Machine Learning — Intermediate
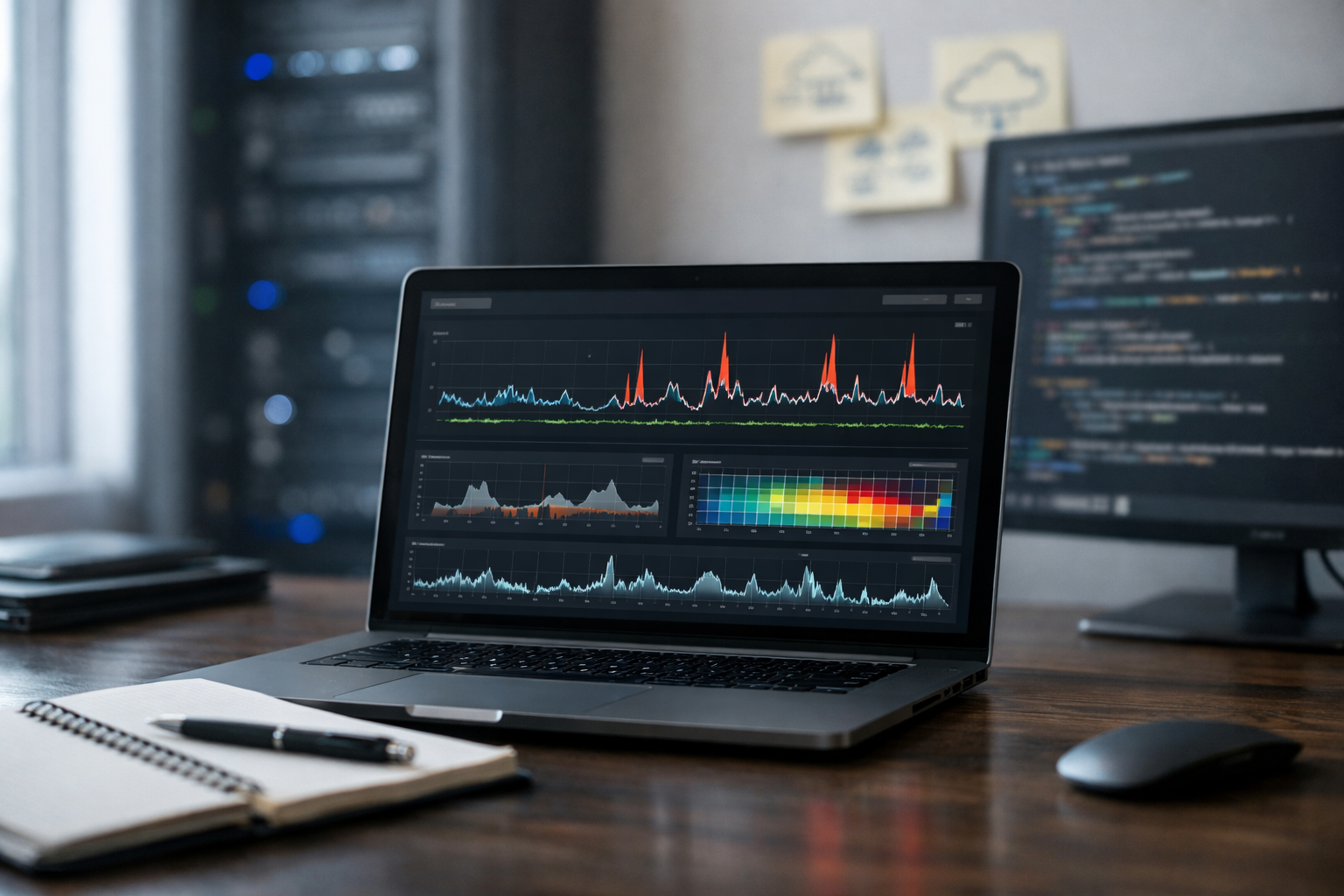
Ship ML with confidence using drift detection, checks, and actionable alerts.
Models don’t usually fail with a loud crash. They fail quietly: upstream data changes, a pipeline emits wrong types, a new customer segment arrives, or labels arrive late and performance drops for weeks before anyone notices. This course is a short, book-style blueprint for building production ML monitoring that catches problems early—using drift detection, data quality checks, and alerting that helps teams respond fast.
You’ll learn how to define what “healthy” means for an ML system, how to collect the right evidence at inference time, and how to turn statistical signals into operational decisions. The emphasis is not just on dashboards, but on workflows: what gets monitored, how alerts are tuned, who owns them, and what happens when something goes wrong.
Across six chapters, you’ll assemble a practical monitoring approach you can adapt to a batch scoring job or a real-time API. You’ll start with a monitoring spec (what to monitor and why), then add instrumentation and data collection, then implement drift and quality checks, and finally wire up alerting and incident response.
This course targets practitioners who can train models and want to operate them safely in production. If you work as an ML engineer, data scientist, data engineer, or platform engineer—and you’ve ever been surprised by a model regression—this curriculum is designed to give you a repeatable approach.
You don’t need a specific stack to benefit. The ideas transfer whether you’re using a warehouse-centric batch setup, a streaming feature pipeline, or a microservice-based inference API. The focus is on sound monitoring concepts, common statistical tools for drift, and operational practices that mature teams rely on.
Chapter 1 frames the problem: production failure modes and measurable service levels. Chapter 2 covers the foundation—instrumentation and data collection—because you can’t monitor what you don’t observe. Chapter 3 introduces drift detection methods and how to interpret them. Chapter 4 adds data quality checks that prevent silent breakages. Chapter 5 turns signals into alerting and dashboards that support triage without alert fatigue. Chapter 6 closes the loop with incident response, mitigations, and retraining triggers.
If you want to prevent regressions, detect drift early, and build alerting your team can trust, start here. Register free to begin, or browse all courses to compare related MLOps topics.
Senior Machine Learning Engineer (MLOps & Observability)
Sofia Chen is a Senior Machine Learning Engineer specializing in production ML reliability, monitoring, and incident response. She has built monitoring and alerting pipelines for real-time and batch models across fintech and e-commerce, focusing on drift, data quality, and measurable business impact.
Most machine learning projects do not fail because the model “isn’t accurate enough” in a notebook. They fail because production reality is messy: upstream data pipelines change without notice, users behave differently than training data suggested, systems degrade under load, and teams disagree about what “good” looks like. Monitoring is the discipline that turns these surprises into manageable, testable signals—so you can detect issues early, triage quickly, and decide whether to roll back, retrain, or accept the change.
This chapter builds the foundation for a production monitoring strategy. You will map failure modes across data, model, system, and human process; decide what to monitor (inputs, outputs, performance, and business impact); choose monitoring windows (real-time, batch, and delayed labels); draft a minimal monitoring spec for a single endpoint; and assign roles so alerts actually lead to action. The goal is not “more dashboards”—it is an operational contract between an ML system and the business it serves.
Monitoring is also a cost-control tool. Logging everything at full fidelity is expensive; investigating every anomaly is distracting. Effective monitoring aligns with risk tiers: what can break, how badly, how fast, and at what business cost. From that, you define which signals are necessary and sufficient to protect key outcomes without drowning teams in noise.
Practice note for Map failure modes: data, model, system, and human process: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Define what to monitor: inputs, outputs, performance, and business impact: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Choose monitoring windows: real-time vs batch vs delayed labels: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a minimal monitoring spec for a single model endpoint: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Set roles and ownership: who responds to which alerts: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Map failure modes: data, model, system, and human process: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Define what to monitor: inputs, outputs, performance, and business impact: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Choose monitoring windows: real-time vs batch vs delayed labels: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a minimal monitoring spec for a single model endpoint: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Start monitoring design by asking: “What are we trying to protect?” In production ML, there are typically four goals: (1) protect user experience (latency, availability, correctness), (2) protect business KPIs (conversion, revenue, fraud loss, churn), (3) protect compliance and safety (fairness, privacy, regulated decisions), and (4) protect engineering velocity (fast diagnosis, safe releases). A monitoring strategy should explicitly tie signals to at least one of these goals; otherwise you will collect data that no one acts on.
Next, model monitoring has real costs: storage for logs, compute for aggregation and drift tests, on-call time, and opportunity cost of attention. The practical way to balance this is to define risk tiers. For example: Tier 0 (safety/regulated) requires strict alerting, audit trails, and low tolerance for silent failure; Tier 1 (revenue-critical) demands fast detection and rollback; Tier 2 (product quality) can tolerate slower, batch-based monitoring; Tier 3 (experimentation) may only need lightweight checks and periodic review.
A common mistake is to monitor “accuracy” because it is familiar, even when labels arrive weeks later. Another is to set alert thresholds without baselines or seasonality, producing constant false positives. The outcome of this section should be a short, written monitoring charter: the model’s risk tier, the KPIs it affects, the acceptable operational cost, and the maximum time you can tolerate a silent failure.
Production ML is a lifecycle, not a one-time deployment. The key difference from traditional software is that model behavior depends on data distributions that evolve, and on feedback loops created by the model’s own decisions. Once a recommender starts shaping what users see, it changes user behavior; once a fraud model blocks transactions, it changes the composition of “observed fraud.” Monitoring must therefore cover both the pipeline that feeds the model and the downstream consequences of its predictions.
A practical lifecycle view has these stages: data collection → feature generation → training → evaluation → deployment → inference → outcomes/labels → retraining. Failures can occur at any stage, and monitoring should put “sensors” at critical boundaries: ingestion freshness, feature computation correctness, inference stability, and business outcomes. This is where you decide what to monitor: inputs (raw and features), outputs (predictions, scores, top-K lists), performance (latency, errors), and impact (KPI movements).
Feedback loops complicate interpretation. If the model changes the data you later train on, a metric shift might be expected rather than alarming. The engineering judgment is to separate system health signals (e.g., missing features, increased error rates) from behavioral signals (e.g., distribution shifts) and from outcome signals (e.g., conversion). For each, define the expected directionality during a rollout or seasonal period.
Finally, acknowledge label delay. Many systems cannot compute true performance in real time. You may need proxy metrics (calibration drift, score distribution shifts) and delayed “ground truth” monitoring. A strong practical outcome is a diagram showing where labels enter the system, the typical delay, and which checks run in real time versus overnight batch.
To prevent failures, first map them. A useful taxonomy is: data failures, model failures, system failures, and human process failures. Data failures include schema changes, null spikes, range violations, duplicate events, late-arriving data, broken joins, and feature leakage. Model failures include concept drift (the relationship between inputs and labels changes), poor calibration, bias regressions, and out-of-domain inputs that produce overconfident scores. System failures include timeouts, resource saturation, dependency outages, and partial deploys. Human process failures include undocumented assumptions, missing ownership, unreviewed changes to upstream pipelines, and alert fatigue leading to ignored pages.
Monitoring is strongest when it focuses on leading indicators—signals that appear before the business KPI collapses. Examples: a sudden rise in missing critical features, a shift in categorical value frequencies (new country codes, new device types), a drop in input freshness, or a score distribution that becomes bimodal after a feature pipeline bug. These are often detectable without labels.
A common mistake is to detect drift but not connect it to action. Drift is not automatically bad; it is a prompt to investigate. Your monitoring should classify drift into: expected (seasonality, new product launch), acceptable (no KPI impact), or critical (correlated with errors or KPI drop). The practical outcome is a failure-mode map that lists: what can break, the first observable symptom, and the fastest mitigation (rollback, hotfix, disable feature, route to fallback model, or throttle traffic).
Monitoring requires observability: the ability to answer “what happened, where, and why?” using three primitives—logs, metrics, and traces. Use them together. Metrics tell you that something changed (spike in nulls, latency regression). Logs tell you what inputs and outputs were involved (specific feature values, model version, request context). Traces tell you where time was spent across services (feature store call, model server, downstream API), enabling root-cause analysis.
For a minimal monitoring spec for a single model endpoint, define what you will log per inference. At minimum: timestamp, model name/version, request ID, hashed entity/user ID (privacy-aware), feature vector summary (not always raw values), prediction (score/class), decision (e.g., allow/deny), and any missing-feature indicators. Add operational context: latency, HTTP status, and upstream dependency status. For high-volume systems, sample logs but keep full-fidelity metrics.
Engineering judgment matters in privacy and cost. Avoid logging raw sensitive fields; log derived features or hashed identifiers. Use feature-store “contracts” to record schema versions, so you can pinpoint when an upstream change occurred. A common mistake is to log too little (no model version, no feature pipeline version), making incident response impossible. Another is to log too much without retention rules, creating runaway cost and risk. The outcome of this section should be a concrete endpoint spec: the event schema, sampling strategy, and retention policy.
Monitoring windows should match how quickly you need to detect and respond. Real-time monitoring (seconds to minutes) is ideal for system health and severe data quality issues: latency, error rates, missing critical features, and sudden distribution shifts. Batch monitoring (hourly/daily) suits deeper data validation and drift analysis that needs aggregation. Delayed-label monitoring (days/weeks) is necessary for true performance metrics like accuracy, AUC, precision/recall, or business outcomes like chargebacks and churn.
In practice you will mix patterns. A common architecture is: (1) inference service emits logs/metrics; (2) metrics go to a time-series system for near-real-time alerts; (3) logs land in a data lake/warehouse for batch analysis; (4) a monitoring job computes drift and quality checks on sliding windows; (5) labels are joined later to compute ground-truth performance. The critical design decision is to ensure you can join inference events to outcomes via stable keys and timestamps.
Common mistakes include choosing only one window (e.g., only daily jobs) and discovering incidents too late, or using only real-time proxies and never validating with ground truth. Another is failing to account for seasonality: weekends, holidays, marketing campaigns. The practical outcome is a monitoring schedule: which checks run continuously, hourly, daily, and “when labels arrive,” plus the data dependencies for each.
SLIs (Service Level Indicators) are measurable signals of system behavior; SLOs (Service Level Objectives) are target thresholds over time. For ML systems, define SLIs across four layers: system reliability (availability, latency), data quality (freshness, completeness), model behavior (prediction distribution stability, drift statistics), and outcomes (accuracy and business KPIs when labels are available). The purpose of SLOs is not to “prove the model is good”; it is to create an operational boundary that triggers action and clarifies trade-offs.
Set SLOs using baselines and error budgets. For example, an endpoint might have: p95 latency < 120 ms over 5-minute windows; error rate < 0.5% daily; feature freshness lag < 15 minutes for 99% of events; critical-feature null rate < 0.1% hourly; and prediction distribution PSI < 0.2 daily (with investigation required, not automatic rollback). For delayed labels, you might set: precision at top-K > X over a weekly cohort, with segmentation by region/device to prevent hidden regressions.
Common mistakes are setting SLOs without a response plan (no one owns the page), or setting them so tightly that they page constantly, causing alert fatigue. A practical outcome is a one-page monitoring spec: SLIs, SLO thresholds, window definitions (real-time vs batch vs delayed labels), and an ownership matrix. If you can’t name the responder and the mitigation for an alert, it’s not an alert—it’s a chart.
1. According to Chapter 1, why do many ML projects fail in production even if the model performs well in a notebook?
2. Which set best describes what a monitoring strategy should cover for an ML system?
3. How does the chapter characterize effective monitoring compared to simply adding more dashboards?
4. What is the main purpose of choosing monitoring windows such as real-time, batch, and delayed labels?
5. How does Chapter 1 suggest balancing monitoring coverage with cost and team attention?
Monitoring starts long before you compute a drift test or draw a dashboard. If you cannot reliably capture what the model saw, what it produced, and the business context around that decision, every downstream metric becomes guesswork. This chapter is about the “wiring”: designing inference events that are audit-friendly, logging features without leaking privacy or blowing up storage, attaching model metadata so you can compare apples to apples, and building a pipeline that turns raw events into trustworthy aggregates. The goal is a monitoring foundation that is aligned to risk and cost: high-fidelity where mistakes are expensive, and lightweight where the impact is low.
A practical monitoring data system usually has two paths. First is the real-time path that supports rapid detection (latency spikes, missing features, sudden distribution shifts). Second is the analytical path that supports correctness, accountability, and long-horizon trends (drift over weeks, cohort performance, bias checks, and post-incident forensics). The tension is constant: more detail improves debugging and audits, but increases cardinality, retention risk, and cost. Engineering judgement is choosing what to log by default, what to sample, and what to keep only on-demand.
Throughout the chapter, keep one principle in mind: monitoring data should be reconstructable. If you can’t reconcile aggregates back to raw events, you’ll never fully trust an alert. That means stable identifiers, explicit timestamps, and consistent versioning for the model and data inputs. You’ll also need a plan for delayed labels—because most models do not receive ground truth instantly—and a way to backfill historical labels into your monitoring store without corrupting metrics.
Practice note for Design an inference event schema for monitoring and audits: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Implement feature logging without leaking PII or exploding costs: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Capture model metadata: versions, signatures, and training context: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build a metrics pipeline from raw events to aggregates: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Validate end-to-end: sampling, backfills, and reconciliation: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design an inference event schema for monitoring and audits: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Implement feature logging without leaking PII or exploding costs: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Capture model metadata: versions, signatures, and training context: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
An inference event schema is the backbone of monitoring and audits. Treat it as a product interface: version it, document it, and keep it stable. At minimum, each inference record should include (1) identifiers that let you join to upstream context and downstream outcomes, (2) timing fields for latency and freshness, (3) the model output, and (4) enough input context to detect drift and data quality issues.
A practical baseline schema includes: event_id (unique), request_id (from the serving layer), entity_id (user/device/account), event_time (when inference happened), ingest_time (when logged), model_id/model_version, prediction (score/class), prediction_timestamp, decision (if you apply a threshold), feature_vector_ref (pointer to stored features or hash), feature_snapshot (optional, selected features), and latency_ms broken down into fetch/model/postprocess. If you need compliance, include purpose (why decision was made) and policy_version (which business rule was applied).
What to avoid: logging raw payloads “just in case,” especially free-text, images, or full JSON requests. These explode costs and often contain PII. Another common mistake is logging only the final decision (approve/deny) but not the underlying score and threshold; you lose the ability to evaluate alternate thresholds, detect score drift, or explain changes in approval rates. Also avoid high-cardinality tags embedded as metric labels (like request_id in metrics); keep those in logs/traces instead.
Practical outcome: you should be able to answer, for any alert, “which model version produced this?”, “what inputs changed?”, “was the change real or logging noise?”, and “which business cohort was affected?” A well-designed event schema makes those questions a straightforward query, not a forensic project.
Production monitoring usually touches three data systems that are easy to confuse. A feature store is optimized for producing consistent features for training and serving (often with offline and online components). An inference store (or prediction log store) is optimized for capturing what happened at decision time: features used, prediction made, and metadata required for audits and evaluation. A warehouse/lake is optimized for analytics, joins, and long-term retention.
For monitoring, the key is reproducibility. The feature store gives you canonical feature definitions and point-in-time correctness; it does not automatically guarantee you logged the exact values used at inference. If features are computed online with volatile sources, you can get “training-serving skew” in reverse during analysis: the warehouse recomputation won’t match what the model actually saw. This is why many teams log either (a) a minimal feature snapshot (top drivers, derived buckets, missingness indicators), or (b) a feature hash plus a pointer to a feature snapshot store keyed by (entity_id, event_time, feature_set_version).
Use an inference store when you need tight access control, lower-latency retrieval for recent events, and immutable append-only semantics (useful for audits). Use the warehouse for aggregates, dashboards, cohort analysis, and label joins. A common workflow is: serving logs → streaming/batch ingestion → raw inference table (append-only) → curated monitoring tables (validated schema, deduped) → aggregates (hourly/daily) powering alerts and dashboards.
Practical outcome: choose one “source of truth” for inference events (often the inference store or raw warehouse table), then build curated views. Do not build monitoring directly from ad-hoc application logs; you will eventually change a log line and silently break historical continuity.
Most monitoring value comes from comparing predictions to outcomes, but outcomes are often delayed, sparse, or noisy. A payments fraud model might get labels within minutes (chargeback signals can still be delayed), while a churn model might take weeks. Your monitoring design must treat labels as a second event stream that arrives later and must be joined carefully.
Start by defining a labeling contract: what is the ground truth definition, what timestamp defines “truth time” (transaction time vs settlement time), and what is the acceptable delay. Then implement a label event schema with: label_event_id, entity_id, outcome (label value), outcome_time, observation_window (e.g., “7d after inference”), and source_system (CRM, payment processor, human review). Use the inference event’s event_id or a deterministic join key (entity_id + inference_time rounded + context_id) to avoid ambiguous matches.
Delayed truth introduces two practical strategies. First, compute “proxy metrics” immediately (prediction distribution, decision rate, missing features, latency) and reserve performance metrics (AUC, precision/recall, calibration) for when labels mature. Second, use backfill jobs: periodically re-join recent inference events with newly arrived labels to update evaluation tables. This is where reconciliation matters—your pipeline should be idempotent, and you should track label freshness (what fraction of last week’s inferences have labels yet).
Common mistakes include mixing partial labels into headline performance metrics (creating misleading trends), failing to version label definitions (a rule change looks like concept drift), and not accounting for selection bias (only flagged cases get reviewed). Practical outcome: your dashboards should clearly separate “real-time health” from “matured performance,” with explicit label delay windows.
Instrumentation is also a privacy design exercise. Monitoring data frequently contains identifiers and sensitive attributes; if mishandled, it becomes a liability that blocks analysis or violates regulations. The safest approach is “log for monitoring, not for curiosity”: capture the minimum needed to compute drift, quality, and performance metrics, and prefer derived signals over raw sensitive values.
Apply a few concrete controls. Data minimization: do not log raw names, emails, addresses, free-form text, or full device fingerprints. If you need joins, store a stable pseudonymous key (e.g., salted hash of user_id) and keep the salt in a secure vault. Field-level classification: tag columns as PII, quasi-identifiers, or non-sensitive, and enforce different access policies. Tokenization/redaction: if a feature is sensitive but necessary for fairness audits, store a bucketed or clipped version (age_band instead of exact age) and ensure the transformation is consistent across training and monitoring.
Retention should be explicit and automated. Define retention by risk: raw inference logs might be 30–90 days, curated aggregates 13 months, and audit trails longer if required by policy. Implement TTL in storage, not a manual cleanup script. Also plan for deletion requests: if regulations require “right to be forgotten,” design your tables so you can delete or render inaccessible records by user key without breaking aggregate integrity (often by recomputing aggregates or storing aggregates that cannot be reverse-engineered).
Common mistake: collecting “just enough PII to debug,” then copying it into multiple systems (logs, warehouse, dashboards). Practical outcome: a monitoring pipeline that security and legal teams can approve quickly, enabling broader access to non-sensitive aggregates and faster incident response.
Raw inference events are too granular for most alerting. Monitoring systems need aggregates: per-minute latency percentiles, per-hour prediction histograms, per-day feature missingness rates, and segmented metrics by key cohorts. The challenge is controlling cardinality (the number of unique dimension combinations) so costs and query performance remain predictable.
Design your metrics pipeline in layers. First, validate and dedupe raw events (schema checks, required fields, uniqueness on event_id). Second, build intermediate rollups at a fixed grain (e.g., 5-minute windows, by model_version and major product surface). Third, compute derived metrics (drift statistics, SLO burn rates, conversion rates) from those rollups. Keep each layer re-runnable and deterministic; it makes backfills and incident analysis far easier.
Common mistake: creating a dashboard with dozens of breakdowns and then emitting them as metric labels; your monitoring bill and system stability will suffer. Practical outcome: you can maintain real-time alerting on compact aggregates, while keeping enough raw data (with TTL) for drill-down and reconciliation.
Monitoring comparisons only make sense when you know what changed. Every inference should carry enough metadata to tie it to a specific model artifact and the context in which it ran. At minimum, log model name, semantic version (or immutable artifact hash), signature (expected inputs/outputs), and runtime environment (container image, library versions). This makes it possible to distinguish “model drift” from “we deployed a new preprocessing step.”
Versioning must extend beyond the model. Include feature set version (the set of feature definitions used), preprocessing config version (imputation rules, encoders, scaling), and threshold/policy version (business decision logic). If you run A/B tests or shadow deployments, log experiment_id and treatment so you can segment monitoring and avoid mixing distributions.
Capture training context for audits and root-cause analysis: training data window, label definition version, and key hyperparameters. You don’t need all of this in every inference row, but you do need a reliable join: inference event → model_version → model registry metadata. A common pattern is to log only immutable identifiers at inference time and look up the rest in a registry table.
Finally, validate end-to-end with reconciliation. Run periodic checks that counts match between the serving system and the inference store, that sampling rates are respected, and that backfills produce identical aggregates when re-run. Common mistake: treating version fields as free-text; enforce enums or registry-validated values. Practical outcome: when a metric shifts, you can quickly correlate it to a specific deployment, feature change, or config rollout—and respond with confidence.
1. Why does monitoring need to start at instrumentation and data collection rather than at drift tests or dashboards?
2. What is the primary trade-off described when deciding how much inference detail to log?
3. Which pair best matches the two monitoring data paths and their purposes?
4. What does it mean for monitoring data to be "reconstructable," and why does it matter?
5. What instrumentation practices are highlighted as necessary to support reconciliation and reliable backfills (including delayed labels)?
Drift monitoring becomes useful when it reliably answers two operational questions: “Is something changing?” and “Do we need to do anything about it?” In production, you will see many kinds of change—marketing campaigns, new device releases, upstream schema tweaks, seasonal traffic, or a model rollout that shifts who gets scored. This chapter focuses on practical drift detection: selecting metrics appropriate to your feature types, running univariate tests without overreacting to p-values, adding multivariate and embedding-based signals, and handling seasonality and segmentation so you can produce a drift report that guides action (not just a busy dashboard).
A workable workflow is: (1) choose a reference distribution (training, last good month, or a curated “golden” window), (2) choose a comparison window (rolling daily/weekly), (3) compute drift metrics per feature and per important segment, (4) aggregate into a severity score that accounts for feature importance and business risk, and (5) attach recommended actions (investigate pipeline, retrain, adjust thresholds, or ignore as expected seasonality). Engineering judgment matters throughout: drift is often real but harmless; sometimes drift is small but critical (e.g., in a high-stakes segment).
Common mistakes include: using a single drift metric for every feature type, interpreting statistical significance as business impact, ignoring segment-level shifts, and alerting directly on raw p-values. You will avoid these mistakes by matching tests to data types, separating statistical from practical drift, and setting action thresholds that reflect risk and cost.
Practice note for Select drift metrics by feature type (numeric, categorical, text): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Run univariate drift tests and interpret statistical vs practical drift: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Add multivariate drift signals and embedding-based monitoring: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Handle seasonality and segment-based drift (cohorts, regions, devices): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create a drift report that guides action, not just dashboards: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Select drift metrics by feature type (numeric, categorical, text): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Run univariate drift tests and interpret statistical vs practical drift: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Add multivariate drift signals and embedding-based monitoring: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Handle seasonality and segment-based drift (cohorts, regions, devices): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Start by naming the type of change you’re monitoring, because each implies a different detection method and response. Data drift means the input distribution changes: P(X) shifts. Examples: a new app version changes how a field is populated, a new market expands to a different customer mix, or an upstream service starts defaulting missing values to 0. Data drift is observable immediately at inference time, which makes it the first line of defense.
Concept drift means the relationship between inputs and outcome changes: P(Y|X) shifts. This often comes from changes in user behavior, product policies, pricing, or fraud tactics. Concept drift is harder because you may not have labels immediately; you detect it via delayed performance metrics (AUC, calibration, business KPIs) and proxy signals.
Label shift means the outcome distribution changes: P(Y) shifts, even if P(X|Y) is stable. In many systems, label shift happens when the definition of “positive” changes (policy updates) or when the population’s base rate changes (seasonal default rates, outage spikes). Monitoring label frequencies is valuable, but interpret carefully: a drop in positives can be real business improvement, not a model issue.
Practically, your drift report should separate these: data drift alerts route to data engineering (pipeline, schema, upstream); concept drift concerns route to model owners (retraining, feature updates, threshold adjustments); label shift may route to business stakeholders (policy, product changes) and to calibration/threshold tuning. A common pitfall is treating every shift as a retraining trigger—often the right action is to fix a data pipeline regression or update baselines for an expected seasonal change.
Numeric features benefit from a mix of interpretable and sensitive drift metrics. Three practical defaults are Population Stability Index (PSI), the Kolmogorov–Smirnov (KS) test, and Wasserstein distance. Use more than one because each fails differently.
PSI is widely used in risk and credit because it is easy to explain. You bucket values (often using training quantiles), compute the proportion of traffic in each bucket for reference vs current, and sum the log-ratio differences. PSI is stable, but it depends heavily on binning; poor bins can hide drift (too coarse) or create noise (too fine). Keep bin definitions fixed for comparability and treat PSI as an “operational smoke detector,” not a scientific test.
KS test compares the maximum difference between empirical CDFs and returns a p-value. It is sensitive, which is both a strength and a trap: with high volume, tiny shifts become statistically significant. To avoid alert fatigue, pair KS with an effect size threshold (e.g., require both p-value < 0.01 and KS statistic > 0.05) and ensure your comparison window is long enough to avoid spurious day-to-day variation.
Wasserstein distance (Earth Mover’s Distance) is often a better “practical drift” measure because it corresponds to how much mass must move to match distributions. It’s interpretable in the units of the feature when not standardized. Use it to catch gradual shifts and to rank features by business relevance (e.g., a $5 change in “order_value” may matter; a 0.02 shift in a normalized score may not).
In your drift report, include: reference window definition, binning strategy for PSI, the current window size, and a “top shifted percentiles” snippet (e.g., p50 and p95 moved) to guide investigation quickly.
Categorical features drift differently: the set of categories can grow, rare categories can explode, and “unknown/other” rates can signal upstream breakage. A practical toolkit includes the chi-square test, Jensen–Shannon divergence (JSD), and explicit monitoring of population composition changes (top-k categories, new categories, and tail mass).
Chi-square tests whether observed counts differ from expected counts under the reference distribution. Like KS, chi-square becomes overly sensitive with large sample sizes. Use it as a detection signal, but gate alerts using a practical measure such as total variation distance, or require a minimum change in the share of at least one business-critical category (e.g., “traffic_source=affiliate” rose by 8 points).
JSD is a symmetric, smoothed version of KL divergence; it is bounded and behaves well when some categories are missing in one window. This makes it robust for production monitoring. It’s particularly useful when you want a single “how different is it?” score that is comparable over time. Always standardize your category mapping: collapse rare categories into “other” based on a fixed rule, and treat “null/empty” as its own category so missingness drift is not hidden.
Population changes can be the real story: a model might perform worse not because features are corrupted, but because the serving population expanded. Your report should call out: (1) new categories, (2) large shifts in top categories, and (3) growth in tail mass (“other” share). This is also where text features show up in disguised form: if you track a “language” or “token_count” categorical/bucketed feature, changes often indicate a new content mix that may require embedding-based monitoring (covered later).
Operationally, route large “unknown/other” increases to data pipeline owners first. Route genuine population shifts (new region, new acquisition channel) to model owners to validate performance by segment and recalibrate thresholds if needed.
Univariate tests can miss the most damaging changes: shifts in relationships between features. For example, “device_type” and “latency_ms” may individually look stable, but the combination “device_type=low_end AND latency_ms high” might spike due to a regional outage. Multivariate drift signals help you catch interaction changes that affect decision boundaries.
A practical approach is to add one or two multivariate monitors that are cheap to run and easy to interpret. One option is a drift classifier: train a simple model to distinguish reference vs current records using a subset of features. If it achieves high AUC, the distributions differ in a multivariate way. This doesn’t tell you what changed, so pair it with feature importance from the drift classifier (e.g., permutation importance) to generate investigation leads.
Another option is monitoring model input embeddings (or intermediate representations). For text, images, or high-cardinality IDs, embedding drift can be more sensitive than token-level statistics. Compute an embedding per record (from your encoder or a frozen model layer), then track distances between reference and current embedding distributions (e.g., mean/covariance shifts, MMD, or Wasserstein in embedding space). Keep it operational: sample embeddings, store summary stats, and version the encoder so changes in representation don’t look like data drift.
In drift reports, treat multivariate signals as “escalation evidence.” If univariate drift is mild but the drift classifier AUC spikes, you likely have interaction drift worth deeper segmentation and performance checks.
Drift rarely affects everyone equally. Segment-based monitoring (cohorts, regions, devices, customer tiers) is often the difference between catching an incident and missing it. A global distribution can look stable while one region collapses—especially if that region is a small fraction of total traffic but high business value or higher risk.
Choose segments that align with business and operational boundaries: geography (data residency, partner integrations), device/app version (release cycles), acquisition channel (campaigns), and “cold start” vs “returning.” Limit to a manageable set, then add a “top changing segment” detector to surface surprises without hardcoding every cohort.
Baselines and windows determine whether you detect real drift or just normal variation. Use a rolling window for the current period (e.g., last 24 hours for near-real-time, last 7 days for weekly cycles) and compare to a seasonality-matched baseline when applicable (e.g., same day-of-week over the past 4 weeks). For strong seasonality, a simple “training baseline” will generate constant alerts. If you have business cycles (paydays, holidays), maintain separate baselines or exclude known anomaly periods.
Your drift report should explicitly state the windowing choices and why: “7-day rolling vs weekday-matched baseline to account for weekend traffic.” This makes the outputs defensible and easier to tune when stakeholders ask why alerts triggered.
Drift metrics become operational only when you translate them into severity and actions. The goal is not to prove distributions differ; the goal is to decide when to investigate, when to mitigate, and when to retrain. Build a drift severity score that combines multiple signals while reflecting model risk, feature importance, and business impact.
A practical severity scheme is layered: (1) per-feature drift measures (PSI/KS/Wasserstein for numeric; JSD/chi-square for categorical), (2) per-feature practical drift flags (effect size thresholds), (3) segment multipliers (high-risk segments get higher weight), and (4) aggregation into a small number of alert categories: Info, Investigate, and Act. Weight features by model sensitivity if you can (e.g., SHAP importance from training) so drift in a critical feature matters more than drift in a rarely used one.
Set thresholds using historical backtesting: replay drift metrics over prior months and mark known incidents (pipeline bugs, launches, seasonal peaks). Tune to minimize false alerts while ensuring you would have caught real problems. Where possible, tie “Act” to downstream evidence: combine drift severity with a performance proxy (prediction distribution shift, calibration drift, or delayed label-based metrics) before paging someone.
Finally, format your drift output as a drift report, not just charts: a ranked list of top drifting features and segments, the suspected cause category (pipeline vs population), links to relevant logs/traces, and a recommended next step with an owner. This turns drift detection into a repeatable operational practice rather than a dashboard that everyone ignores.
1. Why does Chapter 3 argue that drift monitoring is only useful when tied to two operational questions?
2. Which workflow best matches the chapter’s recommended practical drift detection process?
3. What is the key lesson about interpreting univariate drift tests in production?
4. Which is identified as a common mistake that leads to poor drift monitoring outcomes?
5. Why does the chapter recommend segment-based drift analysis (e.g., by region or device), even if overall drift looks small?
Many production ML incidents are not “model problems” at all—they are data problems that quietly change what the model sees. A new upstream column type, a delayed batch file, a join that suddenly multiplies rows, or a missing category that turns into nulls can degrade predictions without any obvious exceptions. These are silent breakages: the pipeline still runs, metrics may even look stable in aggregate, and yet business KPIs drift.
This chapter focuses on building data quality checks that catch these failures early and route them to the right owner. You will learn to define a schema contract, validate freshness and completeness, detect impossible values and distribution truncation, score dataset quality, and enforce “quality gates” that block bad data from reaching training and inference. The goal is not to “check everything,” but to implement a practical set of controls aligned to risk: what data issues can materially impact revenue, safety, compliance, or user experience, and how quickly do you need to detect them?
As you read, keep a mental model of where data quality can fail: at ingestion (missing files, wrong encoding), in transformation (bad parsing, unit conversions), at joins (duplication, mismatched keys), and at the final feature vector (unexpected nulls, out-of-range values). A robust monitoring strategy makes these failures observable and actionable, with clear thresholds, ownership, and runbooks.
The sections that follow translate these ideas into concrete checks you can implement in batch ETL, streaming feature pipelines, and online inference services.
Practice note for Build a schema contract and automated validation rules: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Implement freshness, completeness, and uniqueness checks: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Detect outliers, impossible values, and distribution truncation: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create dataset-level quality scores and gating rules: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Operationalize checks: where they run and how failures route: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build a schema contract and automated validation rules: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Implement freshness, completeness, and uniqueness checks: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Detect outliers, impossible values, and distribution truncation: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
A schema contract is a shared agreement between data producers and consumers about what a dataset looks like: column names, types, allowed values, units, and key semantics. In ML systems, the “consumer” is often a feature pipeline or model server, which can fail subtly when the schema changes. A string that becomes an integer may not crash your code if it’s coerced; it may simply change feature meaning. That is why contracts should be explicit, versioned, and enforced automatically.
Start with a machine-readable specification (for example: JSON Schema, Avro/Protobuf schemas, or a Great Expectations/Deequ-style expectation suite). Include: required columns, data types, nullable vs non-nullable fields, primary keys, and stable identifiers. Add semantic annotations that matter for ML, such as “value is in USD,” “timestamp is UTC,” or “categorical vocabulary is limited.” These notes become testable rules (e.g., “currency_code must be one of [USD, EUR]”).
Schema evolution is inevitable. The key is to manage it deliberately. Use versioning and compatibility rules: backward compatible changes (adding an optional column) can be auto-accepted; breaking changes (renaming a column, changing units) must require a coordinated rollout. A practical workflow is: producer opens a schema change request, CI runs validation against sample payloads, and consumers run contract tests that ensure they can still parse and interpret the data. Promote changes through environments with the same checks running at each stage.
Finally, document ownership: who approves schema changes, who receives alerts, and what the rollback plan is. Data contracts are as much operational governance as they are validation code.
Freshness is the simplest quality property and one of the most damaging when it fails. If yesterday’s data is missing, a dashboard may look “normal” while the model uses stale features. To avoid this, define explicit service level indicators (SLIs) for timeliness and measure them continuously.
Useful freshness SLIs include: data age (now minus max event timestamp), delivery delay (ingestion time minus event time), and pipeline latency (end-to-end runtime). For batch, you can compute “age of latest partition” or “last successful load time.” For streaming, track watermark lag and the percentage of events arriving later than your allowed lateness window.
Then convert SLIs into alertable objectives. A practical approach is tiered thresholds: a warning at 2× normal delay and a page at 4×, or an SLO like “99% of hourly feature tables are available within 20 minutes.” Use baselines and seasonality: a retail system may legitimately be slower during nightly backfills, so compare to historical patterns at the same hour/day. If you don’t account for seasonality, you will generate noisy alerts that get ignored.
Implementation detail: record freshness metrics as time series (age, lag, last-success timestamp) and attach dimensions such as dataset name, partition, region, and upstream dependency. These tags make it possible to triage whether the problem is global or isolated to a slice.
Completeness answers: “Do we have the fields and rows we expect?” Null checks are the starting point, but completeness in ML is more nuanced. A feature can be non-null yet uninformative (all zeros), or a column can be present but systematically missing for a specific segment, causing biased predictions.
Implement completeness checks at multiple levels. At the dataset level, track row counts per partition and compare against expected ranges or historical baselines. At the column level, compute null rate, empty-string rate, and default-value rate. For sparse features (common in text, ads, and recommender systems), monitor “non-zero rate” or “distinct count” rather than nulls alone. For categorical features, watch the fraction mapped to “unknown” after encoding; a spike often indicates an upstream taxonomy change.
Missingness patterns matter: if null rate increases only for one geography, device type, or customer tier, your global metric may hide the issue. Slice completeness metrics by critical dimensions and set separate thresholds. This is especially important for fairness and compliance, where missing data can disproportionately affect protected groups.
Where possible, measure completeness relative to a source of truth. Example: if you expect one row per active user per day, compare your feature table’s user count to the authoritative user registry count. This turns completeness into a reconciliation problem, which is far more reliable than thresholds alone.
Validity checks ensure the data values make sense. They protect against impossible values (negative ages), unit mistakes (cents vs dollars), and corrupted strings (timestamps parsed as 1970). These errors often survive schema checks because the type is still correct—an integer is an integer—but the semantics are wrong.
Start with straightforward constraints: numeric ranges (min/max), monotonicity where applicable (end_time ≥ start_time), and allowed enumerations (country codes, device types). For enums, track both invalid rate (values not in the set) and new-value rate (values not seen before). New values are not always bad; they may represent legitimate growth. Treat them as a review signal rather than an automatic failure unless the risk is high.
Referential integrity is critical for joins and feature enrichment. If a feature table references a user_id, validate that user_id exists in the user dimension table at an acceptable rate, and monitor the join match rate over time. A sudden drop in match rate often indicates key-format changes, late-arriving dimensions, or incorrect filtering. This also helps detect distribution truncation: if only certain keys are matching, you may be systematically excluding segments.
To detect outliers and truncation, go beyond point constraints. Track percentiles (p1, p50, p99) and the fraction of values clipped by preprocessing. If clipping suddenly increases, your model may be operating on saturated features, which can degrade performance even if no values violate a hard range.
Duplicates are a classic silent breakage because they can inflate counts, skew aggregates, and distort training labels. Inference pipelines can also duplicate requests due to retries or idempotency bugs, leading to misleading monitoring metrics and inconsistent user experiences.
Define uniqueness explicitly: what is the primary key for each dataset and at what granularity (user-day, session-event, transaction-id)? Implement duplicate rate checks (count of keys with frequency > 1) and, for streaming, detect replays by measuring the fraction of repeated event_ids within a time window. For batch, compare row counts to distinct key counts and alert on deviations.
Joins amplify duplication. A one-to-many join can explode row counts if the “many” side unexpectedly gains duplicates. Monitor join cardinality (rows after join / rows before join) and join match rate. If cardinality spikes, you may be unintentionally duplicating training examples, which can bias the model. If match rate drops, you may be losing enrichment and increasing nulls downstream.
Leakage is another pipeline bug that data quality checks can catch. If a feature accidentally includes future information (e.g., a label-derived aggregate), training performance looks great while production performance collapses. While leakage is primarily a modeling concern, you can add pipeline-level guards: enforce temporal constraints (feature_time ≤ prediction_time), verify that training labels are not present in feature tables, and validate that aggregates use only allowed windows.
Operationally, duplicates and join anomalies are among the easiest issues to turn into actionable tickets because they usually map to a specific pipeline step. Store “before/after” counts as metrics per job stage so you can pinpoint where the explosion begins.
Checks only help if failures change system behavior. A quality gate is a decision point where the pipeline either proceeds, falls back, or quarantines data based on quality signals. The right gating strategy depends on risk and the cost of interruption.
In training pipelines, you can be strict. If schema validation fails, if duplicates exceed a threshold, or if label coverage drops, block the run and notify the pipeline owner. Training on bad data creates long-lived damage because the model artifact persists. Use dataset-level quality scores to summarize multiple checks: assign weights to freshness, completeness, validity, and duplication, then compute an overall score per partition. Gate training on “score ≥ 0.95” plus a small set of non-negotiable hard rules (e.g., primary key uniqueness must hold).
In inference pipelines, availability often matters more. Instead of hard-stopping, use controlled degradation: fall back to last-known-good features, switch to a simpler model that uses fewer features, or return a safe default decision. Still record the quality failure prominently and alert the team, because “fallback mode” should be rare and time-bounded. Define an SLO like “feature store fallback < 0.1% of requests per day.”
Where do checks run? Place them where they are cheapest and most informative:
Finally, route failures intentionally. Not every failed check should page an on-call. Classify failures by severity and owner: producer data contract violations go to upstream data engineering; feature logic anomalies go to ML platform; inference-time spikes go to the service on-call with a clear rollback or fallback instruction. The practical outcome is a monitoring system that prevents silent breakages by making data quality an enforced interface, not a best-effort hope.
1. Which scenario best describes a “silent breakage” in a production ML pipeline?
2. What is the primary purpose of a schema contract and automated validation rules?
3. Which set of checks most directly addresses delayed or missing batches and missing required fields?
4. A join change suddenly multiplies rows and inflates the dataset size. Which check is most appropriate to catch this early?
5. What is the role of dataset-level quality scores and “quality gates” in a monitoring strategy?
Once you have solid data quality and drift detection (Chapters 3–4), the next step is making monitoring actionable: tying signals to real user impact, turning them into alerts that people trust, and presenting them in dashboards that support fast triage. Performance monitoring is not just “track accuracy.” In production, labels can be delayed, missing, or biased; traffic mixes shift by time of day; and every alert competes for attention with other operational work. A mature strategy combines (1) direct performance metrics when labels exist, (2) proxy and consistency metrics when they do not, (3) alert policies tuned to risk and service-level objectives (SLOs), and (4) noise reduction so the team can respond reliably.
This chapter focuses on engineering judgement: what to measure, how to slice metrics, when to page a human, and how to reduce alert fatigue. You will also learn dashboard patterns for root-cause analysis (RCA) and how to turn monitoring into an on-call runbook that accelerates resolution rather than producing blame or confusion.
The throughline is practical: every metric should answer a question someone will ask during an incident (“Is this real?” “Who is affected?” “What changed?” “What can we do now?”). If a metric cannot support a decision, it may belong in a report, not in an alerting system.
Practice note for Monitor prediction quality with and without labels: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design alerts: thresholds, anomaly detection, and burn-rate style paging: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build dashboards for triage: drill-down by segment and feature: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Reduce alert fatigue with deduping, routing, and maintenance windows: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Write an on-call runbook for model incidents: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Monitor prediction quality with and without labels: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Design alerts: thresholds, anomaly detection, and burn-rate style paging: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build dashboards for triage: drill-down by segment and feature: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Reduce alert fatigue with deduping, routing, and maintenance windows: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
When you have labels (immediate or delayed), performance monitoring should look like a controlled experiment repeated continuously. Start with a small set of business-aligned metrics: for classification, consider precision/recall at an operating point, AUC for ranking, calibration error if probabilities drive decisions, and cost-weighted loss if false positives/negatives have different impact. For regression, track MAE/RMSE plus domain-specific thresholds (e.g., percent within tolerance). In all cases, compute metrics on the same population the business cares about, not a convenience sample.
Next, make slices first-class citizens. Overall accuracy can remain stable while a segment collapses (e.g., a locale, device type, new product category, or high-value customer cohort). Define slices based on: (1) known risk areas, (2) business value, and (3) model sensitivity (features strongly used by the model). Practically, store slice definitions in code so they can be versioned and reviewed. Common mistake: creating dozens of slices without ownership; instead, maintain a small curated set and add more during incidents.
Finally, treat monitoring as part of the release process. When deploying a new model, track performance by model_version and rollout cohort (A/B or canary). If you can’t attribute a metric shift to a version, you can’t debug quickly. A practical outcome of this section is a “performance scoreboard” that answers: what is performance, for whom, with what uncertainty, and compared to what baseline.
Many production systems operate without timely labels: fraud labels arrive weeks later, user satisfaction is implicit, or ground truth is costly. You still need monitoring that detects breakages early, but you must avoid proxies that merely track volume or seasonality. The goal is to measure model health and decision stability rather than “accuracy.”
Start with prediction-distribution monitoring: track score histograms (mean, quantiles, entropy) by segment and by model_version. Large shifts in predicted probabilities often correlate with data pipeline issues, feature defaults, or upstream product changes. Add consistency checks: if business rules imply monotonic relationships (e.g., higher income should not decrease approval probability on average), monitor monotonicity violations on aggregated bins. In ranking systems, track churn in top-K results (Jaccard similarity over time) to detect sudden reshuffles.
A common mistake is alerting on every distribution shift. Instead, connect proxies to risk: define “guardrail” ranges and require corroboration (e.g., a score distribution shift plus an increase in overrides). Practical outcome: a label-free monitoring suite that can detect regressions within minutes to hours, long before true labels arrive, while keeping false positives manageable.
Alerts turn metrics into action, but poorly designed alerts teach engineers to ignore the system. Begin by deciding what kind of signal you are dealing with. Static thresholds work well for hard limits: error rate, missing feature percentage, p99 latency, or “no predictions emitted.” They are easy to reason about and ideal for safety and availability. However, they fail for metrics with strong seasonality (traffic, conversion) or evolving baselines (new markets, changing user mix).
For those, use dynamic baselines: compare today’s metric to an expected value derived from history (same hour last week), a rolling quantile, or a time-series model. This is anomaly detection in practice, but the key is operational simplicity. Prefer methods that can be explained during an incident: z-scores on residuals, robust median/MAD, or week-over-week deltas with confidence bounds. Complex models can be correct yet still rejected by on-call engineers if they are opaque.
Practical outcome: a small alert catalog where each alert specifies the metric, baseline method, window, minimum volume, and a link to the dashboard panel that explains the anomaly.
Not every anomaly deserves a page. Define severity levels based on user impact, financial risk, and time sensitivity. A simple model is: SEV-1 (customer-facing outage or high-risk decisions), SEV-2 (material degradation with workaround), SEV-3 (minor degradation or investigation), and SEV-4 (informational). Tie each level to expected response time and communication requirements.
For paging, adopt an SLO mindset. If you have a prediction service SLO (e.g., 99.9% successful inferences, or “decision correctness within tolerance”), use burn-rate style alerts: page only when the error budget is being consumed fast enough to threaten the SLO soon. This prevents paging on brief blips while still catching sustained issues early. Burn-rate alerts are especially useful when traffic varies; they naturally scale with volume.
Practical outcome: paging policies that match risk and avoid waking people up for issues that can wait for business hours, while ensuring high-risk failures escalate quickly and predictably.
Dashboards are not posters; they are interactive tools for triage and decision-making. Build them around the incident questions: “Is the system up?” “Is the model behaving normally?” “Which users are affected?” “What changed?” A high-performing pattern is a three-layer dashboard: Overview, Drill-down, and Diagnostics.
The Overview should include request volume, success rate, latency percentiles, and a few headline model-health metrics (score quantiles, top proxy outcomes). Always include model_version and pipeline version overlays so changes can be correlated visually. The Drill-down layer breaks key metrics by segment (region, app version, customer tier) and by feature cohorts (missingness present vs not, bucketed numeric ranges). This is where you catch “only Android users in EU” failures quickly. The Diagnostics layer links to feature-level distribution panels, schema validation results, and recent deploy events.
Common mistakes include cramming too many charts, mixing event-time and processing-time, and omitting segment filters. Practical outcome: dashboards that let an on-call engineer localize an incident in minutes and choose a safe mitigation path.
Alert fatigue is not a people problem; it is a system design problem. If alerts fire too often, responders stop trusting them, and real incidents will be missed. Start by measuring alert quality: page volume per week, percent actionable, mean time to acknowledge, and “re-alert rate” (same issue paging repeatedly). Use these metrics to drive iterative tuning.
Deduplication is the first lever: group alerts by root cause dimensions (service, model_version, pipeline job, feature set) and ensure only one page opens an incident. Route secondary symptoms (e.g., proxy metric drops) as annotations on the primary incident rather than separate pages. Routing is the second lever: send SEV-3/4 to chat or ticketing, and page only SEV-1/2. If your monitoring stack supports it, route slice-specific issues to the owning team (e.g., payments model vs search ranking).
End this chapter by writing (and actually using) an on-call runbook for model incidents. Each alert should link to a runbook section containing: meaning of the alert, probable causes, immediate mitigations (rollback, fallback, rate limiting), diagnostic steps (which dashboard panels, which logs/traces to inspect), and escalation contacts. Practical outcome: fewer pages, faster resolution, and a monitoring system the team relies on rather than dreads.
1. Why does the chapter argue that performance monitoring in production is not just "track accuracy"?
2. What is the recommended approach to monitoring prediction quality when labels are not available?
3. According to the chapter, what is the primary purpose of alert policies in a mature monitoring strategy?
4. Which dashboard capability is emphasized for fast triage and root-cause analysis (RCA)?
5. How does the chapter suggest reducing alert fatigue while maintaining reliable response?
Monitoring only creates value when it changes outcomes. In production ML, that means you need an incident workflow that turns signals (drift, data quality failures, metric regressions, user complaints) into timely decisions: mitigate risk, restore service levels, and improve the system so the same failure is less likely to recur. This chapter focuses on operational excellence: how to run incidents, how to prove root cause with evidence instead of intuition, and how to connect mitigations to retraining and safer deployments.
ML incidents are rarely “model bugs” in isolation. They often involve a chain: an upstream schema change causes null inflation, which shifts feature distributions, which degrades calibration, which changes downstream business KPIs. Your response loop must therefore connect monitoring across data, model, and product. The goal is not perfect prediction; the goal is controlled risk and predictable performance aligned to business constraints and SLOs.
We will use a practical loop: detect → triage → mitigate → communicate → learn → harden. Each stage has artifacts you can standardize: a triage playbook, an evidence packet for root-cause analysis (RCA), mitigation runbooks (rollback, circuit breaker, shadow deploy), retraining triggers with evaluation gates, and postmortems that produce concrete new monitors and backlog items.
The rest of the chapter breaks this loop into repeatable practices you can adopt even in small teams, then scale as your system grows.
Practice note for Execute an incident workflow: detect, triage, mitigate, and communicate: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Perform root-cause analysis linking drift, quality, and performance: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Decide actions: rollback, retrain, recalibrate, or hotfix pipelines: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Implement retraining triggers and safe deployment gates: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Run postmortems and convert learnings into new monitors: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Execute an incident workflow: detect, triage, mitigate, and communicate: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Perform root-cause analysis linking drift, quality, and performance: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Decide actions: rollback, retrain, recalibrate, or hotfix pipelines: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Triage is the difference between “alerts” and “incidents.” A triage playbook tells responders exactly what to do in the first 15 minutes: verify the signal, assess impact, and decide whether to escalate. Start by defining severity levels in business terms (e.g., revenue at risk, regulatory exposure, customer harm) and map each severity to response times, on-call roles, and communication cadence. For example, a P0 might be “unsafe recommendations shown to users” or “fraud model blocks legitimate transactions at scale,” while a P2 might be “minor drift detected with no KPI movement.”
In ML, triage must look beyond the model metric. Confirm whether the issue is real and current: is the alert based on a delayed batch job? Is the baseline outdated due to seasonality? Compare multiple signals: data freshness, feature null rate, input distribution shift, inference latency, and business KPI deltas. A common mistake is treating drift alerts as incidents by default; drift is a risk indicator, not a guarantee of harm. Conversely, teams also miss incidents because they only watch offline accuracy and ignore online KPIs and user complaints.
Communication should be frequent, factual, and audience-specific. Engineers need logs, dashboards, and hypotheses; product and operations need impact and expected next update; leadership needs risk posture and mitigation plan. Use a simple template: what happened, when it started, current impact, what we’re doing now, and next update time. Avoid speculation—state what you know and what you’re validating. Document a live timeline during the incident; it will become the backbone of the postmortem and reduce time lost to memory gaps.
RCA in production ML is an evidence exercise: you are trying to connect a symptom (KPI drop, error spike, drift alert) to a causal chain across data, features, model behavior, and downstream systems. The workflow should be consistent so that different responders reach similar conclusions. Start with a hypothesis tree: data issues, pipeline issues, model issues, serving issues, and product/traffic changes. Then prune the tree with measurable evidence.
Build an “evidence packet” for every significant incident. At minimum it includes: the exact alert condition (threshold, baseline, window), affected model version(s), recent deploy/change history (code, config, feature definitions), data lineage (source tables, jobs, timestamps), and slices showing where the issue concentrates. Connect drift, quality, and performance explicitly: did a schema change introduce nulls? Did feature scaling change? Did a new upstream category appear? Did the label definition or delay change, making your performance estimate incorrect?
Common mistakes include relying on aggregate metrics only (masking a small but high-value segment), mixing time windows (comparing last hour to last week with different seasonality), and confusing correlation with causation (“drift happened, therefore drift caused the KPI drop”). To strengthen causal claims, look for temporal ordering (data change precedes metric change), segment alignment (the drifted slice is the slice with KPI damage), and counterfactual checks (re-run scoring on last-known-good data/model, or score current data with previous model in shadow mode). When you cannot prove a single root cause, document contributing factors and uncertainty; clarity about unknowns is itself actionable.
Mitigation is about reducing harm quickly while preserving the ability to learn. In ML systems, the fastest safe move is often to revert to a known-good state: roll back to the previous model artifact, feature set, or pipeline version. Rollbacks should be operationally boring—fully automated and tested—because you will need them under stress. Keep a catalog of last-known-good versions with their training data snapshot, evaluation report, and compatible feature schema to avoid “rollback fails due to missing features.”
Shadow deploys (a.k.a. shadow inference) are a powerful mitigation and learning tool. You route real production traffic to a candidate model but do not use its predictions for user-facing decisions. During incidents, shadowing can help answer: is the issue in the current model or upstream data? You can run the previous model in shadow to compare outputs and determine whether the new behavior is the culprit. Shadow deployments also support safe recovery: you can validate a hotfix model under real traffic before promoting it.
Circuit breakers are underused in ML because teams fear “turning off the model.” Design them with product partners: define what safe fallback looks like (e.g., conservative thresholds, human review queue, simpler heuristic). Tie breakers to a small set of robust signals: pipeline freshness failures, extreme drift beyond a hard cap, or unacceptably high error rates. A common mistake is wiring breakers to noisy metrics (e.g., single-feature drift spikes) and causing flapping. Use hysteresis (separate trigger and recovery thresholds) and minimum-duration conditions to prevent oscillation.
Not every incident should trigger retraining, and not every retrain should be deployed. Treat retraining as a controlled change with explicit triggers and gates. Triggers can be time-based (weekly retrain), event-based (new product launch changes traffic), or metric-based (sustained drift plus KPI degradation). The best triggers combine signals: for example, “PSI > 0.25 for 3 days in two critical features AND conversion rate down 2% relative to seasonal baseline.” This reduces false retrains that waste compute and introduce instability.
Before retraining, ensure your data is trustworthy. Incidents often reveal that training data pipelines lag behind serving data or that labels are delayed or corrupted. Plan for backfills: when a bug is found in a feature computation or label join, you may need to recompute historical features to restore consistency. Make backfills safe by versioning feature definitions, tracking lineage, and running reconciliation checks (e.g., distribution comparisons between backfilled and original data). If you cannot backfill, document the limitation and adjust evaluation expectations.
Gates should reflect your risk profile. For high-stakes models, require statistically significant improvements or non-inferiority tests, plus human review of failure cases. For lower-risk personalization, you might accept small offline regressions if online experiments show improvements. A common mistake is relying on a single metric (AUC) and ignoring thresholded behavior, calibration, or segment regressions. Another is deploying a retrained model without updating monitors: a changed feature set can invalidate drift baselines and create noisy alerts or blind spots.
Governance sounds heavy, but in production ML it is the mechanism that keeps monitoring aligned to risk, cost, and business KPIs. Start with ownership: each monitor should have an owner, a purpose, a severity mapping, and a runbook link. Without clear ownership, alerts become “someone else’s problem,” and incident response degrades into ad hoc firefighting.
Change management is especially critical because ML systems change frequently: data sources evolve, feature logic is refactored, thresholds are tuned, and models are retrained. Require every material change to carry monitoring implications: what new failure modes are introduced, which baselines must be re-established, and which dashboards must be updated? Lightweight processes work well: a PR checklist for “monitoring impact,” a changelog that feeds the incident timeline, and a weekly review of alert volume and false positives.
Common mistakes include “monitor everything” (unsustainable cost and noise), ignoring business KPIs (monitoring becomes disconnected from outcomes), and failing to review monitors after system changes (alerts drift out of relevance). Governance should also define when to deprecate monitors. A monitor that never triggers may be unnecessary, or it may be misconfigured; either way, it deserves review. Tie governance to your reliability goals: your monitoring strategy is successful when it enables confident decisions under time pressure.
Postmortems close the loop. They are not blame sessions; they are engineering tools to convert incidents into lasting improvements. Run a postmortem for any incident that meaningfully impacted users, violated an SLO, or exposed a serious near-miss. Use the incident timeline to reconstruct what happened, then ask structured questions: what detection worked, what was missing, what slowed triage, and which mitigations were effective or risky.
A strong postmortem ends with concrete prevention items. In production ML, these often become new monitors or stronger gates: adding a schema contract to prevent silent column type changes; introducing a join-key mismatch monitor; adding a calibration drift check; or creating an automated rollback trigger when error rates exceed a hard cap. Also include process improvements, such as clarifying on-call ownership, refining severity definitions, or improving stakeholder update templates.
Prioritization is where continuous improvement becomes real. Not every action item deserves equal weight; choose based on risk and frequency. A rare P0 safety issue may justify weeks of work; a frequent P2 data freshness alert might justify a simple retry strategy or SLA renegotiation. Finally, feed learnings back into training and deployment: if an incident showed that drift tests were too sensitive to seasonality, adjust baselines and add seasonality-aware thresholds. If it revealed missing slice monitoring, add segment dashboards. Over time, your incidents should become less frequent, smaller in blast radius, and faster to resolve—because your monitoring and response loop is now part of the system design, not an afterthought.
1. Why does monitoring "create value" in production ML, according to the chapter?
2. Which sequence best matches the practical incident-response loop described in the chapter?
3. What does the chapter suggest about the nature of many ML incidents in production?
4. During triage, what combination of actions is emphasized as core to handling an incident well?
5. What is a key expected output of the "Improve" stage after an incident?

- Learning Evolved.
- Intelligence Amplified.

