Machine Learning — Intermediate
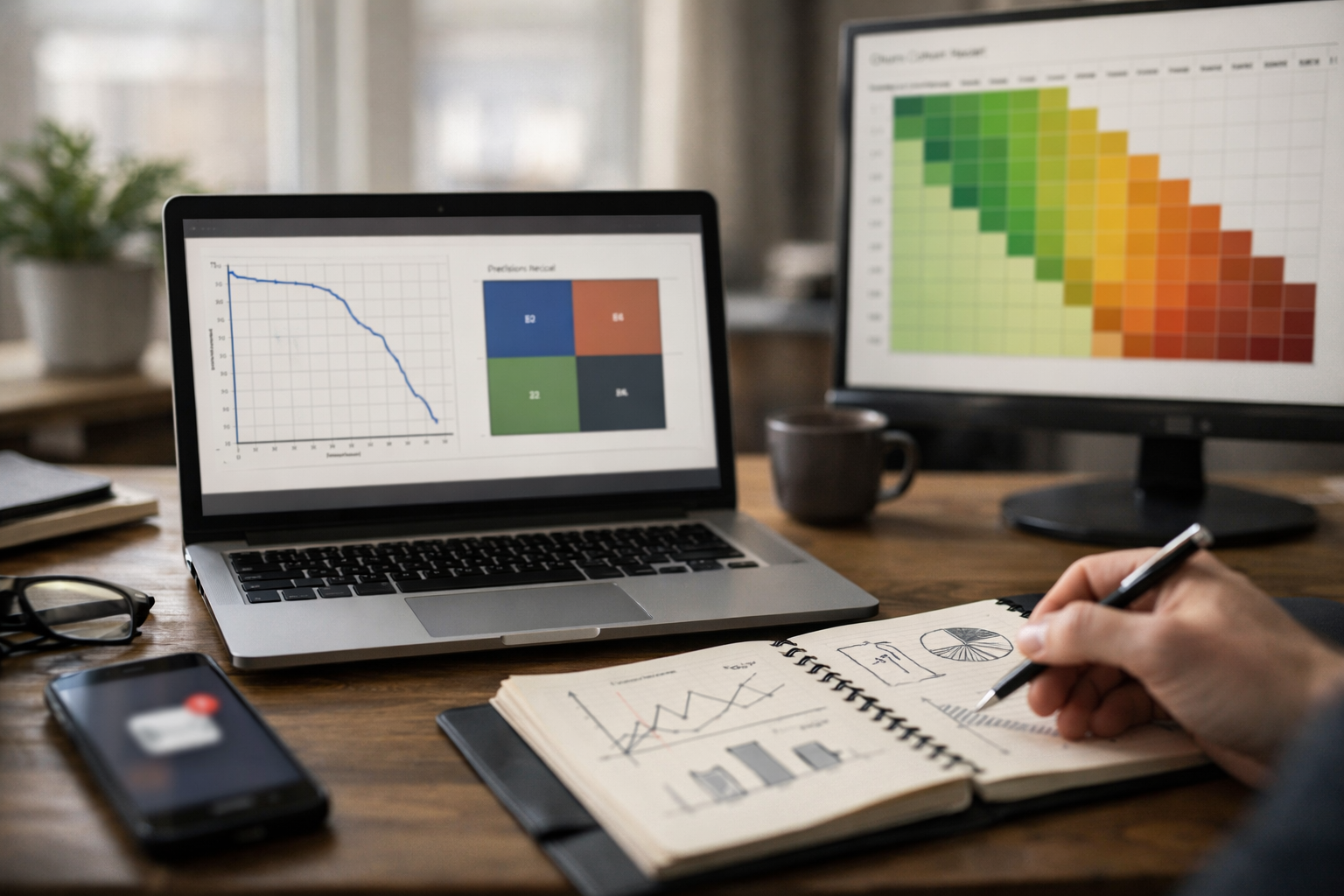
Ship fraud and churn models by tuning precision, recall, and thresholds.
Fraud detection and churn prediction share a problem that breaks many otherwise solid machine learning workflows: the positive class is rare, expensive, and operationally constrained. A model can post 99% accuracy and still miss most fraudulent transactions—or spam your retention team with false alarms. This course-book is a practical blueprint for building imbalanced classifiers that you can actually deploy, using precision-recall thinking and threshold tuning as first-class tools.
You’ll start by reframing the task from “train a classifier” to “make a decision under constraints.” Then you’ll progress through data/label design, strong baselines, correct evaluation with precision-recall metrics, rigorous threshold selection, probability calibration, and finally production monitoring that keeps your model effective as prevalence and behavior shift.
The heart of the course is learning to pick operating points intentionally. You’ll learn multiple thresholding strategies—target precision, target recall, maximize F-beta, minimize expected cost, and top-k queue selection—then validate that your chosen threshold is stable across segments and time windows. This is where many projects fail: teams compare models with the wrong metric, deploy a default 0.5 cutoff, and later discover their system can’t meet business SLAs. You’ll replace that guesswork with a repeatable process.
Fraud and churn teams often need probabilities that mean something: “This customer has a 23% chance to churn” or “This transaction has a 3% fraud risk.” In practice, many models produce scores that are good for ranking but poorly calibrated. You’ll learn how to diagnose miscalibration, apply Platt scaling or isotonic regression, and understand how calibration interacts with precision-recall evaluation and threshold choice—especially when prevalence changes.
Rare-event systems degrade quietly. Labels arrive late, investigators change behavior, product policies shift, and the base rate drifts—causing thresholds to decay. You’ll learn how to monitor what matters (including prevalence and alert volume), handle delayed ground truth, and run champion-challenger evaluations so improvements are measurable and safe. The end result is a playbook you can reuse for future imbalanced problems beyond fraud and churn.
Each chapter is structured like a short technical book chapter: concept → workflow → common pitfalls → decision checklist. You can follow it sequentially for maximum benefit, because each chapter builds the artifacts needed in the next (splits, metric suite, baselines, thresholds, calibration, and monitoring plan). When you’re ready to start, Register free. Or explore related topics in model evaluation and ML deployment by visiting browse all courses.
By the end, you’ll be able to take an imbalanced dataset, select the right evaluation lens, tune thresholds for real constraints, and ship a fraud or churn model with monitoring that keeps precision and recall aligned with business goals.
Senior Machine Learning Engineer, Risk & Retention Modeling
Sofia Chen builds and audits machine learning systems for fraud, credit risk, and subscription retention. She specializes in evaluation under class imbalance, probability calibration, and decision threshold optimization for real-world business constraints.
Imbalanced classification is not a “modeling trick” problem; it is a decision problem. Fraud detection and churn prediction both involve rare (or relatively rare) outcomes, but the real challenge is that the prediction is only useful if it triggers a concrete action at the right time, with acceptable cost and within operational capacity.
This chapter establishes the framing you will use throughout the course: define the decision you will take at prediction time, build a baseline that reveals why accuracy is misleading, translate errors into business costs, choose evaluation goals that match how the model will be used (often precision-recall first), and create a reproducible experiment template with correct splits.
By the end, you should be able to look at a dataset with 0.1%–5% positives and immediately ask: “What happens when the model says positive?” and “How will we judge success—across the whole population, or at the top of a ranked list?” That mindset is the foundation for threshold tuning, PR curves, recall@k, sampling strategies, and calibration later in the course.
Practice note for Define the decision: what action happens at prediction time: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build a first baseline and see why accuracy lies: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Map errors to business costs (false positives vs false negatives): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Set evaluation goals: PR metrics, top-k, and operating points: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a reproducible experiment template (data, splits, metrics): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Define the decision: what action happens at prediction time: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build a first baseline and see why accuracy lies: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Map errors to business costs (false positives vs false negatives): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Set evaluation goals: PR metrics, top-k, and operating points: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a reproducible experiment template (data, splits, metrics): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Fraud and churn are both imbalanced, but they behave differently in the real world. Fraud prevalence can be extremely low (often far below 1%), and labels may be delayed or disputed (chargebacks, investigations, manual review). Churn prevalence is frequently higher (2%–20% depending on the window), but “churn” is a definition you choose (30 days inactive? contract cancellation?), and the label can be noisy because customers may return later.
The most important practical distinction is the feedback loop. Fraud models often trigger hard interventions: block a transaction, step-up authentication, or send to manual review. Those actions change the data you will see next week—blocked fraud never becomes a confirmed chargeback, and reviews can bias labels toward what reviewers notice. Churn models also create feedback loops: retention offers change behavior, and outreach typically targets specific segments, which changes future churn rates in those segments.
Start by defining the decision at prediction time. Examples: “If a transaction is predicted fraud, route to manual review” (capacity-limited); “If an account is predicted high churn risk, send a retention offer” (budget-limited); “If risk is extreme, auto-block” (high false-positive cost). The decision defines the constraints you will optimize under, and it determines which metric matters most.
In short: prevalence differs, labels arrive differently, and interventions reshape data. Your evaluation plan must acknowledge those realities, starting with the decision and ending with metrics aligned to that decision.
The confusion matrix is the simplest tool for understanding imbalanced classification because it forces you to count what you actually did. With rare positives, tiny changes in false positives can dominate your workload, while tiny changes in false negatives can dominate your losses. You cannot reason about these tradeoffs from accuracy alone.
Define: true positives (TP), false positives (FP), true negatives (TN), false negatives (FN). In fraud, TP might be fraud correctly flagged; FP might be legitimate transactions incorrectly flagged (customer friction, lost revenue, review workload). In churn, TP might be churners correctly identified; FP might be customers contacted unnecessarily (marketing spend, brand damage). FN are often the most expensive: missed fraud loss; missed churn leading to lost lifetime value.
Under rare positives, the base rate means TN will be enormous, and even a “bad” model can look good in aggregate. For example, in 1,000,000 transactions with 0.2% fraud (2,000 fraud cases), a model that flags 10,000 transactions for review and catches 1,200 fraud yields: TP=1,200, FP=8,800, FN=800, TN=989,200. Those numbers immediately translate into operational questions: can you review 10,000? Is 12% precision acceptable? Is missing 800 fraud acceptable?
Engineering judgment shows up in how you compute this matrix. You must choose a decision threshold (or top-k rule) to convert scores into positives. The same model can produce many different confusion matrices depending on that threshold. This is why threshold tuning is not “post-processing”; it is part of the model’s behavior in production.
Keep the confusion matrix close. You will use it later to compute business cost, validate that a threshold meets capacity limits, and communicate impact to stakeholders in concrete terms.
Accuracy fails on imbalanced datasets because it rewards predicting the majority class. If fraud is 0.2%, a model that predicts “not fraud” for every transaction is 99.8% accurate—and completely useless. This is not a corner case; it is the default behavior when positives are rare.
Your first baseline should therefore be explicit and slightly “embarrassing” on purpose. Build at least two baselines: (1) the majority-class baseline that predicts all negatives, and (2) a simple model baseline (often logistic regression or a small tree model) with minimal features and sane preprocessing. The goal is not to win; the goal is to establish reference points and verify your pipeline, splits, and metrics.
When you run the majority-class baseline, record: accuracy, precision, recall, and the confusion matrix. You will see: accuracy is high, but recall is zero (TP=0). This exercise inoculates teams against shipping “99% accurate” models that never detect fraud or never identify churners.
Then build the simple model baseline and evaluate it with PR-first metrics (introduced in Section 1.5). Use the baseline to answer practical questions: do we have any signal at all? does the model rank positives near the top? does performance collapse on a time-based test set? A baseline that beats the majority class on recall and precision is already evidence that learning is possible.
Baselines are also reproducibility checks. If your baseline changes significantly across runs, your experiment template is not stable yet (random seeds, split logic, leakage). You will fix that in Section 1.6.
Once you can compute a confusion matrix at a chosen threshold, the next step is to translate it into business impact. This is where “false positives vs false negatives” stops being abstract and becomes a budgeting, risk, and operations discussion.
Assign costs (or utilities) to outcomes. For fraud: FN cost might be average fraud loss plus downstream handling costs; FP cost might be review cost plus customer friction (sometimes approximated as a small dollar amount or a conversion drop). For churn: FN cost might be lost margin or lifetime value; FP cost might be offer cost and contact fatigue. The exact numbers can be rough, but they must be directionally correct and agreed upon.
Capacity constraints create an additional axis. Many fraud systems have a limited number of manual reviews per day. Many churn systems have a limited outreach budget or call-center capacity. This means your decision rule may not be “predict positive if probability > 0.5”; it may be “review the top 2,000 highest-risk cases per day” or “contact the top 5% of accounts each week.” In those cases, your operating point is defined by k (or a quota), not by an arbitrary threshold.
Cost and capacity interact. If review capacity is fixed, improving ranking quality (more true fraud in the top-k) is often more valuable than improving global metrics. If auto-block is allowed, you may require extremely high precision and accept lower recall. The same model might support multiple actions: auto-block at a high threshold, manual review in a middle band, and allow otherwise.
Practical outcome: you should be able to write down an objective like “maximize prevented fraud dollars under 3,000 reviews/day and a maximum 1% false-decline rate,” or “maximize retained margin under a $50k/week offer budget.” That objective will guide threshold tuning later.
Metrics are not just reporting tools; they encode what you care about. For imbalanced classification, you will generally start with precision-recall (PR) metrics because they focus on performance on the positive class and the predicted-positive set—exactly where your operational burden and value usually live.
Precision answers: of the cases we flagged, how many were truly positive? This is tightly linked to analyst workload and customer friction. Recall answers: of all true positives, how many did we catch? This links to prevented fraud loss or retained customers. The tension between them is controlled by the threshold (or by k in top-k systems).
F1 combines precision and recall, but it implicitly weights them equally. Use F1 only if that tradeoff matches your business reality; otherwise it can push you toward an operating point you cannot afford (too many FPs) or that misses too much value (too many FNs).
PR-AUC (area under the precision-recall curve) summarizes ranking quality across thresholds. It is often more informative than ROC-AUC under heavy imbalance because ROC can look excellent even when precision is unusably low. PR-AUC still has caveats: it is sensitive to base rate, and it averages over thresholds you may never use. Treat it as a model-comparison tool, not as the final deployment criterion.
recall@k (or precision@k) matches capacity-limited workflows: if you can review k cases per day, recall@k tells you what fraction of all positives you capture in those k. This directly answers “If we only look at the top of the list, how good is the list?” For churn outreach capped at 10,000 customers/week, recall@10,000 is often more actionable than a single thresholded metric.
Your evaluation goal should end with an operating point: “At 80% precision, maximize recall,” or “At 2,000 reviews/day, maximize recall@k,” or “Minimize expected cost under a calibrated probability threshold.” That operating point becomes the anchor for threshold tuning.
Imbalanced problems are unusually sensitive to leakage and to bad splits. A small amount of leakage can create the illusion of strong precision and recall because positives are rare—so a few leaked positives can dramatically change metrics. Your experiment template must therefore be disciplined: reproducible splits, consistent preprocessing, and metrics computed on untouched data.
For many tabular problems, start with stratified train/validation/test splits so each split has a similar positive rate. This stabilizes metrics and prevents the test set from accidentally containing too few positives to evaluate. Set and record random seeds, and store the row identifiers for each split so you can reproduce results and audit changes.
However, fraud and churn often have time dynamics. Fraud patterns drift (new attack types), and churn behavior changes with seasonality, pricing, and product updates. In those cases, prefer a time-based split: train on earlier periods, validate on a later period for tuning, and test on the most recent holdout. This better approximates deployment and reduces optimistic estimates from “seeing the future.” If you use time splits, be careful with label windows (especially churn), ensuring features are computed only from information available before the prediction time.
Also handle grouping correctly. If multiple rows belong to the same customer or card, consider group splits so the same entity does not appear in both train and test. Otherwise the model can learn entity-specific patterns and appear to generalize when it is actually memorizing.
Practical outcome: you should maintain a small experiment template (data loading, split logic, pipeline, metrics report) that you can rerun exactly. That template becomes the backbone for later chapters: sampling strategies, class weights, threshold tuning, and probability calibration, all validated on splits that reflect how the model will be used.
1. In this chapter, why is imbalanced classification framed primarily as a decision problem rather than a “modeling trick” problem?
2. What is the main purpose of building a first baseline in an imbalanced fraud/churn setting?
3. When translating model mistakes into business impact, what distinction does the chapter highlight as essential?
4. If a model will be used to act on only a limited number of highest-risk cases, which evaluation goal best matches that usage?
5. What is the role of a reproducible experiment template according to the chapter?
In imbalanced classification, most model failures trace back to “ground truth” problems rather than algorithms. Fraud and churn are especially vulnerable because the label is not a physical measurement; it is a business definition with time windows, policy rules, and operational exceptions. If your positive class is even slightly misdefined, precision-recall analysis becomes misleading: you may celebrate a high PR-AUC while quietly optimizing for the wrong event. This chapter focuses on building labels and features you can defend, then creating validation splits that reflect how the model will be used.
The core workflow is: (1) define the positive class precisely and confirm label availability timing, (2) estimate prevalence and representativeness, (3) audit leakage risks and engineer only what is known at prediction time, (4) build features with clear time boundaries, (5) implement preprocessing and modeling in a single pipeline to prevent cross-split contamination, and (6) validate with split schemes that match rare-event deployment realities. Throughout, document assumptions so that when metrics move, you can explain whether it’s real improvement or a data artifact.
By the end of this chapter you should be able to state, in one sentence, what “fraud” or “churn” means in your dataset; show a timeline for when labels become known; list what is excluded due to censoring; and provide a reproducible split strategy that avoids leakage and preserves the operational distribution you expect at deployment.
Practice note for Audit labels and define the positive class precisely: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Engineer features safely (no leakage) for fraud and churn: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Handle missingness and categorical variables in a pipeline: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build a robust validation strategy for rare events: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Document assumptions and dataset limitations: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Audit labels and define the positive class precisely: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Engineer features safely (no leakage) for fraud and churn: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Handle missingness and categorical variables in a pipeline: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build a robust validation strategy for rare events: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Start by writing the label as an explicit rule with a timeline. For fraud, a common “positive” is a chargeback or confirmed fraud report tied to a transaction. But chargebacks arrive late, sometimes 30–120 days after authorization, and may be reversed. Your label must specify a chargeback window (e.g., “chargeback filed within 60 days of transaction date”) and whether reversals flip the label back to negative. If you train with a 60-day window but evaluate on a 120-day window, your model will look like it has poor recall when in reality you changed the definition of fraud.
For churn, define the horizon and observation window: “user churned if no activity for 30 consecutive days after the prediction date,” or “subscription canceled within 45 days.” Avoid mixing “voluntary cancellation” with “involuntary churn” (failed payment, account closure, compliance blocks) unless your intervention is the same. If the business action differs, treat them as separate labels or at least separate analysis slices.
Censoring is the silent label killer. If you label churn based on inactivity after day T, then users whose histories end before T+30 are censored—you cannot know whether they churned. Similarly, a transaction from last week cannot be labeled reliably with a 60-day chargeback window. Practical rule: define a “label availability date” and exclude examples whose label is not yet observable. If you keep them as negatives, you will inflate false negatives and punish models that correctly flag recent risky cases.
Operational outcome: produce a label dictionary that includes (a) event definition, (b) time window, (c) exclusions, (d) handling of reversals/disputes, and (e) the date when a label becomes final. Treat this document as a versioned artifact alongside your code.
Once labels are defined, measure prevalence (positives / total) in the population you care about and compare it to your training data. Fraud datasets are often filtered (only reviewed transactions, only certain countries, only high-value orders), and churn datasets may include only customers who survived onboarding. These filters change prevalence and, more importantly, the relationship between features and outcome. A model trained on “reviewed” cases may not generalize to the full stream because being reviewed is itself a selection mechanism.
Prior shift is when prevalence changes over time or across segments even if feature-to-outcome relationships are stable. In fraud, attacks evolve, payment mix changes, and policy changes can reduce observed chargebacks without reducing underlying fraud attempts. In churn, pricing updates, feature launches, and seasonality move the base rate. PR metrics are sensitive to prevalence: precision depends directly on how common the positive class is. If your validation set has 5% fraud but production has 0.5%, your offline precision will be optimistic even with the same model behavior.
Representativeness checks should be routine: compare feature distributions across time and key segments (region, channel, device, product tier). Also compare label pipelines: did definitions or backfills change? If you oversample positives for training convenience, keep a separate evaluation set with natural prevalence, or reweight metrics appropriately. Be explicit: “training uses downsampled negatives at 1:20; evaluation uses full distribution.”
Practical outcome: a short “data card” table listing prevalence by month and by key segments, plus notes on known shifts (policy changes, logging changes, product launches). This will later explain why threshold tuning and capacity planning need periodic revisits.
Leakage is any feature that encodes information not available at prediction time. In rare-event problems it often produces deceptively high PR-AUC, because the leaked signal is nearly deterministic for the few positives. Fraud and churn have recurring leakage patterns you should actively hunt for.
First, post-event features: anything recorded after the event timestamp—chargeback reason codes, “refund issued,” “account closed,” “support ticket tagged as fraud,” “collection started,” “retention offer sent,” or even “days since last login” computed using future activity. These features may exist in your warehouse and look harmless, but they bake the answer into the input.
Second, policy or process flags: “manual_reviewed,” “blocked_by_rules,” “sent_to_collections,” “VIP_whitelist,” “KYC_required.” These reflect decisions made by prior models or investigators. Training on them can cause a self-fulfilling loop: your model learns your process, not the underlying behavior, and may fail when rules change.
Third, future data via joins and aggregations. A classic mistake is computing customer-level aggregates over the full history, then using them to predict at earlier times. If the aggregate includes future transactions or future cancellations, you have leakage even if the feature name doesn’t sound time-based. The fix is to enforce “as-of” feature computation: for each prediction timestamp, only use data with event_time ≤ prediction_time.
Practical outcome: maintain a “prediction-time contract.” For each feature, store (a) source table, (b) event timestamp used, (c) aggregation window relative to prediction time, and (d) whether it is allowed. In code reviews, reject features that cannot pass a simple question: “Could we compute this at the moment we would score the customer/transaction?”
After securing labels and avoiding leakage, you can engineer features that are both predictive and operationally stable. In fraud and churn, behavior over time is often more informative than a single snapshot. The key is to anchor every feature to a clear “as-of” timestamp and use windows that reflect the business cycle.
For fraud transactions, strong patterns include velocity and inconsistency signals: number of attempts in the last 5 minutes/1 hour/24 hours by card, device, IP, email, or shipping address; ratio of successful to failed authorizations; change in billing/shipping addresses; and novelty indicators (first time seen device, first time seen merchant, first time seen BIN-country pair). Use multiple windows to capture both burst attacks and slow probing. Favor robust statistics (counts, unique counts, median amounts) over brittle rules.
For churn, focus on engagement trajectories: sessions per week over the last 4 weeks, recency (days since last key action), “streak” features (consecutive active weeks), and feature adoption (count of distinct product modules used). Aggregates can be enriched with trends: difference between last 7 days and prior 7 days, or a simple slope over weekly activity. Keep the feature set interpretable enough that you can later connect threshold decisions to actions (e.g., outreach for declining engagement vs. payment support for billing issues).
Missingness is not only a nuisance—it is often signal. A missing phone number or missing KYC field may correlate with fraud; missing engagement events may reflect logging issues or real inactivity. Treat missingness deliberately: add missing indicators, choose imputation strategies compatible with your model, and verify that missingness patterns are consistent across splits and time.
Practical outcome: a feature spec that lists each windowed feature with its time window and entity key, plus a small set of sanity checks (e.g., velocity counts nonnegative, trend features computed only when enough history exists).
To keep your experiments honest and reproducible, put preprocessing and the estimator into a single sklearn Pipeline. This prevents a common form of leakage: fitting imputers, scalers, encoders, or target transformations on the full dataset before splitting. In imbalanced settings, this error can materially inflate PR results because rare positives influence global statistics disproportionately.
A practical pattern is: ColumnTransformer for numeric and categorical branches, followed by a model that supports class weights or can be paired with sampling inside the training fold. For numeric features, use SimpleImputer (median) and optionally StandardScaler if the model is scale-sensitive (logistic regression, linear SVM). For categorical features, use SimpleImputer (most_frequent) plus OneHotEncoder(handle_unknown='ignore'). When categories are high-cardinality (merchant_id, device_id), consider frequency encoding or hashing, but implement it in a way that is fit only on training folds.
Keep the pipeline compatible with probability outputs, because later chapters will tune thresholds and calibrate probabilities. Many fraud/churn baselines start with LogisticRegression(class_weight='balanced') or GradientBoosting/HistGradientBoosting with appropriate regularization. If you use sampling methods (e.g., RandomUnderSampler, SMOTE), apply them only within the training split; the safest approach is to use imbalanced-learn pipelines that integrate sampling as a step that runs during fit, not before.
Practical outcome: a single object that you can cross-validate, serialize, and deploy consistently. Your training script should persist: dataset version, feature list, pipeline parameters, and the random seed for splits. This is the foundation for trustworthy PR comparisons and stable threshold tuning later.
Validation is where label definitions, leakage, and representativeness meet reality. Random splits are often wrong for fraud and churn because they allow future patterns to inform past predictions. Use a validation scheme that matches deployment: you will score new transactions or customers using only past data.
Time-based splits are the default for event data. Choose a cutoff date: train on months 1–4, validate on month 5, test on month 6. For more stable estimates, use rolling or expanding window cross-validation (multiple folds where each validation block is later in time than its training block). Always enforce a label gap when labels arrive late. For example, if fraud labels finalize after 60 days, do not validate on transactions from the last 60 days of the dataset; they are not fully labeled.
Group splits matter when multiple rows share an entity: many transactions per card/customer, many weeks per user. If the same customer appears in both train and validation, the model may memorize identity-correlated signals (even indirectly via device/location patterns). Use GroupKFold or GroupShuffleSplit keyed by customer_id (or card_id) when the prediction unit is an event but the behavior is entity-linked. For churn, grouping by user is often essential if you build multiple snapshots per user over time; otherwise you will train on earlier snapshots and validate on later snapshots of the same person, inflating performance.
Stratified CV is useful to keep rare positives present in each fold, but only apply it when it does not violate time or grouping constraints. In practice you may stratify within a time-based split (ensuring the validation month contains enough positives) rather than fully random stratification.
Practical outcome: a documented split policy stating (a) time boundaries, (b) group keys, (c) label availability gap, and (d) how you handle class imbalance in folds. This is the backbone that lets PR curves and recall@k comparisons later reflect genuine model quality instead of validation artifacts.
1. Why can precision-recall metrics (like PR-AUC) be misleading in fraud/churn modeling if the positive class is misdefined?
2. Which workflow step most directly prevents using information that would not be available at prediction time?
3. What is the main purpose of implementing preprocessing and modeling in a single pipeline?
4. Which validation approach best matches the chapter’s guidance for rare-event deployment realities?
5. Why does the chapter emphasize documenting assumptions and dataset limitations?
In imbalanced problems like fraud detection and churn prediction, “strong baseline” does not mean “complex model.” It means a model you can train repeatedly, evaluate correctly, and defend in front of stakeholders. This chapter focuses on building baselines that compete by design: reproducible splits, sane feature handling, careful weighting/resampling, and precision–recall (PR) evaluation that matches operational goals.
The workflow you want is consistent across use cases. First, lock a train/validation/test strategy that respects time and entities (customers/cards), because leakage can make any model look brilliant. Second, train two families of baselines: a linear model (logistic regression) and a tree-based model (single trees and boosting). Third, compare them using PR-first metrics (PR curves, PR-AUC, recall@k) and stable cross-validation, not accuracy. Fourth, consider resampling and class weighting as tools—used inside the training fold only—and measure the trade-offs. Finally, select a champion model with explicit reasoning and communicate it via a short model card that includes limitations, calibration/reliability, and an operating threshold aligned with business constraints.
By the end of this chapter you should be able to say, with evidence: “Here are two baselines trained reproducibly; here is how we compared them without misleading metrics; here is the chosen operating point given our review capacity or retention budget; and here is what the model is actually using to make decisions.”
Practice note for Train logistic regression and tree baselines with class weights: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Compare models using PR curves and stable cross-validation: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Try resampling responsibly and measure the trade-offs: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Select a champion model with explainable reasoning: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a model card summary for stakeholders: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Train logistic regression and tree baselines with class weights: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Compare models using PR curves and stable cross-validation: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Try resampling responsibly and measure the trade-offs: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Select a champion model with explainable reasoning: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Logistic regression remains one of the best first baselines for rare events because it is fast, stable, and interpretable. Under imbalance, the two main levers are (1) regularization and (2) class weights. Regularization (L2 by default) prevents coefficients from exploding when positives are scarce, especially with high-dimensional one-hot features (merchant IDs, device types, plan tiers). If you see wildly large coefficients or unstable validation PR-AUC across folds, increase regularization (smaller C in scikit-learn) and standardize numeric features. Keep preprocessing in a pipeline to avoid train/validation contamination.
Class weights change the loss so the model “cares” about positives. A common starting point is class_weight="balanced", which scales by inverse class frequency. In fraud, this often improves recall at a given precision because the model stops defaulting to “not fraud.” In churn, where the positive class can be larger but still minority, weights can help avoid models that only flag obvious churners and miss subtle cases.
Practical approach: train a baseline with a small hyperparameter grid over C (e.g., 0.01, 0.1, 1, 10) and compare PR curves, not accuracy. Keep the probability output (not hard labels) because you will tune thresholds later. Common mistakes include using the default 0.5 threshold (almost never appropriate), forgetting to stratify (or time-split) the data, and evaluating after resampling the entire dataset rather than inside training folds. Outcome: a reproducible, well-regularized weighted logistic model that sets a credible “floor” for performance and offers coefficient-based explanations you can sanity-check with domain experts.
Tree models are attractive under imbalance because they capture non-linear interactions (e.g., “new device” AND “high amount” AND “unusual country”), which linear models cannot represent without feature engineering. Start simple: a single decision tree is easy to explain but often unstable and prone to overfitting positives. The stronger baseline is usually a gradient-boosted tree model (e.g., XGBoost/LightGBM/CatBoost) with conservative depth and learning rate. These models optimize a differentiable loss (often logloss) and can incorporate class weighting via parameters like scale_pos_weight or sample weights.
It is important to understand what the model is optimizing versus what you care about operationally. Boosting minimizes average loss, not PR-AUC directly. You may see improvements in PR-AUC, but you should validate with PR curves and recall@k to ensure the gains show up at the top of the ranked list (where investigators or retention agents operate). For example, a churn model that improves PR-AUC but shifts lift away from the top 5% may be worse if you can only target a limited number of customers.
Engineering judgement: limit complexity first. Use early stopping on a validation fold, constrain depth (e.g., 3–8), and monitor variance across folds. If PR performance is volatile, it often means the model is fitting noise in rare positives or you have leakage via time, entity duplication, or post-event features. Outcome: a tree/boosting baseline that competes with logistic regression while remaining controllable, with clear training signals and comparable PR evaluation.
Class weighting and resampling are two ways to address the same issue: the learner sees far fewer positives than negatives. Class weighting keeps the dataset intact and changes the penalty for mistakes; resampling changes the training distribution by duplicating positives (over-sampling) or discarding negatives (under-sampling). In practice, class weighting is usually the safer first option because it preserves the true feature distribution and avoids creating artificial duplicates that can overfit.
When does resampling help? Under-sampling can help when the negative class is extremely large and redundant (millions of near-identical “normal” transactions), making training slow and memory-heavy. In fraud, under-sampling negatives can speed up experimentation dramatically; the key is to evaluate on the untouched validation/test distribution. Over-sampling can help linear models when positives are too few for the optimizer to find a stable boundary, but it increases the risk of memorizing repeated rare patterns—especially if you over-sample before splitting.
Rule of thumb: if you can train with weights and keep the full negative distribution, do that first. If compute or memory forces a choice, under-sample negatives within each training fold and keep the validation/test sets unchanged. Always measure the trade-off using PR curves and recall@k at the capacities you actually have. Outcome: a principled choice of weighting/resampling based on constraints (data size, speed, stability) rather than habit.
Resampling can silently invalidate your results if done incorrectly. The biggest pitfall is leakage: applying over-sampling (including SMOTE) before you split into train/validation/test. If synthetic or duplicated samples derived from an observation end up in both train and validation, PR-AUC can jump dramatically and then collapse in production. The correct pattern is: split first, then resample only the training portion (and in cross-validation, resample inside each training fold). Use pipelines so it is impossible to accidentally resample the full dataset.
SMOTE deserves special caution in fraud and churn. SMOTE creates synthetic positives by interpolating between positive examples. This assumes the feature space is continuous and that interpolation represents plausible cases. But many real-world features are categorical (merchant category, country, device type) or have “holes” (amounts, time gaps) where interpolation produces unrealistic samples. Synthetic points can distort the decision boundary and worsen calibration, even if PR-AUC looks better on paper.
Distribution shift is the other pitfall. Under-sampling negatives changes the prevalence in training; the model’s raw probabilities can become miscalibrated (predicting higher risk than reality). That may be fine if you only rank and then threshold using validation data, but it becomes dangerous if downstream systems interpret probabilities as true risk. Mitigation: calibrate probabilities after training (Platt scaling or isotonic) using an untouched validation set that matches deployment. Outcome: resampling used as a controlled experiment, with leakage-proof tooling and explicit checks for plausibility and calibration.
Under imbalance, evaluation must answer: “How many true positives can we capture at acceptable false positive rates given our capacity?” PR curves and PR-AUC are better aligned than ROC curves when positives are rare, but they can still be noisy. That is why stable cross-validation matters. Use stratified CV when time is not a factor; for fraud/churn with temporal drift, prefer time-based splits (e.g., rolling windows) and keep entities separated to avoid customer/card leakage.
When comparing models, don’t rely on a single PR-AUC number. Compute PR curves per fold, then summarize variability. A practical method is to interpolate precision at a grid of recall values and average across folds, reporting mean and standard deviation bands. You should also report point metrics that match operations: recall@k (for investigator queues), precision at fixed recall (for safety constraints), or precision@k (for limited outreach budgets). If your team cares about “top 1,000 cases per day,” evaluate recall@1000 on each fold and track variance.
Threshold tuning belongs here as well: choose thresholds on validation folds using business costs (false positives consume review time; false negatives lose money) and capacity limits. Then lock the threshold and evaluate once on the held-out test set. Common mistakes include choosing thresholds on the test set, averaging PR-AUC while ignoring fold instability, and comparing models at different operating points. Outcome: a champion model selected because it performs consistently where you will actually operate, not because it wins a single metric on a single split.
Picking a champion model is not only about PR curves; it is also about whether you can explain and safely act on predictions. For fraud, explanations help investigators trust the queue and reduce time-to-decision. For churn, explanations guide interventions (discount, education, outreach) and help avoid harmful targeting (e.g., offering incentives to customers who would not churn anyway). Start with what your baseline offers: logistic regression coefficients provide global directionality (“higher chargeback history increases risk”), while tree-based models can be interpreted with SHAP values for global and local explanations.
Practical interpretation workflow: (1) validate that top features are available at prediction time and not leaking post-event information; (2) examine global feature importance and compare with domain expectations; (3) inspect local explanations for a sample of high-score cases and a sample of false positives. In fraud, a common pattern is that device and velocity features dominate; if you see features like “chargeback_received” driving predictions, you likely have leakage. In churn, watch for features that encode the label indirectly (e.g., “account_closed_date”).
Close the loop with a lightweight model card for stakeholders. Include: intended use (fraud queue prioritization vs churn outreach), training data window and split method, primary metrics (PR-AUC, recall@k), chosen threshold and rationale (capacity/cost), calibration status (reliability plots, calibration method), top drivers (with caveats), and known limitations (segments with low coverage, drift risks). Outcome: a champion baseline that is not just accurate under PR metrics, but operationally defensible, explainable, and ready for threshold tuning and calibration before deployment.
1. In this chapter, what best defines a “strong baseline” for imbalanced classification?
2. Why must the train/validation/test strategy respect time and entities (e.g., customers/cards) in fraud/churn modeling?
3. When comparing baseline models under heavy class imbalance, which evaluation approach is most aligned with the chapter’s guidance?
4. How should resampling or class weighting be applied to avoid contaminating evaluation?
5. What is the most appropriate basis for selecting a champion model at the end of this chapter’s workflow?
Most imbalanced-classification models do not fail because the algorithm is weak; they fail because the decision rule is wrong. Your model outputs a score (often a probability-like number), but the business needs an action: block a transaction, send a case to review, trigger a retention offer, or do nothing. Chapter 4 turns model scores into operational decisions using precision-recall (PR) thinking. You will learn to choose thresholds that respect business costs and team capacity, compare models using PR-first metrics, and document an operating point that survives real-world variation (segments, time, and sampling drift).
Threshold tuning is not “pick 0.5.” In fraud, the positive class is rare and expensive, and false positives can harm customers. In churn, interventions cost money and attention, and your CRM team has a weekly outreach limit. In both cases, you need reproducible selection on a validation set, a clear narrative of trade-offs, and guardrails so the chosen operating point remains stable after deployment.
This chapter also emphasizes engineering judgment: how to decide between a single global threshold versus a top-k queue, when to optimize for expected cost versus meeting a target precision, and how to verify that a threshold you tuned last month still behaves similarly today. Finally, you will implement the full selection procedure in code, with clean separation between training, calibration, validation, and testing to avoid leakage.
Practice note for Turn scores into decisions: thresholds, top-k, and queues: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Optimize thresholds for cost, constraints, or target precision: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Evaluate threshold stability across segments and time: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Report operating points with clear trade-offs and narratives: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Implement threshold selection reproducibly in code: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Turn scores into decisions: thresholds, top-k, and queues: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Optimize thresholds for cost, constraints, or target precision: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Evaluate threshold stability across segments and time: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Report operating points with clear trade-offs and narratives: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Model outputs are usually continuous scores: a logistic regression probability, a gradient boosting “probability,” or a calibrated score. Operations requires a discrete decision rule. The simplest rule is a fixed threshold: predict positive if score ≥ t. This maps directly to precision (how many flagged are truly positive) and recall (how many true positives you catch). In imbalanced problems, this mapping is the core of performance—more than overall accuracy.
Many real systems do not act on every positive prediction. Instead, they create a triage queue. Fraud teams review a limited number of alerts per day; churn teams can only call so many customers per week. In that setting, you often use a top-k rule: sort by score and act on the highest k cases. This makes capacity explicit and avoids the illusion that a static threshold is “optimal” when workload fluctuates.
Practical workflow: define the action and the constraint first. Examples:
Common mistake: mixing the rule and the evaluation. If production uses top-k, you should not tune a fixed threshold on the validation set and hope it translates. Define the decision policy (threshold, top-k, or multi-tier actions), then evaluate using metrics aligned to that policy.
A PR curve plots precision vs recall as you sweep the threshold from high to low. It answers the question: “If I want more recall, how much precision will I sacrifice?” This is often more meaningful than ROC curves on imbalanced data because PR focuses on the positive class performance and reflects the base rate.
To pick an operating point, start by deciding what “good enough” means for your business. A fraud block rule might require precision ≥ 0.98; a churn outreach campaign might require recall ≥ 0.30 while keeping precision above the historical conversion rate by a certain multiple. On the PR curve, you are not looking for a single best point universally—you are locating the point that satisfies constraints and aligns with costs.
Engineering judgment matters when curves cross. Model A may dominate at high precision (useful for hard blocks) while Model B dominates at higher recall (useful for review queues). PR-AUC provides a summary, but it can hide these regime differences. In practice, you should report:
Common mistake: selecting the threshold on the test set because it “looks best.” Threshold choice must be made on the validation set (or via cross-validation), then locked before final test reporting. Another mistake is ignoring calibration: a threshold of 0.9 is meaningless if the score is not well-calibrated; PR curves remain valid for ranking, but a “probability threshold” is not comparable across models unless calibrated.
Once you know your goal, you can search thresholds systematically. Two practical objectives are (1) maximize an F-score variant and (2) minimize expected business cost. The F-score family balances precision and recall: F1 weights them equally; Fβ emphasizes recall when β>1 and precision when β<1. For fraud review, you might prefer F0.5 (precision-heavy). For churn outreach, you might prefer F2 (recall-heavy), especially when missing a churner is more costly than contacting a non-churner.
Expected-cost optimization is often closer to reality. Define costs for each outcome: cost(FP), cost(FN), and optionally benefits for TP (e.g., prevented fraud loss or retained revenue). Then compute expected cost across thresholds on the validation set and choose the threshold that minimizes it. This can incorporate capacity limits: if reviewers can only handle k cases/day, restrict candidate thresholds to those that produce ≤k alerts, or switch to a top-k policy.
Workflow for reproducible threshold search:
Common mistakes: (a) using class weights or resampling inconsistently between training and validation; (b) choosing t based on a metric that doesn’t reflect deployment constraints; (c) forgetting that changing prevalence (seasonality, new attack patterns) shifts precision at a fixed recall—so cost parameters and target precision should be revisited periodically.
When you have a fixed daily or weekly capacity, top-k evaluation is often the most honest way to compare models. Instead of “score ≥ t,” you take the k highest-scoring cases and compute how many are true positives. This yields precision@k (also called hit rate@k in some teams). If there are P total positives in the evaluation set, recall@k is (true positives in top k) / P.
These metrics connect directly to staffing and budgets: “If we can review 2,000 transactions/day, what fraction will be fraudulent, and what fraction of all fraud will we catch?” They also help when score calibration differs across models, because ranking quality is what matters for a queue.
Lift is another useful operational metric: lift@k = precision@k / base_rate. If your base fraud rate is 0.2% and precision@2000 is 4%, lift@2000 = 20×. That statement is intuitive for stakeholders: the queue is 20 times richer in fraud than random selection.
Practical reporting pattern:
Common mistake: comparing models at different k implicitly (e.g., one model generates more alerts at the chosen threshold). If the business constraint is k, then k is fixed and thresholds are whatever makes the queue size equal to k. This ensures apples-to-apples comparison.
A single global threshold can be suboptimal when score distributions and base rates differ by segment—regions, merchants, device types, customer tenure, acquisition channel, or product tier. For example, a new merchant might have a higher fraud base rate and noisier features; a long-tenured customer might be safer but more sensitive to false positives. Segment-aware thresholds can improve overall utility: you can maintain high precision in low-risk segments while gaining recall in high-risk segments.
The engineering challenge is to do this without creating unfair or unstable behavior. Segment thresholds can inadvertently encode protected characteristics (directly or via proxies), leading to disparate false positive rates or denial of service. Even when segments are legitimate (merchant category, tenure bands), you should evaluate fairness-relevant metrics by group: precision, recall, false positive rate, and alert volume share.
Practical guardrails:
Common mistake: creating “hidden” thresholds that change outcomes without documentation. Treat thresholds as part of the model artifact, version them, and include segment logic in the same reproducible pipeline as training and evaluation.
Thresholds are often brittle because precision and recall are estimates from finite samples. In imbalanced settings, the number of positives in validation can be small, so precision at a high threshold might be based on only a few predicted positives. You should quantify uncertainty before committing to an operating point, especially when it drives customer-facing actions.
Two practical tools are confidence intervals and sensitivity analysis. For confidence intervals, bootstrap the validation set (resample with replacement), recompute your metric at the chosen threshold (or your top-k policy), and report a 95% interval for precision, recall, and expected cost. If the interval is wide, you may need more validation data, a different operating regime (e.g., lower threshold with more volume), or to combine weeks/months for evaluation.
Sensitivity analysis asks: “If costs, capacity, or prevalence change, does our chosen threshold still make sense?” Try varying:
Finally, treat threshold selection as a reproducible, testable component in code. Store the selected threshold, the selection objective, the validation date range, segment rules, and the metrics/intervals used to justify it. This makes retraining and post-deployment monitoring straightforward: when performance drifts, you can tell whether the model ranking degraded, calibration shifted, or the operating point is no longer aligned with business reality.
1. Why do many imbalanced-classification projects fail even when the model’s scoring algorithm is strong?
2. Which operating approach best matches a situation where a fraud team can only review a fixed number of cases per day?
3. What is a valid reason to choose a threshold that targets a specific precision level rather than minimizing expected cost?
4. After selecting a threshold on validation data, what should you do to ensure it “survives” real-world variation?
5. Which practice best supports reproducible, leakage-resistant threshold selection?
In earlier chapters you used precision-recall (PR) metrics and threshold tuning to make imbalanced classification models useful for fraud and churn. That work assumes your model’s scores can be interpreted as “risk.” In practice, many classifiers output scores that rank examples well but do not correspond to true probabilities. A fraud score of 0.80 might not mean “8 out of 10 similar transactions are fraudulent.” If operations uses that number to size staffing, set alert policies, or communicate risk to customers, miscalibration becomes a production problem, not just a modeling detail.
This chapter focuses on making predicted probabilities trustworthy. You will learn how to detect miscalibration, why it happens (especially under sampling and class-weighting), and how to calibrate using Platt scaling or isotonic regression. You will also re-tune thresholds after calibration, because calibration changes the mapping from score to probability. Finally, you will validate calibration under dataset shift—particularly changes in base rates—and package the calibrated model so the same transformations occur in training and inference.
The core idea: ranking quality (PR-AUC, recall@k) and probability quality (calibration) are different. You often need both: good ranking to find rare positives, and good probability estimates to choose thresholds, allocate budgets, and explain risk in human terms. Treat calibration as part of the modeling pipeline, with its own validation, monitoring, and documentation.
Practice note for Detect miscalibration and understand why it happens: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Calibrate probabilities with Platt scaling or isotonic regression: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Re-tune thresholds after calibration and compare outcomes: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Validate calibration under dataset shift and class-prior changes: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Package the calibrated model for consistent inference: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Detect miscalibration and understand why it happens: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Calibrate probabilities with Platt scaling or isotonic regression: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Re-tune thresholds after calibration and compare outcomes: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Validate calibration under dataset shift and class-prior changes: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Calibration is about reliability: among all examples predicted at 0.30 risk, about 30% should be positive in the long run. This is different from discrimination (how well the model separates positives from negatives). A model can have excellent PR-AUC yet be poorly calibrated, especially when trained with class weights, aggressive regularization, or resampling that distorts the effective class prior.
Two concepts help you reason about trade-offs. Reliability measures whether probabilities match observed frequencies. Sharpness measures how concentrated predictions are away from the base rate (e.g., many predictions near 0 or 1). A perfectly reliable model that predicts everyone at the base rate is “calibrated” but useless. You want both: reliable probabilities that are also sharp enough to enable actionable decisions.
Decision quality is where calibration matters in day-to-day operations. In fraud triage, a calibrated probability can be multiplied by an estimated loss to compute expected value and prioritize reviews. In churn retention, calibrated uplift-like probabilities can guide offer allocation when budget is limited. If probabilities are systematically inflated, you will over-allocate resources and miss SLAs; if deflated, you will under-invest and lose revenue.
A useful mental model: PR metrics answer “who is riskier than whom?” Calibration answers “how risky is this case in absolute terms?” You will typically optimize ranking first, then calibrate probabilities, then re-tune thresholds on the calibrated outputs.
To detect miscalibration, start with a calibration curve (also called a reliability diagram). Bucket predictions into bins (e.g., 10 or 20), compute the mean predicted probability in each bin, and compare it to the observed positive rate. A well-calibrated model follows the diagonal. Systematic deviations tell a story: curves above the diagonal indicate under-confident predictions; below indicate over-confident predictions. In imbalanced problems, use enough data per bin—otherwise noise will masquerade as miscalibration.
Quantify calibration with proper scoring rules. The Brier score (mean squared error of probabilities) combines calibration and sharpness; lower is better. Log loss is even more sensitive to confident wrong predictions, which is often what hurts operations (e.g., auto-declining legitimate transactions with “99% fraud”). These metrics complement PR-AUC: PR-AUC measures ranking quality under class imbalance, but it does not penalize mis-scaled probabilities as long as ranking stays similar.
Use the right comparison logic in experiments:
Common mistakes include evaluating calibration on the training set (it will look better than reality) or using a test set multiple times while tuning calibration choices (silent overfitting). The safest workflow is: train model on train; fit calibrator on validation; report final PR metrics and calibration metrics once on test. If you must compare many calibrators, consider cross-validated calibration or a second holdout.
Practical outcome: you can say, with evidence, whether “0.7 means 70%” in the operating regime you care about, and you can detect when overconfidence would cause hard-to-debug spikes in false positives or false negatives.
The two most common post-hoc calibration methods are Platt scaling and isotonic regression. Platt scaling fits a logistic regression on top of your model’s raw scores, learning a smooth sigmoid mapping. It is stable with modest validation sizes and tends to work well when the miscalibration is roughly “S-shaped” (common with margin-based models and boosted trees). Isotonic regression fits a monotonic, piecewise-constant mapping; it is more flexible but can overfit when you don’t have many positives, which is typical in fraud.
In scikit-learn, prefer CalibratedClassifierCV so calibration is treated as part of the estimator API. Two patterns are practical:
cv="prefit" (or, in newer sklearn versions, fit the base estimator separately and pass it in).cv=5 so calibration uses out-of-fold predictions, reducing the risk of overfitting the calibrator.Example pipeline structure you should aim for: preprocessing (imputation/encoding) → base model (e.g., XGBoost/LightGBM via sklearn wrapper or LogisticRegression) → calibrator (sigmoid or isotonic). Calibrate on data that reflects the real inference distribution; if you used undersampling for training, calibration should be fit on an unsampled validation set with the real class ratio, otherwise probabilities will be biased.
Common mistakes and how to avoid them:
Practical outcome: you can export a single sklearn object that accepts raw features and outputs calibrated probabilities consistently, reducing training/serving skew.
Even a perfectly calibrated model can become miscalibrated when the base rate (prevalence) changes. This is common in fraud (seasonality, new attack patterns, rule changes) and churn (pricing changes, product shifts). If the relationship between features and label stays similar but the overall positive rate changes, you have a prior probability shift. In that case, you can often adjust probabilities without retraining the whole model.
A practical prevalence-aware recalibration uses odds adjustment. Let p be your model’s calibrated probability under the training/validation prior, and let π_old be the old prevalence while π_new is the new prevalence (estimated from recent labeled data, delayed but reliable). Convert to odds, adjust by the prior ratio, then convert back:
o = p / (1 - p)r = (π_new / (1-π_new)) / (π_old / (1-π_old))o' = o * rp' = o' / (1 + o')This adjustment assumes the likelihood ratios are stable and only the prior moved. It will not fix concept drift where fraud strategies change or churn drivers evolve. Still, it is extremely useful for maintaining “probability meaning” between retraining cycles.
Operationally, you need a process to estimate π_new. In fraud, labels may arrive with chargeback delays; in churn, the label horizon may be 30–90 days. Use the most recent fully matured window to compute prevalence, and record it with a timestamp. If you cannot get timely labels, you can monitor proxy signals (manual review confirmation rate) but treat them as noisy and do not over-correct.
Practical outcome: you can keep risk scores interpretable when the positive rate changes, which stabilizes thresholds, staffing plans, and KPI expectations across seasons.
Calibration changes the mapping between score and probability, so thresholds must be revisited. A common anti-pattern is “we calibrated probabilities but kept the same cutoff.” That cutoff was tuned on an uncalibrated scale and may no longer correspond to the intended precision, recall, cost, or capacity constraints.
Re-tune thresholds on the calibrated output using the same business framing from earlier chapters:
t to minimize expected cost per case, using calibrated p as the estimated probability of being positive.t such that the number of alerts per day matches review capacity; calibrated probabilities allow you to predict expected true positives among that workload.t to hit a minimum precision (to protect reviewers) or minimum recall (to limit losses), validated on the calibration/validation split.When comparing models, separate questions: (1) Which model ranks better? Use PR-AUC and recall@k on the same evaluation set. (2) Which model’s probabilities are more decision-useful? Use log loss/Brier and calibration curves. It is possible that model A has slightly better PR-AUC, but model B is far better calibrated, making it safer for automated actions (e.g., auto-decline above 0.95). In such cases, you might deploy A for human review ranking and B (or a more conservative threshold) for automation.
Common mistakes:
Practical outcome: after calibration you can choose thresholds that are stable, interpretable, and aligned with real-world costs—not just with an arbitrary score scale.
Calibration is only valuable if the organization trusts and uses the probabilities correctly. Your job is to translate “model math” into operational commitments. Start by defining what the probability means: “Among cases scored at 0.20, about 20% are fraud within our labeling definition.” Then state the scope: time window, geography, product line, and label maturity assumptions.
Give stakeholders two artifacts. First, a reliability plot (with confidence bands or at least bin counts) that shows where the model is well calibrated and where it is not (often at extreme probabilities due to limited data). Second, a decision table mapping thresholds to expected volume, precision, recall, and estimated net value. Operations teams care about workload and hit-rate; product teams care about customer impact and conversion loss; risk teams care about tail events and model governance.
From an engineering standpoint, package calibration as part of the same versioned artifact as the model, with metadata: training data date range, validation prevalence, calibration method, and threshold policy. Ensure your inference service outputs both the calibrated probability and the decision (flag/route), so audits can reconstruct why a case was acted on.
Practical outcome: teams can use calibrated risk scores to plan staffing, set guardrails, and explain decisions, while you maintain a clear path for recalibration when data shifts.
1. Why can a model be useful for fraud/churn ranking but still be a problem in production?
2. Which situation best illustrates miscalibration as described in the chapter?
3. According to the chapter, which training practices are highlighted as common reasons calibration can break?
4. After applying Platt scaling or isotonic regression, why must you re-tune decision thresholds?
5. What does the chapter recommend regarding validation and deployment of calibrated probabilities?
A precision-recall (PR) tuned model is only “good” at a point in time, under a particular prevalence, investigation workflow, and customer behavior. The day you deploy, you enter a new regime: labels arrive late, business teams change how they work cases, and the model itself changes the world by diverting traffic (fraud) or triggering retention offers (churn). This chapter focuses on how to keep PR performance alive after launch by designing feedback loops, monitoring the right signals, and maintaining thresholds without breaking capacity or trust.
In imbalanced problems, it is easy to fool yourself with “stable” accuracy while precision quietly collapses due to rising false positives, or recall decays because the model is no longer seeing the same types of cases. You need production-grade instrumentation: every score, every decision threshold, and every downstream outcome tied together with timestamps. You also need a plan for when to update thresholds, how to test challengers safely, and what governance artifacts are required to pass audit and stakeholder scrutiny.
Think of deployment as an extension of evaluation. Offline PR-AUC and recall@k tell you whether a model can rank cases, but production adds a constraint: you must decide which k you can actually investigate or intervene on each day. That makes alert volume and case handling capacity first-class metrics alongside precision and recall. The aim is not just a high PR curve, but a system that continues to produce actionable alerts and measurable business value.
The following sections provide a practical workflow: what goes wrong in production, how to monitor what matters, how to detect drift, how to maintain thresholds, how to experiment safely, and how to document decisions so the system can be operated over time.
Practice note for Design online/offline evaluation and feedback collection: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Monitor PR metrics, prevalence, and alert volumes in production: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Plan threshold updates and champion-challenger testing: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a lightweight governance checklist for risk models: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Deliver a final fraud/churn playbook template: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design online/offline evaluation and feedback collection: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Monitor PR metrics, prevalence, and alert volumes in production: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Production feedback is messy. In fraud, the “label” often arrives days or weeks later (chargebacks, confirmed disputes), and investigation outcomes may be inconsistent. In churn, the label may be “no longer active after 60 days,” which means you cannot immediately know whether today’s intervention prevented churn. If you ignore delay, you will compute misleading precision and recall and mistakenly “fix” a model that is working.
A common pitfall is treating investigation outcomes as ground truth without accounting for selection. Investigators typically review only the alerts you send them. That creates survivorship bias: you see labels for flagged cases, but you do not see what happened to unflagged cases. The result is artificially inflated precision (because reviewed items are enriched) and unknown recall (because you do not know how many bad cases you missed). The engineering response is to design explicit sampling and feedback. For example, reserve a small random sample of non-alerted transactions for post-hoc review or delayed label matching, and store the “would-have-alerted” scores for all events so you can later evaluate counterfactual thresholds.
Another pitfall is label contamination through operational shortcuts. If a manual reviewer uses model features or the model score as part of their decision, your label becomes partially model-derived. This can create circularity that boosts apparent performance and harms retraining. Mitigate by separating “model score used” and “independent evidence” fields, and by marking labels that were influenced by the model so they can be excluded or down-weighted in training.
Practical outcomes to build into your deployment design:
If you solve delayed labels and survivorship early, the rest of your monitoring becomes meaningful rather than performative.
You cannot wait for perfect labels to monitor PR health. Instead, you need a layered approach: (1) real-time leading indicators, (2) interim proxies, and (3) final PR metrics once labels mature. Start by monitoring alert volume and score distribution at the current threshold. Sudden shifts often indicate upstream data changes or a prevalence shift, even before labels arrive.
Precision proxying is about finding signals correlated with true positives that are available quickly. In fraud, proxies might include early customer complaints, velocity rule triggers, or negative authorization responses—imperfect, but useful as a smoke alarm. In churn, proxies may be “account downgrade,” “support tickets,” or “usage collapse.” Use these proxies as directional metrics, not as replacements for precision. Track their correlation with final labels over time; if that correlation breaks, your proxy is no longer trustworthy.
Recall estimation is harder under delay and selection. A pragmatic method is to estimate recall@k by combining: (a) flagged-case confirmed positives (as they arrive), (b) a random audit stream from non-flagged cases, and (c) delayed ground truth backfills (e.g., chargeback feeds). With the audit stream, you can estimate the base rate of positives in the unflagged population and approximate missed positives. This yields a recall estimate with confidence intervals, which is far more operationally useful than pretending recall is unknown.
Label delay requires time-windowed reporting. Always report metrics by event time and “label maturity.” For example, compute precision for events from 30–60 days ago if 90% of labels have arrived by then, and keep a separate dashboard for the most recent week showing only leading indicators. Mixing immature and mature periods is a classic mistake that makes every model look unstable.
The goal is to spot failures early without overreacting to delayed truth.
Drift is not one thing. Treating all drift as “retrain” leads to unnecessary churn and risky deployments. Distinguish three types and connect each to an action.
Covariate shift means the feature distribution changes while the relationship between features and label is mostly stable. Examples: a payment processor changes a field encoding; churn product usage patterns shift due to a UI redesign. Detect via distribution tests (PSI, KS) on key features and on the model score distribution. Action: verify feature pipelines, update preprocessing, and consider recalibration if probabilities are off but ranking remains good.
Prior shift (prevalence change) means the base rate of positives changes. Fraud rings can spike fraud rate; seasonal churn may increase. Prior shift will change precision at a fixed threshold even if ranking quality is unchanged. Action: adjust thresholds to maintain target precision or manage capacity, and monitor recall@k at a fixed capacity limit. This is where PR-first thinking pays off: you expect precision to move with prevalence and you plan threshold moves accordingly.
Concept drift means the relationship between features and label changes. Fraudsters adapt; retention offers alter customer behavior. Detect via declining PR-AUC on mature labels, unstable calibration curves, or rising false positives/negatives concentrated in new segments. Action: retrain with recent data, refresh features, and consider adding new signals. Concept drift is also where champion-challenger becomes essential, because “fixes” can easily regress performance in segments that still behave like before.
Knowing which drift you face determines whether you should recalibrate, move the threshold, retrain, or rollback.
Thresholds are operational levers. A model can remain a strong ranker while the “best” threshold changes with capacity, prevalence, and business costs. Treat threshold maintenance as a controlled process, not an ad hoc tweak after a bad week.
Start by defining a threshold policy tied to business constraints: a target precision floor (to protect customer experience), a minimum recall@k (to protect loss), and a daily capacity limit (cases/day). Your monitoring should tell you when the current threshold violates these constraints, with label-delay-aware logic. For example: “If projected alerts exceed capacity by 20% for 3 days, raise threshold one notch; if mature precision falls below 0.75 for two cohorts, raise threshold; if mature recall@capacity falls below target, lower threshold or retrain.”
Retraining cadence should match concept drift risk and label maturity. Fraud models may retrain weekly or monthly with partial labels plus backfilled outcomes; churn models might retrain monthly or quarterly. The mistake is retraining faster than labels mature, which amplifies noise and can encode operational artifacts. A practical compromise is two-stage training: a frequent “light” refresh for calibration/thresholding and a less frequent “full” retrain that changes features and model parameters.
A rollback strategy is mandatory. Keep the last known-good model and threshold pair (“champion”) deployable within minutes. Version everything: training data snapshot, feature schema, model artifact, calibration method, and threshold. If a deployment triggers alert floods, precision collapse, or severe segment regression, rollback should be procedural—not a hero moment.
The outcome is a stable operating envelope where threshold updates are predictable, auditable, and aligned to capacity.
Experimentation is how you improve without gambling production. In imbalanced settings, online tests must be designed around rare events and limited capacity. Start with shadow mode: run the challenger model in parallel, log its scores and “would-alert” decisions, but do not change operations. Shadow mode validates feature availability, latency, score distributions, and drift sensitivity before you risk customer impact.
For champion-challenger, decide what is allowed to vary: model, calibration, and/or threshold. If you change everything at once, you will not know what caused improvements or regressions. Use offline replay on recent traffic to estimate expected alert volume and recall@k under realistic capacity constraints. Then run an online A/B test where each arm controls a portion of traffic (or cases) with fixed capacity allocations. In fraud, you might split by transaction ID hash; in churn, by customer ID, ensuring no leakage across arms in downstream treatment.
Capacity planning is inseparable from PR tuning. If the challenger increases alerts by 30%, it may “improve recall” simply by sending more cases, while overwhelming investigators and degrading real precision due to rushed reviews. Therefore, online success criteria should include: mature precision, recall@fixed-capacity (or fixed budget), time-to-decision, backlog, and customer friction metrics (false positive cost). Consider a throttling mechanism: if alert volume exceeds a hard limit, the system automatically raises the threshold while logging the truncated tail for later evaluation.
Well-designed experiments prevent you from “winning” offline and losing operationally.
Fraud and churn models are risk models: they can deny transactions, trigger outreach, or change customer treatment. Governance does not need to be heavy, but it must be consistent. A lightweight checklist reduces operational risk and speeds up approvals because the same questions are answered every time.
Minimum documentation should include: the business objective (loss reduction, retention), the PR-first success metrics (precision, recall@k, PR-AUC), the chosen operating point (threshold and expected alert volume), and the costs/constraints used in threshold tuning. Add model lineage: data sources, training window, leakage controls, sampling/class weights, calibration method, and the evaluation protocol (train/validation/test split logic and time-based splitting). This closes the loop with the course outcomes: reproducibility and reliability are as important as a good curve.
Audit trails are operational artifacts: immutable logs of model version, threshold, feature schema, and decisions for each event. If a customer disputes an action, you must reconstruct what the system knew at decision time. Store feature snapshots or a reproducible feature hash keyed to an offline store. Record who approved changes and when. For regulated environments, document fairness and segment performance checks, especially where false positives have high human cost.
Stakeholder sign-off should be explicit and role-based. Typical signers: risk lead (fraud/churn owner), operations lead (investigation capacity), data science/ML owner (model validity), and compliance/legal (customer impact). Make sign-off conditional on meeting pre-defined guardrails and having a rollback plan tested.
Governance is what keeps PR performance alive when the team changes, the data shifts, and the business stakes rise.
1. Why can a PR-tuned model that looked strong offline degrade quickly after deployment?
2. What is a key risk in imbalanced production systems if you rely on “stable” accuracy as your primary health metric?
3. Which set of signals does the chapter describe as first-class metrics to monitor in production for a PR-thresholded system?
4. Why does the chapter argue that deployment should be treated as an extension of evaluation?
5. What combination best reflects the chapter’s recommended approach to changing thresholds and models safely in production?

- Learning Evolved.
- Intelligence Amplified.

