. In customer service, chatbots and document readers can help answer account questions, collect information, or route support cases more efficiently.
These examples also reveal why limits matter. A fraud alert can be wrong. A robo-advisor can be too generic for a complex situation. A market forecast can fail during unusual events. A document-processing model can misunderstand a scanned file. That is why output should be treated as informed assistance, not unquestioned truth. In professional settings, teams test precision, recall, stability, and fairness, and they design review processes for exceptions.
For beginners, the practical takeaway is simple: AI in finance is already around you, usually in small targeted tasks. Once you notice these systems, you can begin asking smart questions. What data are they using? What are they trying to predict? What are the most costly errors? Where is a human still involved? Those questions will help you evaluate financial AI tools more clearly than buzzwords ever will.
The big picture is that AI gives financial organizations a new way to turn data into decisions at scale. It can help with speed, consistency, prioritization, forecasting, and risk detection. But it works best when its role is clearly defined. A strong mental model for the rest of this course is this: finance asks a decision question, data provides evidence, rules and models process the evidence, and people design and govern the whole system. If any part of that chain is weak, the result can be poor even if the model itself is advanced.
You should also remember that financial AI has special risks. Historical data can contain bias. Fraud patterns can change quickly. Markets can react to events that did not exist in training data. A model may look accurate on past data but fail in live conditions. Explanations may be required for legal or customer reasons. Privacy and security matter because financial data is sensitive. These issues do not mean AI should be avoided. They mean it must be used carefully, with controls, testing, and continuous monitoring.
In practice, good financial AI projects often begin small. A team identifies a narrow decision, gathers usable data, builds a baseline with simple rules or statistics, then tests whether machine learning adds value. They measure not only technical performance but also business outcomes: fewer fraud losses, faster approvals, better forecasting accuracy, lower review cost, or improved risk oversight. This disciplined approach is usually more successful than starting with a vague goal like "use AI everywhere."
That is the foundation you need going forward. AI in finance is not a separate world from finance. It is a toolset inside finance, shaped by data quality, business objectives, workflow design, and risk management. If you can explain that clearly, read basic data examples, and stay alert to common errors and limitations, you already have the right beginner mindset for deeper study in the chapters ahead.
1. According to the chapter, what is the simplest everyday-language way to think about AI in finance?
2. What is one of the chapter's main points about how finance creates value from AI?
3. Which question is one of the four practical questions the chapter says to keep in mind?
4. Why does the chapter say the simplest reliable method is often the best place to begin?
5. What is a key limitation of financial AI highlighted in the chapter?
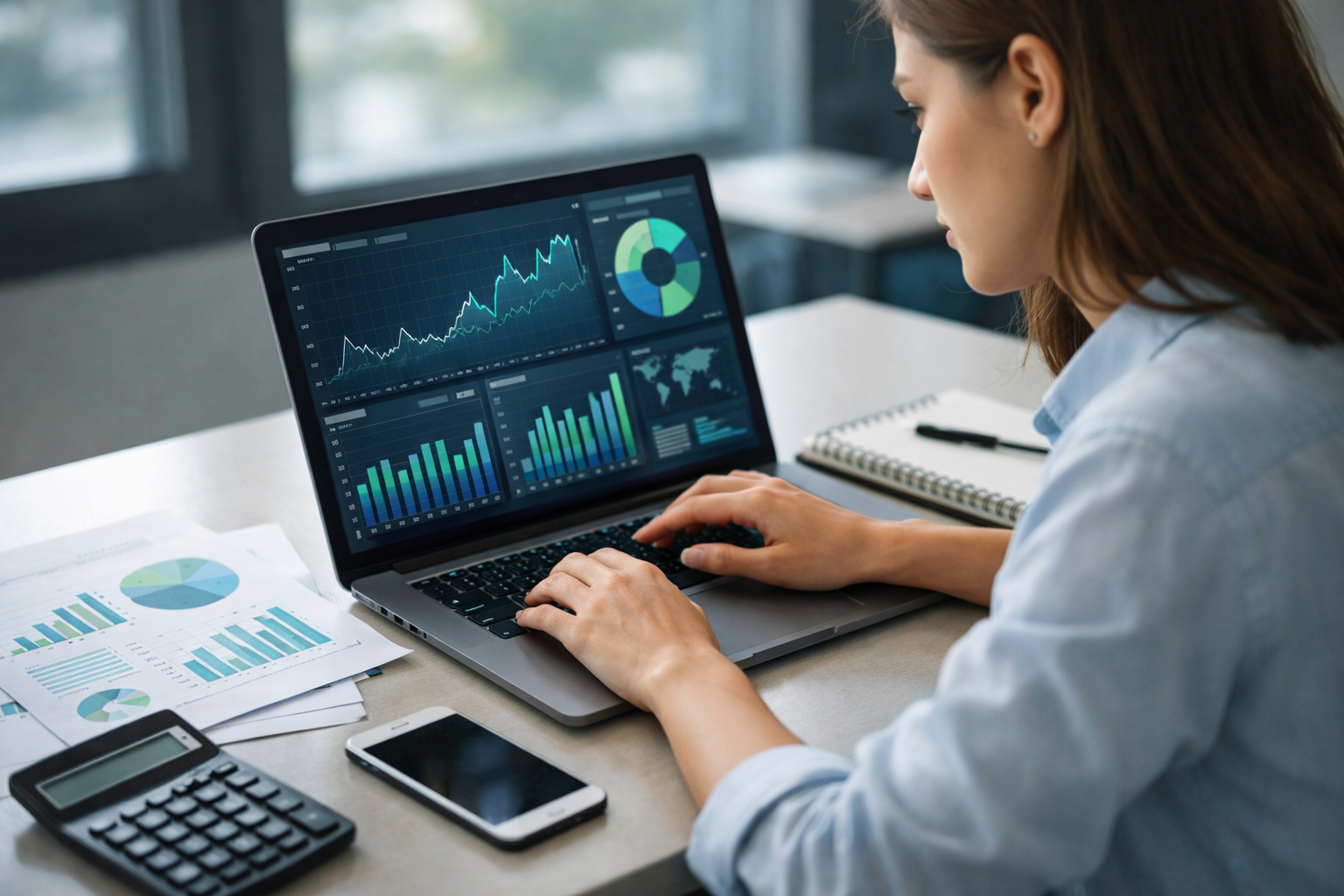
Before an AI system can help with forecasting, fraud detection, credit decisions, or portfolio analysis, it needs data. In finance, data is the raw material. It includes prices, payments, balances, customer details, company reports, news headlines, and many other signals. Beginners often imagine AI as a smart machine that somehow "knows" what is happening in the market. In practice, AI is only as useful as the information it receives and the care used to prepare that information. This is why understanding financial data is one of the most important early skills in AI for finance.
In this chapter, you will learn the basic types of financial data and see how raw information becomes useful input for an AI system. You will also learn why clean data matters so much. A small error in a spreadsheet, a missing transaction timestamp, or mislabeled customer information can create weak predictions or unfair decisions. Good AI work in finance is not only about algorithms. It is also about judgment: choosing the right data, checking whether it is reliable, and understanding what it can and cannot say.
Financial data comes in different forms. Some of it is highly organized, such as a table of daily stock prices or a list of transactions. Some is less organized, such as emails, research reports, customer messages, and earnings call transcripts. AI systems may use both. For example, a fraud model may combine transaction amounts with short text descriptions from merchants. An investment system may combine historical market prices with company filings and news articles. The key idea is simple: raw information becomes useful only when it is collected, cleaned, labeled, and arranged in a way a model can learn from.
As you read this chapter, focus on practical reading skills rather than technical stress. You do not need advanced mathematics to understand the examples. Think like an analyst or business user. Ask: What kind of data is this? Where did it come from? Is it complete? Is it current? Could it be biased? Would I trust it in a real decision? These are the habits that support strong AI use in banking, investing, and risk management.
By the end of this chapter, you should be able to read basic financial data examples with confidence, explain why some data is easier for AI to use than others, and describe simple steps that turn raw records into model-ready input. This foundation will help you later when you study forecasting, classification, and risk tools in more detail.
Practice note for Learn the basic types of financial data: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for See how raw information becomes useful input: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand why clean data matters: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Read simple examples without technical stress: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Financial data is not one single thing. It appears in several common forms, and each form gives AI a different type of signal. The easiest type to recognize is numerical data. This includes stock prices, account balances, loan amounts, credit scores, interest rates, profit margins, and payment totals. Numbers are often the first data type used in finance because they fit naturally into tables and are easy to calculate with.
Text is also important. Financial text includes news stories, analyst reports, customer support messages, compliance notes, contract language, and earnings call transcripts. AI can use text to detect sentiment, identify topics, extract names or amounts, or flag unusual wording. For example, a bank might scan customer emails for signs of payment problems, while an investment team might scan company news for positive or negative signals.
Images appear more often than many beginners expect. In finance, images may include scanned identity documents, checks, invoices, receipts, signatures, or charts. AI systems can read and classify visual data, but image quality matters. A blurry invoice or poorly scanned ID can reduce reliability. This reminds us that data quality is not just about numbers being correct. It also includes readability and consistency.
Transactions deserve special attention because they are central to many financial AI systems. A transaction record may include date, time, amount, merchant, account ID, location, and payment type. These records are used in fraud detection, spending analysis, anti-money laundering reviews, and customer behavior modeling. One transaction may look harmless on its own, but patterns across hundreds of transactions may reveal risk or opportunity.
In practice, strong financial AI often combines these data types. A fraud model might use transaction values, merchant text descriptions, and a scanned receipt. A lending model might combine income numbers, application text, and document images. The engineering judgment comes from deciding which signals are useful and which may add noise. Beginners should remember a simple rule: the same business problem can look very different depending on whether the AI is reading numbers, language, images, or transaction patterns.
Another useful way to understand financial data is by its business source. Three common categories are market data, customer data, and company data. Market data includes prices, trading volume, bid and ask quotes, index values, and economic indicators such as inflation or unemployment. Investors and traders use this data for forecasting, trend analysis, portfolio decisions, and risk monitoring. If an AI system tries to predict short-term price movement, market data is often its starting point.
Customer data is common in banking, insurance, and lending. It may include age, income range, account history, repayment behavior, product usage, customer service interactions, and transaction activity. This data supports use cases such as credit scoring, churn prediction, fraud monitoring, and personalized offers. Because customer data involves people, it requires extra care. Privacy, consent, fairness, and security are not side issues. They are central design concerns.
Company data includes financial statements, earnings reports, balance sheets, cash flow statements, debt levels, management guidance, business descriptions, and regulatory filings. This data helps investors evaluate business health and helps lenders assess credit risk. For example, an AI model might compare revenue growth, debt ratios, and profitability across firms to support a screening process.
These categories are often combined. A lender may use customer repayment data and broader economic conditions. An investor may use company reports together with market prices and news sentiment. A fraud team may combine customer behavior with transaction data and known merchant risk profiles. The practical outcome is that useful AI usually needs context. One dataset in isolation can be misleading.
A common beginner mistake is assuming all financial datasets are equally trustworthy. In reality, market feeds may update every second, customer records may contain missing values, and company filings may arrive with delays. Good AI work means understanding the strengths and limits of each source. Ask who created the data, why it was collected, how often it changes, and whether it is suitable for the decision being made.
Financial data is often described as either structured or unstructured. Structured data fits neatly into rows and columns. Examples include a table of daily stock prices, a loan book, or a transaction history. Each column has a clear meaning such as date, amount, or account number. Structured data is easier for traditional reporting systems and many machine learning tools to handle.
Unstructured data is less tidy. It includes free-form text, PDFs, images, audio recordings, chat messages, and document scans. A company annual report in PDF form, a customer complaint email, or an earnings call recording are all examples. This data can contain valuable insights, but it usually takes more work to turn into usable input. AI may need to extract text from documents, identify topics, summarize language, or convert speech into text.
For beginners, the key idea is not to think of structured data as good and unstructured data as bad. Both can be powerful. Structured data is usually faster to work with and easier to validate. Unstructured data often carries richer context. A transaction amount tells you what happened in one narrow sense. A customer message may explain why it happened. A company filing may reveal risk factors that do not appear in a simple numerical table.
The workflow also differs. With structured data, teams often focus on missing values, date formats, and consistency across columns. With unstructured data, they may need to clean spelling issues, remove irrelevant text, segment documents, or classify content before modeling. This is why raw information does not automatically become useful input. It must be shaped into features, labels, or summaries that match the business goal.
A practical example helps. Suppose a bank wants to identify customers at risk of leaving. Structured data may show fewer logins and lower account activity. Unstructured data may show frustration in support chats. Combining both can produce a better view. Good engineering judgment means balancing effort and benefit. Sometimes a clean table is enough. Sometimes the missing insight lives in messy text.
To understand financial AI, it helps to know where data comes from and how it is stored. Data may be collected from internal systems such as banking apps, payment platforms, trading systems, customer relationship tools, and accounting software. It may also come from external vendors such as market data providers, credit bureaus, public regulators, and news services. Some data arrives in real time, while other data is updated daily, monthly, or only when an event occurs.
Collection methods matter because they affect quality. Real-time transaction feeds support instant fraud alerts, but they may contain temporary errors or incomplete fields. Batch files delivered at the end of the day may be cleaner, but too slow for certain tasks. In investing, delays of even a few minutes may matter for trading decisions. In credit risk, a monthly update may be acceptable for some monitoring tasks. The right choice depends on the use case.
Storage also matters. Financial data is often stored in databases, spreadsheets, data warehouses, cloud storage systems, or reporting platforms. Structured data may live in relational tables. Documents and images may be stored separately. One challenge is linking records correctly across systems. A customer might appear under slightly different names or IDs in different databases. If those records are not matched properly, the AI may build an incomplete or misleading view.
From a practical perspective, teams usually create pipelines. A pipeline is a repeatable process that collects data, checks it, cleans it, and moves it into a location where analysis or AI can use it. This is an engineering discipline, not just a technical detail. A model trained on one version of data and deployed on another may fail in production. Consistency between training data and real operating data is essential.
A common mistake is treating storage as only an IT issue. In finance, storage choices influence security, privacy, speed, auditability, and model trust. If a firm cannot show where data came from, when it changed, and who accessed it, it may face both operational and regulatory problems. Good AI starts with well-managed data flows, not just clever modeling.
Clean data matters because financial AI can amplify small errors into large business consequences. One common problem is missing data. A customer income field may be blank, a transaction may lack a location, or a market feed may skip a time point. Another problem is inconsistent formatting. Dates might appear in different styles, currencies may be mixed, and category labels may vary across systems. Even simple duplicates can distort analysis if the same transaction is counted twice.
There are also timing issues. If one dataset updates daily and another updates monthly, combining them can create a false picture. In forecasting, using information that would not have been available at the prediction time is a serious mistake. This is sometimes called data leakage. It makes a model appear smarter than it really is.
Bias is another major concern. Data may reflect past decisions, social inequalities, customer selection effects, or operational habits. For example, if a bank historically approved loans unevenly across groups, a model trained on those records may learn those patterns rather than true creditworthiness. In fraud data, only detected fraud is labeled, while undetected fraud remains hidden. This means the training data may not represent reality fully.
Noise is also common. News headlines can be sensational, merchant names may be inconsistent, and customer-entered text may contain errors. Some variables look useful but are unstable over time. A signal that worked during one market period may fail in another. Practical AI requires skepticism. Do not assume a strong pattern will remain strong forever.
The practical outcome is clear: before trusting an AI result, examine the data. Check completeness, consistency, recency, representativeness, and fairness. Ask whether any groups are underrepresented, whether labels may be wrong, and whether the dataset reflects the real decision environment. In finance, poor data does not just lower accuracy. It can create unfair outcomes, missed fraud, bad investments, and weak risk controls.
Once data is collected, the next step is preparation. This is the stage where raw information becomes useful input. For beginners, it helps to think of a simple workflow. First, define the business question clearly. Are you trying to flag suspicious transactions, estimate loan risk, forecast sales, or understand market sentiment? The question determines what data should be kept and what can be ignored.
Second, gather relevant records and inspect them. Look at sample rows, text fields, and timestamps. Check whether values make sense. An account balance of negative one billion may be possible, but it may also be a data entry issue. Third, clean the data. Remove obvious duplicates, standardize formats, fix or mark missing values, and align units such as currency or date style. This step is often less glamorous than modeling, but it has huge value.
Fourth, organize the data into useful columns or features. For transaction data, that might include average spending, number of payments per week, or unusual activity by location. For text, it might mean extracting keywords, sentiment, or document categories. For company statements, it might mean calculating ratios such as debt-to-equity or revenue growth. This is where engineering judgment matters most. Good features reflect business meaning, not just available columns.
Fifth, label data when needed. In supervised machine learning, examples need outcomes such as fraud or not fraud, default or no default. Labels must be as accurate as possible. Weak labels create weak models. Sixth, split data carefully for training and testing, especially by time in financial problems. You want evaluation to resemble real use, not an artificial shortcut.
Finally, document what you did. Record data sources, assumptions, cleaning rules, and known limits. This improves trust, repeatability, and compliance. A beginner-friendly summary is this: collect, inspect, clean, organize, label, test, and document. If you can explain these steps clearly using simple financial examples, you already understand an essential part of how AI supports forecasting and risk decisions in the real world.
1. Why is understanding financial data an important early skill in AI for finance?
2. Which example best shows less organized financial data?
3. According to the chapter, what helps turn raw information into useful AI input?
4. Why does clean data matter so much in finance AI?
5. Which question reflects the practical mindset the chapter recommends when reading data?
When beginners hear the words machine learning, they often imagine advanced equations, mysterious code, or a black box that only specialists can understand. In finance, that fear can be even stronger because money, risk, and regulation are involved. The good news is that you do not need to start with math formulas to understand what machine learning is doing. At its core, machine learning is a practical way to learn patterns from examples and then use those patterns to make useful predictions on new cases.
In finance, this matters because many business problems involve repeated judgments based on data. A bank may want to estimate whether a borrower is likely to repay a loan. A payments company may want to flag suspicious transactions. An investment team may want to forecast the chance of a stock moving up or down over the next period. In each case, the system is not “thinking” like a person. It is finding relationships in historical data and applying them to new observations.
This chapter will help you separate machine learning from the hype. You will see how learning systems differ from fixed rules, how training data shapes results, why predictions are not the same as decisions, and what basic terms you will hear again and again in financial AI projects. The goal is not to turn you into a data scientist overnight. The goal is to give you a working mental model so you can read examples, ask better questions, and avoid common beginner mistakes.
A useful way to think about machine learning is this: data goes in, a pattern is learned, a prediction comes out, and then a human or business process decides what to do next. That last part is important. Many problems in finance are not solved by prediction alone. A model may estimate risk, but a policy decides whether to approve a loan. A fraud model may score a transaction, but an operations team decides whether to block it, review it, or allow it. Good finance AI work is therefore not just about building a model. It is about building a reliable workflow around that model.
As you read the sections in this chapter, keep an engineering mindset. Ask: What data is available? What is the model trying to predict? How will the result be used? What happens when the model is wrong? Those questions matter more than memorizing technical jargon. Finance rewards careful judgment, not just clever modeling.
Another important point is that machine learning is not automatically better than simple logic. Sometimes a basic rules-based approach is cheaper, clearer, and easier to control. Other times, patterns are too complex for manual rules, and a learning system provides better results. The practical skill is knowing the difference. That is one reason this chapter focuses not only on definitions, but also on workflow, limits, and outcomes in real finance settings.
By the end of this chapter, you should be comfortable with the beginner language of machine learning in finance. You should be able to explain how a model learns from historical examples, recognize common prediction types such as classification and scoring, and understand why model accuracy must always be balanced with caution. Most importantly, you should see that machine learning is not magic. It is a tool, and like any tool in finance, it must be used with discipline.
Practice note for Understand how machine learning learns from examples: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
A rules-based system follows instructions written in advance by people. If condition A happens, do action B. This is common in finance because rules are clear, fast, and easy to audit. For example, a bank might create a rule that flags any card transaction above a threshold if it occurs in a country where the customer has never used the card before. That is straightforward and useful.
Machine learning is different. Instead of writing every rule by hand, you provide many past examples and let the system learn patterns associated with an outcome. For instance, rather than defining every possible fraud rule, you might train a model on historical transactions labeled as fraud or not fraud. The model can detect combinations that humans may not think to write explicitly, such as unusual timing, merchant patterns, device changes, and transaction sequences.
Neither approach is universally better. Rules work well when the logic is stable, regulation requires transparency, or the behavior is easy to describe. Machine learning is helpful when patterns are complex, changing, or too numerous for manual rule writing. In practice, finance teams often combine both. They may use hard rules for legal or policy requirements and machine learning for risk estimation or anomaly detection.
A common beginner mistake is to assume machine learning replaces judgment. It does not. You still need to define the problem clearly, choose what outcome matters, and decide how predictions will be used. Another mistake is to use machine learning when simple rules would solve the problem at lower cost. Good engineering judgment means choosing the simplest method that reliably meets the business need.
In real organizations, rules and learning systems often live side by side. A fraud platform may include strict rules for known high-risk situations, plus a machine learning score for subtle behavior. A lending process may use eligibility rules before a model ever sees an application. Understanding this mixed approach is essential because finance systems are built for control as well as performance.
Machine learning learns from examples, and those examples are called training data. In a finance setting, training data might include rows of past transactions, loan applications, insurance claims, or market observations. Each row contains information about a case, and often a known outcome. For example, a loan dataset may include applicant income, debt level, repayment history, and whether the loan was eventually repaid or defaulted.
The model does not learn because someone explains the financial theory to it in plain language. It learns by finding repeated relationships between inputs and outcomes in the historical data. If certain combinations of variables often appear before a missed payment, the model may assign higher risk to future cases with similar patterns. This is why data quality matters so much. If the training data is messy, outdated, biased, or mislabeled, the learned pattern can also be poor.
Beginners should know a few practical terms. Features are the input columns used by the model, such as account age, transaction amount, or volatility. A label is the outcome the model tries to learn, such as fraud/not fraud or paid/defaulted. Training means fitting the model on historical examples. A pattern is a relationship the model detects, whether simple or complex.
One of the most important lessons here is that machine learning does not discover truth in a perfect sense. It discovers patterns in the data it was given. If market behavior changes, customer behavior shifts, or fraudsters adapt, old patterns may weaken. That is why finance teams monitor models after deployment. A model trained on last year's environment may not perform the same way next year.
Practical work often begins with simple questions: Do we have enough relevant data? Is the outcome recorded consistently? Are we using information that would really be available at prediction time? Those questions are more valuable than jumping straight into software. In finance, a disciplined dataset usually matters more than a fancy algorithm.
To understand machine learning comfortably, think in terms of inputs and outputs. Inputs are the facts you provide to the model. Outputs are what the model produces. In finance, inputs might include credit utilization, account age, income band, transaction time, number of recent failed login attempts, price history, or balance changes. The output could be a class, a number, or a score.
A prediction is the model's estimate based on those inputs. For example, a fraud model might output a fraud probability score of 0.82, meaning the case looks high risk relative to the examples it learned from. A credit model might estimate the chance of default over the next 12 months. A market model might forecast tomorrow's price movement range. These are predictions, not final actions.
This distinction matters because prediction and decision are not the same thing. Suppose a model predicts that a transaction has a 20% chance of being fraudulent. One company might block it immediately because fraud costs are high. Another might send it for review because blocking good customers is expensive. The same prediction can lead to different decisions depending on business policy, customer experience, legal limits, and risk appetite.
Beginners often mix up model output with business action. That creates confusion. A model can be excellent at ranking risk but still be poorly used if the decision thresholds are badly chosen. In engineering terms, the model is only one component. The operating process around it is equally important.
When reading finance AI examples, always ask three things: What are the inputs? What exactly is being predicted? What decision will this prediction support? Those questions quickly reveal whether a project is well designed. They also help you spot unrealistic claims, especially when people talk as if a model “makes decisions” by itself. In well-run finance systems, humans and business rules still shape the final action.
Many beginner finance AI problems fall into three broad categories: classification, forecasting, and scoring. Knowing these categories makes technical discussions much easier to follow. A classification problem asks the model to place a case into a group. For example, is this transaction likely fraud or not fraud? Is this customer likely to churn or stay? Is this loan likely to default or remain current?
Forecasting deals with future values. In finance, this may mean estimating next month's cash flow, predicting short-term demand for liquidity, or forecasting a market variable such as volatility, revenue, or claims volume. Forecasting does not have to be perfect to be useful. Even a rough estimate can improve planning, inventory, staffing, hedging, or capital allocation when used carefully.
Scoring is common in financial operations. Instead of a simple yes/no answer, the model gives a ranked risk or opportunity score. Credit scores are a familiar example. Fraud risk scores, customer lifetime value scores, and lead-quality scores work in a similar way. A score helps teams prioritize. Higher-risk or higher-value cases can be reviewed first, monitored more closely, or routed into different workflows.
These categories are closely connected. A fraud score may later be turned into a fraud classification using a threshold. A forecast might feed a decision rule. A credit score might support approval, pricing, or review decisions. That is why understanding the business purpose matters. The same model output can be useful in several ways.
A common practical mistake is choosing the wrong framing. For instance, a team may try to forecast exact price movements when what they really need is a simpler risk category or direction estimate. In finance, simpler outputs are often more stable and easier to operationalize. Good project design means choosing an output that matches the decision you need to support, not the most impressive-sounding prediction type.
No machine learning model is perfect, especially in finance where behavior changes, data can be noisy, and incentives can shift. A beginner-friendly but essential idea is that every model makes errors. The real question is not whether errors exist, but what kind of errors occur, how often they happen, and how costly they are.
Consider fraud detection. If the model misses fraudulent transactions, the business loses money. If it wrongly flags legitimate transactions, customers become frustrated and may leave. In lending, approving a risky borrower can create losses, while rejecting a good borrower means losing profitable business and potentially treating customers unfairly. Finance teams therefore care not only about overall accuracy, but about the trade-off between different error types.
Overconfidence is a common danger. A model may look strong in testing but fail in real use because market conditions changed, customer behavior shifted, or the data pipeline introduced issues. Sometimes teams trust a score too much because it comes from an AI system. That is risky. A polished dashboard does not guarantee a reliable model.
Practical teams build safeguards. They monitor performance over time, review unusual cases, compare outcomes against expectations, and keep fallback processes available. They also remember that historical data can contain bias or blind spots. If the past was distorted, the model may repeat those distortions.
As a beginner, develop the habit of asking: What happens when this model is wrong? Who absorbs the cost? Can a human review edge cases? Is the model being used beyond the conditions it was trained for? These are not advanced questions. They are the foundation of responsible AI in finance. Strong systems are not the ones that claim certainty. They are the ones designed to handle uncertainty safely.
A simple financial AI workflow can be described in plain language. First, define the business problem clearly. For example: “We want to identify transactions that deserve fraud review.” Second, gather historical data relevant to that problem, such as transaction amount, time, merchant type, device information, location signals, and the final fraud outcome if known.
Third, prepare the data. This often includes cleaning missing values, standardizing formats, removing obvious errors, and selecting useful input features. Fourth, train a model on past examples so it can learn relationships between inputs and outcomes. Fifth, test the model on data it has not already seen to check whether it generalizes beyond the training set.
Next comes deployment. The model begins receiving new live inputs and producing predictions or scores. But the workflow does not end there. A business rule or human team interprets the output and makes a decision, such as approve, decline, route to manual review, or request more verification. Finally, performance is monitored over time. If outcomes drift, the model may need retraining, adjustment, or replacement.
This workflow sounds simple, but engineering judgment appears at every step. Are the labels trustworthy? Are we accidentally using information from the future? Is the data available quickly enough for real-time decisions? Are the thresholds aligned with risk appetite? Will customer support be prepared when false alarms increase? These are implementation questions, and they often matter as much as model choice.
A beginner should take away one big idea: machine learning in finance is not just about building a clever predictor. It is about building a controlled process that connects data, modeling, decision rules, operations, and monitoring. When done well, AI can support forecasting and risk decisions in a practical way. When done poorly, it can scale mistakes faster. The difference is rarely magic. It is usually process discipline.
1. According to the chapter, what is the core idea of machine learning?
2. What is the main difference between a rules-based system and a learning system?
3. Which example best shows the difference between prediction and decision?
4. Why does the chapter say machine learning is not automatically better than simple logic?
5. What mindset does the chapter encourage beginners to use when thinking about machine learning in finance?
In earlier chapters, you learned the basic idea of AI in finance, how data differs from rules, and why machine learning is useful when patterns are too complex to write by hand. In this chapter, we move from theory into practice. The goal is not to make AI sound magical. Instead, the goal is to show where AI is actually used in real financial workflows, what problems it is good at solving, and where its limits become obvious.
For beginners, one of the most important lessons is that most financial AI systems do not replace an entire job. They usually support a narrow step in a larger process. A bank may use AI to flag suspicious transactions, but compliance staff still investigate. A lender may use AI to estimate credit risk, but loan policies and regulations still control decisions. An investment platform may use AI to summarize market trends, but portfolio managers still decide position sizes, risk limits, and client suitability. In other words, AI often acts as an assistant inside a workflow, not a fully independent decision maker.
Another practical lesson is that AI can only work with the data and objective it is given. If the data is incomplete, delayed, biased, or poorly labeled, the system will produce weak results. If the objective is too narrow, the model may optimize the wrong thing. For example, a model trained only to predict which customers are likely to miss payments might ignore fairness concerns, changing economic conditions, or legal requirements. In finance, good engineering judgment means asking not only, “Can the model predict something?” but also, “Should we use it for this decision, and how will people review it?”
This chapter explores beginner-friendly use cases in banking, investing, and trading. As you read, notice four ideas that appear again and again. First, AI works best when tied to a clear business task. Second, AI predictions are not guarantees. Third, every system sits inside a process with controls, exceptions, and human oversight. Fourth, humans matter most when decisions affect customers, money, risk, and trust. These patterns will help you understand what AI can and cannot do in finance today.
By the end of this chapter, you should be able to recognize several common finance use cases, connect them to real workflows, and explain why the best financial AI systems combine data, models, controls, and human decisions.
Practice note for Explore the most common beginner-friendly use cases: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand what AI can and cannot do in practice: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Relate AI tools to real finance workflows: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Identify where humans still matter most: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Explore the most common beginner-friendly use cases: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Fraud detection is one of the clearest and most common uses of AI in banking and payments. Every day, financial institutions process huge numbers of card transactions, transfers, logins, account updates, and withdrawals. Hidden inside that stream are a small number of suspicious events. AI helps by scanning activity at a scale and speed that people cannot manage manually.
A typical workflow starts with transaction data such as amount, merchant type, device used, time of day, location, account history, and prior fraud outcomes. A model looks for unusual patterns: a purchase in a country the customer has never visited, many rapid transactions in a short period, a login from a new device followed by a password reset, or behavior that resembles known fraud cases. Some systems use rules first, such as blocking a transaction above a certain amount from a sanctioned region. Others add machine learning to score risk more flexibly.
This is a good example of what AI can do well in practice. It can rank alerts, detect patterns that are not obvious, and adapt as fraud methods change. But it also shows what AI cannot do perfectly. A flagged transaction is not automatically fraud. False positives are common. If a customer is traveling or buying an unusually expensive item, valid activity may look suspicious. That is why banks balance security with customer experience and often route high-risk cases to investigators.
A common beginner mistake is to assume that higher detection rates are always better. In reality, too many alerts can overwhelm staff and frustrate customers. Good engineering judgment means tuning the system so that the most important cases are reviewed first. Practical outcomes matter: lower fraud losses, fewer unnecessary card declines, faster case handling, and clear escalation paths for human teams.
Credit scoring is another major AI use case. Banks and lenders want to estimate the likelihood that a borrower will repay a loan. Traditionally, this process relied heavily on fixed scorecards and rules based on income, debt, repayment history, and credit utilization. Today, machine learning is often used to improve prediction accuracy by finding more complex relationships in historical lending data.
In a real workflow, the lender collects application data, checks credit reports, verifies identity, and applies policy rules. Then a model may estimate default risk, expected loss, or probability of late payment. This output is not usually the final answer by itself. It becomes one input into a broader decision that can include affordability checks, compliance constraints, product limits, and manual review. For example, a model might predict moderate risk, but the loan could still be declined if required documents are missing or if the customer fails a policy rule.
This use case helps beginners understand the difference between data, rules, and machine learning. Data includes the borrower’s financial profile and payment history. Rules include hard business constraints such as age requirements or debt-to-income caps. Machine learning estimates risk from patterns in past loans. All three work together. If any one part is weak, the process suffers.
The limits are important. Credit models can reflect bias in historical data, especially if past decisions were unfair or inconsistent. Economic conditions can also change quickly. A model trained in a low-interest environment may perform poorly when inflation rises or unemployment increases. Human judgment matters most when cases are borderline, when fairness concerns appear, or when regulation requires explainability. A practical outcome is not just more approved loans. It is better risk selection, more consistent decisions, and responsible lending that can be defended to customers and regulators.
Financial chatbots are one of the most visible uses of AI for everyday customers. Banks, brokers, and payment apps use them to answer common questions, guide users through simple tasks, and reduce the workload on service teams. A chatbot might help a customer check account activity, explain card charges, reset login steps, locate fee information, or provide budgeting reminders.
From a workflow perspective, chatbots are most effective when they are connected to clear service processes. They classify the customer’s intent, retrieve relevant information, and respond using approved content. More advanced systems can summarize account activity or detect that a user may be asking about fraud, disputes, or urgent access issues. The best systems know when to transfer the case to a human agent. That handoff is a critical design choice, not a failure.
What can AI do well here? It can provide fast responses, handle repetitive requests, and stay available at all hours. What can it not do well? It may misunderstand vague questions, misread emotional context, or offer an answer that sounds confident but is incomplete. In finance, that matters because customers may act on the information. A wrong answer about a payment deadline, margin requirement, or loan fee can create real harm.
Common mistakes include allowing the chatbot to answer beyond its approved scope, failing to log unresolved requests, or not giving users a clear path to a human. Practical engineering judgment means limiting automation in high-risk situations. A chatbot can be useful for balance queries and process guidance, but a disputed transfer, hardship case, or account lockout often needs a trained employee. The practical outcome is better service efficiency without losing trust, control, or accountability.
In investing, AI is often used to generate portfolio insights rather than make perfect predictions. Beginners are sometimes told that AI can forecast markets easily, but real investment work is much messier. Markets are influenced by earnings, rates, macroeconomic events, regulation, sentiment, and unexpected news. AI can help organize information and estimate probabilities, but it does not eliminate uncertainty.
A practical use case is portfolio monitoring. An AI system may analyze price changes, volatility, correlations, sector exposure, earnings reports, and news sentiment to highlight potential risks or opportunities. For example, it might detect that a portfolio has become too concentrated in one industry, that several holdings are reacting to the same macro factor, or that recent news has shifted sentiment around a company. This helps analysts focus their attention where it matters.
Forecasting models may also estimate likely ranges for returns, volatility, or drawdowns. But these are scenario tools, not crystal balls. A useful model might say that under current conditions a portfolio has elevated downside risk, or that a stock’s behavior resembles past periods before higher volatility. That can support rebalancing, hedging, or position review. It should not be treated as a guarantee of what will happen next week.
One common mistake is overfitting: building a model that looks excellent on past data but fails in live markets. Another is confusing correlation with causation. Just because two variables moved together historically does not mean one truly predicts the other. Human judgment remains essential for interpreting regime changes, deciding whether market conditions have shifted, and understanding whether a model is reacting to meaningful information or noise. The practical outcome of AI here is better awareness, faster research support, and more disciplined risk discussions.
AI in trading often starts with signal generation. A signal is a suggestion such as buy, sell, reduce exposure, or wait. The input data can include price history, volume, order book behavior, volatility, technical indicators, news, or alternative data. Machine learning models try to identify patterns associated with short-term price moves or changing market conditions.
For beginners, it is important to understand the full workflow. First, data is collected and cleaned. Then features are created, such as moving averages, momentum measures, or event indicators. A model produces a score or probability. After that, trading rules convert the score into an action. Finally, risk controls decide order size, stop levels, trading hours, and whether the system should trade at all. This means a real trading system is never just a model. It is a model surrounded by engineering, safeguards, and execution logic.
What can AI do well in this setting? It can process many signals quickly, adapt to changing short-term patterns, and react faster than a person in structured environments. But the limits are serious. Markets change, transaction costs matter, slippage reduces returns, and a profitable backtest may disappear in live trading. A model can also become unstable when data quality drops or when many traders exploit similar patterns.
A frequent beginner mistake is focusing only on prediction accuracy instead of trading performance after costs and risk limits. Another is automating too early without supervision. In practice, firms often begin with decision support, then partial automation, and only later allow broader execution. Humans still matter in setting strategy, reviewing model drift, pausing systems during unusual events, and deciding when not to trust the signal. The practical outcome is not guaranteed profits. It is a more systematic, testable approach to generating and acting on market ideas.
The most important lesson in this chapter is that financial AI works best when humans and machines do different parts of the job well. Machines are strong at scale, consistency, and pattern detection across large datasets. Humans are strong at context, ethics, accountability, and handling unusual situations. Good finance workflows combine these strengths rather than treating them as competitors.
Think about the use cases in this chapter. In fraud detection, AI narrows millions of transactions into a manageable queue, but investigators decide what is truly suspicious. In lending, models estimate risk, but policies, fairness checks, and compliance rules shape the final decision. In customer service, AI handles repetitive questions, but humans step in when nuance or empathy is needed. In investing and trading, models generate insights or signals, but people still define objectives, challenge assumptions, and control exposure.
Engineering judgment matters here because every machine suggestion is shaped by design choices: what data was used, what target was predicted, how often the model is retrained, what threshold triggers action, and what happens when confidence is low. If teams forget these choices, they may trust a model too much simply because it appears quantitative. That is a dangerous mistake in finance.
A practical rule for beginners is this: the higher the financial impact, regulatory sensitivity, or customer harm, the more carefully human oversight should be designed. Humans matter most in exceptions, appeals, high-value decisions, model validation, and crisis conditions. AI can support forecasting and risk decisions, but it cannot carry responsibility by itself. The strongest practical outcome is not full automation. It is better decision quality through controlled collaboration between machine suggestions and informed human judgment.
1. According to the chapter, what is the most common role of AI in finance workflows?
2. Why might an AI model produce weak results in a financial setting?
3. What is a key limit of using a model trained only to predict missed payments?
4. When does the chapter say humans matter most in AI-assisted finance?
5. Which statement best matches the chapter's view of machine learning versus rules?
AI can be useful in finance, but it is never risk-free. In earlier chapters, you saw how AI can help with fraud detection, forecasting, scoring, and decision support. This chapter adds an essential balance: whenever AI is used around money, customers, credit, trading, or compliance, mistakes can become expensive very quickly. A model may look accurate in testing and still fail in the real world. A system may save time and still create unfair outcomes. A dashboard may feel trustworthy while hiding major weaknesses. For beginners, the most important lesson is simple: financial AI should be treated as a helpful tool, not as an unquestioned authority.
The main risks of using AI in finance usually fall into a few categories. First, models can be wrong because data is incomplete, old, noisy, or biased. Second, outputs can look precise even when uncertainty is high. Third, sensitive customer data can be exposed or mishandled. Fourth, a model can produce unequal outcomes for different groups, even if no one intended that result. Fifth, users may trust the system too much and stop applying human judgment. In finance, that overconfidence is dangerous because decisions affect lending, investments, fraud reviews, insurance pricing, and customer access to services.
Good outputs still need human review. A fraud model might flag a real customer by mistake. A loan model might reject an applicant because of a pattern hidden in the training data rather than current reality. A market prediction model may perform well in calm periods and break during sudden news events. Human review matters because financial systems are full of changing conditions, legal requirements, edge cases, and ethical trade-offs. AI is very good at finding patterns, but it does not automatically understand context, fairness, or accountability in the way people must.
When professionals use AI safely, they do not ask only, “Is the model accurate?” They also ask, “What data created this result? Who might be harmed if the model is wrong? Can we explain the output? Are we protecting private information? When should a person override the machine?” That is the safer mindset this chapter is designed to build. As you read, think like a careful analyst, not just an enthusiastic user. In financial AI, trust must be earned through testing, monitoring, transparency, and responsible use.
The rest of this chapter turns these ideas into practical understanding. You will learn where financial AI can go wrong, why fairness and privacy matter, how explainability supports trust, what regulation expects at a basic level, and how to use a simple checklist before adopting AI in a real workflow. The goal is not to make you afraid of AI. The goal is to help you use it responsibly, with clear eyes and sound judgment.
Practice note for Recognize the main risks of using AI in finance: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Understand fairness, privacy, and transparency simply: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Learn why good outputs still need human review: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Financial AI systems often fail for ordinary reasons, not dramatic science-fiction reasons. Most problems begin with data. If a model is trained on old transaction patterns, old economic conditions, or incomplete customer records, its predictions may not match today’s reality. This is especially common in finance because markets, borrower behavior, fraud tactics, and regulations all change over time. A model that looked excellent last year may become unreliable after interest rate changes, a recession, or a new scam pattern.
Another common issue is target confusion. Teams sometimes build a model to predict what is easy to measure instead of what truly matters. For example, a lending model might predict whether a customer looked risky in old records, but those records may reflect past policies rather than true creditworthiness. In investing, a model may optimize short-term backtest performance while ignoring transaction costs, slippage, or unusual market events. In fraud detection, a system may reduce false negatives but create too many false positives, frustrating legitimate customers.
Engineering judgment matters here. A model should not be judged only by one score such as accuracy. Teams must ask how the system behaves under stress, what happens when inputs are missing, how quickly it degrades when conditions change, and what kind of mistakes are most costly. In finance, different errors have different impacts. Missing a fraud case is costly, but blocking a genuine customer can damage trust and revenue. Approving a risky loan may cause losses, but wrongly rejecting a qualified applicant raises fairness concerns and business risk too.
A practical workflow reduces failure risk. First, define the business decision clearly. Second, inspect the data carefully for gaps, drift, and suspicious patterns. Third, test the model on realistic examples, not only clean historical datasets. Fourth, monitor results after deployment and compare them with human review and business outcomes. Fifth, create fallback rules for uncertain cases. A common mistake is assuming that once a model is deployed, the work is done. In reality, deployment is the start of a monitoring process, not the end of a project.
The practical outcome for beginners is straightforward: never trust a financial AI tool just because it produces neat numbers. Ask what data it learned from, what assumptions it makes, when it was last tested, and what happens when it is wrong. Good financial AI is not magic. It is a managed system with limits, controls, and ongoing review.
Bias in financial AI means that a system may produce systematically worse outcomes for some people or groups. This can happen even when a model does not directly use obviously sensitive attributes such as race or gender. Why? Because other variables can act as indirect signals. Postal code, income pattern, education history, employment gaps, device type, and spending behavior may reflect broader social inequalities. If these patterns are learned without careful review, the model may repeat or even strengthen unfair treatment.
Lending and credit scoring are classic examples. Suppose a model is trained on historical loan approvals and repayments. At first, that sounds sensible. But historical approval data may already contain old human biases, inconsistent policies, or unequal access to credit. The model may then learn the past rather than learn fairness. This is one of the biggest beginner lessons in AI ethics: historical data is not automatically neutral. Data reflects human decisions, and human decisions can be uneven.
Fairness does not mean every person gets the same result. It means the process should be justifiable, consistent, and free from hidden discrimination. In practice, teams should test outcomes across groups, review input features that may act as proxies for protected characteristics, and check whether similar applicants are treated similarly. They should also ask whether there is a business reason for each feature. If a feature improves model performance only slightly but creates fairness concerns, removing it may be the better choice.
Human review remains important because fairness is not a single formula. A model may be statistically strong overall but still cause harm in edge cases. For example, applicants with irregular income, thin credit files, or nontraditional employment may be scored poorly even if they are financially responsible. A reviewer can notice context that the system misses. A safer workflow is to use AI as decision support, especially for borderline cases, rather than as a final automatic gate.
The practical outcome is that fairness should be built into design, testing, and governance from the beginning. If a team asks about bias only after customer complaints arrive, it is already late. Trust grows when users know the system has been examined not only for speed and profit, but also for fairness and consistency.
Financial AI often depends on highly sensitive information: account balances, payment records, identities, salary details, transaction histories, and sometimes location or device data. Because of this, privacy and security are not side topics. They are central design requirements. If an AI system is trained on customer data, connected to internal databases, or used by external vendors, each step creates possible exposure. A useful model is not acceptable if it puts confidential financial information at risk.
A simple way to think about privacy is to ask, “Do we really need this data for the task?” Many teams collect more than necessary because more data feels better. But unnecessary data creates unnecessary risk. Good practice is data minimization: use only the information needed for the job. Also limit who can access it, how long it is stored, and whether it can be linked back to real people. When possible, remove direct identifiers and protect data during storage and transfer.
Security risk goes beyond theft. An attacker may try to manipulate model inputs, steal a model, extract sensitive patterns from outputs, or exploit weak access controls in a dashboard or API. Internal misuse matters too. A system can be technically accurate but operationally unsafe if permissions are too broad or logs are incomplete. Financial firms therefore use controls such as encryption, role-based access, audit trails, vendor review, secure environments, and regular testing.
For beginners, one practical mistake to avoid is pasting real financial data into tools that are not approved for sensitive use. Convenience can create a compliance and trust problem very quickly. Another mistake is assuming that anonymized data is always safe. In some cases, records can still be re-identified when combined with other datasets. That is why privacy protection requires process discipline, not just a label.
The practical workflow is clear: classify the sensitivity of the data, limit collection, secure access, review third-party tools, document retention rules, and monitor for misuse. When a team treats customer data with care, it protects not only compliance but also reputation. In finance, trust is built partly on technical performance and partly on confidence that private information will be handled responsibly.
Explainability means being able to describe, in understandable terms, why a model produced a result. In finance, this matters because people are affected by decisions. A customer may want to know why a loan was declined. A risk manager may need to understand why exposure increased. A compliance team may ask why a transaction was flagged. If the answer is only “the model said so,” trust will be weak, and in some cases that answer is not acceptable.
Not every model is equally easy to explain. Some simple models, rules, or scorecards are more transparent than complex machine learning systems. That does not mean simple always beats complex. It means teams should match model complexity to the task and to the need for explanation. If a slightly simpler model performs almost as well but is much easier to review, validate, and communicate, that may be the wiser engineering decision.
Explainability also supports debugging. If a fraud model suddenly starts flagging too many normal transactions, feature-level explanations can help reveal whether one variable is dominating decisions in an unhealthy way. If a credit model reacts strongly to a noisy or outdated feature, the team can investigate and correct it. Without some level of interpretability, errors can remain hidden behind impressive-looking outputs.
Human review depends on explainability. Reviewers cannot apply sound judgment if they cannot see the main reasons behind an output. A useful workflow is to pair predictions with confidence levels, top contributing factors, and a clear escalation path for uncertain cases. For example, instead of showing only a risk score, a tool might show the main factors that increased the score and note whether the case falls into a gray zone needing manual review.
A common beginner mistake is confusing polished presentation with trustworthiness. A clean dashboard, a probability score, and a chart can make a system feel reliable even when the underlying logic is unstable. True trust comes from evidence: validation, monitoring, documentation, and explanation. The practical outcome is simple. If a financial AI system affects real decisions, users should be able to ask what drove the result, how confident the system is, and when a human should step in. That is the foundation of trustworthy use.
Finance is one of the most regulated industries in the world, so AI cannot be used casually. Exact rules differ by country and by type of institution, but the basic idea is consistent: firms must be able to manage risk, protect customers, keep records, and show that important decisions are made responsibly. AI does not remove those duties. In many cases, it increases the need for governance because model-driven decisions can scale quickly across thousands or millions of customers.
Responsible use begins with clear ownership. Someone must be accountable for the model, the data, the business purpose, and the monitoring process. A model should have documented inputs, assumptions, limitations, and approval steps. It should also have boundaries: what it is allowed to do, what it is not allowed to do, and when it must hand a case to a human. These are not just paperwork exercises. They help reduce the chance of unmanaged behavior in production.
Another core concept is model risk management. This means testing models before use, validating them independently where possible, tracking performance over time, and reviewing changes carefully. If a vendor provides the AI tool, that does not remove the firm’s responsibility. Third-party models still need due diligence. Teams should ask what data was used, how often the model is updated, how bias is tested, and what controls exist for privacy and security.
Responsible use also includes communication. Customers, employees, and reviewers should understand when AI is assisting a process and what recourse exists if a result seems wrong. High-impact decisions should not be hidden behind vague automation. When users know there is oversight, an appeals path, and documentation, trust becomes more realistic and durable.
The practical outcome for beginners is to think in terms of governance, not just technology. A strong financial AI system has a purpose, owner, controls, review path, logs, and limits. Regulation is not there only to slow innovation. It helps make sure innovation does not create unseen harm. In finance, responsible use is part of product quality.
When beginners first work with AI in finance, it helps to have a simple checklist. The checklist does not replace deep technical review, but it creates a safer mindset for real-world use. Start with the purpose. What exact decision or workflow is the AI supporting? If the answer is vague, risk increases immediately. The next question is data. Is the data relevant, recent, complete, and legally usable? Have you checked for missing values, drift, and historical bias? If not, a strong-looking model may still produce weak outcomes.
Then ask about impact. Who could be harmed if the output is wrong? In finance, some mistakes are routine and low impact, while others affect access to credit, customer trust, fraud response, or financial loss. Higher-impact uses deserve stricter controls and more human review. Next, ask whether the system can be explained well enough for the people who must use or oversee it. If a result cannot be understood, challenged, or documented, adoption should slow down until controls improve.
Privacy and security come next. Are you using only the data you need? Is access limited? Are approved tools being used? Are vendor risks understood? After that, consider monitoring. How will you know if performance drops? Who reviews false positives and false negatives? What thresholds trigger retraining, rollback, or escalation? A model without monitoring is like a financial process without reconciliation.
The final and most practical question is this: if the model gives a confident but wrong answer, what happens next? Safe adoption means there is an answer. There is a human owner, a review path, a documented fallback, and a plan to fix the issue. That is how beginners grow into responsible practitioners. The goal is not to avoid AI. The goal is to use it with discipline, fairness, and sound judgment so that useful tools become trustworthy tools.
1. What is the safest way to think about AI in finance according to the chapter?
2. Which is an example of a major risk of using AI in finance?
3. Why does the chapter say good AI outputs still need human review?
4. Which question reflects the safer mindset recommended in the chapter?
5. According to the chapter, fairness, privacy, and transparency should be viewed as:
By this point in the course, you have seen that AI in finance is not magic, and it is not only for large banks, hedge funds, or data scientists. At a beginner level, the most important skill is not building a complex model from scratch. It is learning how to turn broad ideas into a clear, practical action plan. That means knowing how to pick a small problem, connect that problem to a suitable AI approach, judge whether a tool is useful, and decide what to learn next without becoming overwhelmed.
Many beginners make the same mistake: they start with the technology instead of the problem. They ask, “Which AI tool should I use?” before asking, “What financial task am I trying to improve?” In real finance settings, useful AI usually begins with a narrow business need. A team may want to reduce time spent reviewing transactions, improve customer support responses, flag unusual account behavior, summarize reports, or create better forecasting support for planning. These are grounded tasks with visible outcomes. Starting small gives you a better chance to learn, test, and improve.
A practical roadmap also requires engineering judgment. In simple terms, good judgment means choosing methods that match the quality of your data, the cost of mistakes, and the amount of time or expertise available. Not every finance problem needs machine learning. Sometimes a spreadsheet, a rule-based alert, or a checklist gives a better result. In other cases, AI adds value by handling large volumes of repetitive data, recognizing patterns in historical records, or helping a human analyst work faster. The goal is not to force AI into every workflow. The goal is to use it where it supports better decisions, lower risk, or more efficient work.
This chapter brings the earlier concepts together into a beginner roadmap. You will learn how to choose a realistic first use case, evaluate simple tools with confidence, measure value in plain business terms, and create a personal or workplace plan for continuing. Think of this as your transition from understanding AI ideas to using them responsibly in everyday finance work. If you can complete the steps in this chapter, you will have something far more useful than a list of buzzwords: you will have a decision process.
The sections that follow are designed to help you finish this course with a clear roadmap. Whether you want to use AI in your own budgeting and investing tasks, in a bank operations role, in a finance team, or in a small business setting, the same beginner principle applies: keep it narrow, keep it measurable, and keep a human in the loop where the stakes are high.
Practice note for Turn concepts into a practical beginner action plan: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Evaluate simple tools and use cases with confidence: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Know what to learn next without feeling overwhelmed: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Your first AI project in finance should be small enough to explain in one or two sentences. A good beginner problem is specific, repetitive, and connected to a clear outcome. For example: “Help categorize expenses from bank transactions,” “Flag unusual payment activity for review,” “Summarize daily market news into short notes,” or “Estimate next month’s cash inflow using past records.” These are better starting points than vague goals such as “use AI for investing” or “improve our finance department.”
The reason to start small is practical. Finance work contains different levels of risk. Some tasks are low-risk and operational, such as organizing documents or extracting fields from statements. Other tasks are high-risk, such as approving loans, executing trades, or denying transactions. Beginners should begin with tasks where AI supports a person rather than replaces a decision-maker. That creates a safer learning environment and makes it easier to spot errors.
When choosing a problem, ask four simple questions. First, is the task repeated often enough that improvement matters? Second, do you already have example data, even if it is basic? Third, can you tell whether the output is good or bad? Fourth, is the cost of a mistake manageable? If the answer to these questions is yes, you may have a suitable starting use case.
A common mistake is selecting a problem because it sounds advanced. Forecasting stock prices with AI may sound exciting, but it is difficult, noisy, and full of false confidence. A better beginner project might be identifying missing values in transaction records, grouping merchant names, or creating a simple expense trend summary. These problems teach the same core skills: defining inputs, judging outputs, understanding data quality, and learning where automation helps and where it fails.
In a workplace, one useful method is to write a one-page problem note. State the task, who performs it now, how long it takes, what errors occur, what data exists, and what a better outcome looks like. In personal finance, do the same informally. For example, if you struggle to review spending, define the problem as “I want a weekly AI-assisted summary of spending categories and unusual purchases.” That turns a broad interest into a concrete beginner action plan.
Once you have chosen a small problem, the next step is to match it to the right method. This is where many beginners gain confidence, because they realize not every problem requires the same kind of AI. In finance, a task may be solved by plain data handling, fixed business rules, or machine learning. The right choice depends on the structure of the task and the type of data you have.
If the task is stable and easy to define, rules may be enough. For example, “flag transactions above a certain amount from a new location” is a rule-based idea. If the task is mostly organizing or summarizing data, standard software or spreadsheet logic may solve much of it. If the task involves patterns that are hard to define manually, such as spotting unusual combinations of behavior across many transactions, machine learning may help. If the task involves text, such as reading reports, customer messages, or policy documents, language-based AI tools may be appropriate.
Engineering judgment matters here. Beginners should not choose machine learning just because it sounds more impressive. A simple rule is often easier to explain, test, and maintain. In financial settings, explainability and reliability are often more valuable than complexity. For example, a cash-flow forecast based on a transparent moving average may be more useful for a beginner than a black-box model no one can interpret.
A practical way to decide is to use a three-part test. Ask: Is the pattern obvious enough for rules? Is the data consistent enough for analysis? Are there enough examples to learn from? If the answer to the first question is yes, start with rules. If the answer to the second and third questions is strong, then a machine learning approach may be worth trying. If your problem is text-heavy, use a language tool carefully and verify outputs.
The practical outcome is confidence. Instead of thinking “AI” is one thing, you learn to evaluate tools and use cases with more precision. That helps you avoid expensive mistakes and select a solution that fits the task rather than the trend.
Before you trust any AI tool in a finance setting, you should pause and ask basic but important questions. Trust in finance should never come from marketing language alone. A tool may look polished and still produce weak, biased, outdated, or unexplainable results. Beginners do not need advanced technical knowledge to test this. They need a structured checklist.
Start with the data question. What information is the tool using, and is that data relevant, current, and accurate enough for the task? A forecasting tool trained on old patterns may fail when conditions change. A fraud tool may overreact if transaction labels are poor. A chatbot may answer confidently even when the source material is incomplete. In finance, bad input often leads to dangerous output because people may act on it quickly.
Next, ask about errors. What kinds of mistakes can this tool make? Does it create false positives, such as flagging too many normal transactions? Does it create false negatives, such as missing risky behavior? Does it hallucinate text or explanations? Can a human review the output before action is taken? This is especially important in lending, trading, compliance, and customer communication.
Then ask about explainability and control. Can the team describe why the tool gave a result? Can thresholds be adjusted? Is there an audit trail? Can you compare tool recommendations against past human decisions or known examples? Beginners should learn early that a useful finance tool is not only accurate. It is testable, reviewable, and limited to an appropriate role.
Also consider privacy, regulation, and fit for purpose. If customer data is involved, where is it stored? Who can access it? Is the tool approved for the type of financial work being done? A free general-purpose AI service may be helpful for learning concepts, but that does not mean it is suitable for sensitive financial records.
A simple trust checklist can guide you: source of data, known error types, human review process, security controls, performance on sample cases, and business impact if wrong. This habit helps you evaluate tools with confidence instead of fear or blind optimism. It also supports one of the most important beginner lessons in finance AI: useful systems are usually controlled systems, not fully autonomous ones.
A beginner roadmap becomes much stronger when you can explain value in business terms rather than technical terms. In finance, a project does not create value just because it uses AI. It creates value if it saves time, reduces errors, speeds up review, improves consistency, or helps people spot risk earlier. That means your measurement should connect to real work.
For a small project, avoid complicated scorecards at first. Start with a baseline. How is the task done now? How long does it take? How many items are reviewed each day? How often are mistakes found? How often do staff need to recheck results? Once you know the current process, you can compare it to the AI-assisted version.
Suppose a finance team manually labels transactions for reporting. If an AI tool suggests categories and a person approves them, value can be measured by minutes saved per hundred transactions, lower correction rates, or faster month-end completion. If a fraud review team uses anomaly alerts, value might be measured by a higher rate of useful flags, faster triage, or reduced workload on low-risk cases. If a personal finance user employs AI summaries, value could be fewer missed payments, better awareness of spending, or more consistent review habits.
One common mistake is focusing only on accuracy percentages without context. A model that is 95% accurate may still be poor if it fails on the most important 5% of cases. Another mistake is ignoring the cost of review. If a tool creates many weak alerts, staff may spend more time filtering noise than they save. In finance, efficiency and risk quality must be considered together.
If you can explain value this way, you can speak to both personal users and workplace stakeholders. This is how you move from curiosity to a practical use case. Measuring value simply also protects beginners from chasing flashy tools that produce little real improvement.
After choosing a problem and learning how to judge tools, the next challenge is knowing what to learn next without feeling overwhelmed. The best beginner learning path is role-based, not endless. You do not need to master every branch of AI in finance. You need enough knowledge to use tools responsibly, ask the right questions, and continue building confidence in a focused way.
Start with the foundation: data, rules, and machine learning. Be able to explain the difference in plain language. Then strengthen your ability to read simple financial data examples, such as transaction tables, account balances, time series, and labels. After that, learn basic evaluation habits: checking examples, comparing outputs, and identifying obvious errors. This gives you the practical skills to participate in AI discussions even if you are not a technical specialist.
Next, tailor your learning to your interest area. If you work in banking operations, focus on fraud detection, customer service automation, document processing, and risk flags. If you are interested in investing, focus on market data, forecasting limits, sentiment tools, and the dangers of overconfidence. If you work in corporate finance or a small business, focus on cash flow forecasting, invoice matching, anomaly detection, and reporting support. If you are learning for personal use, focus on budgeting summaries, spending analysis, and understanding how tools can mislead.
A useful beginner plan for the next 30 to 60 days is simple: choose one small use case, test one tool on safe sample data, document what works and what fails, and write down three lessons. Then learn one adjacent topic, such as data cleaning, forecasting basics, or model bias. This creates progress without overload.
Do not confuse learning with collecting tool names. Real learning means you can describe a workflow: define the problem, identify the data, choose the method, review the output, measure value, and monitor risk. That is the roadmap that lasts even when tools change. For many beginners, this section is where the course becomes actionable. You now know what to study next and why it matters.
This chapter turns the course into a practical roadmap. You began by learning that the best first step in finance AI is not to chase the most advanced model, but to choose a small and meaningful problem. From there, you learned to match the problem to the right approach, whether that means basic data handling, business rules, machine learning, or language-based AI. You also saw that trust must be earned through questions about data quality, error types, review processes, explainability, and security.
Just as importantly, you learned to measure value in simple business terms. In real finance work, usefulness is often seen through saved time, fewer mistakes, better consistency, or earlier risk detection. This perspective helps you explain why a tool matters and protects you from focusing only on technical novelty. You then built a learning path that is realistic for a beginner: one small use case, one careful test, one clear review process, and one next topic to study.
Your personal or workplace roadmap can now be written clearly. First, define one finance task you want to improve. Second, identify the data and current process. Third, decide whether the task needs rules, analysis, or AI. Fourth, test with sample data and keep a human in the loop. Fifth, measure results in practical terms. Sixth, document limits and decide whether to expand, revise, or stop.
If you follow this sequence, you will already be using AI in finance more responsibly than many people who only know the buzzwords. You will understand what AI means in finance, recognize common use cases, distinguish data from rules from machine learning, read basic financial examples, and describe how AI supports forecasting and risk decisions while still having limits and risks. That is a strong beginner outcome.
Your next step is not to do everything. It is to do one thing well. Choose a narrow use case, stay cautious with high-stakes decisions, and keep building your judgment. In finance, that combination of curiosity, discipline, and practical thinking is far more valuable than hype.
1. According to the chapter, what is the best place for a beginner to start when using AI in finance?
2. What common mistake do many beginners make?
3. What does good judgment mean in a beginner AI roadmap?
4. Which of the following is a good way to measure the value of an AI use case in finance?
5. What principle should guide a beginner's roadmap when stakes are high?
- Learning Evolved.
- Intelligence Amplified.


