AI Certifications & Exam Prep — Intermediate
Pass AICE Associate by shipping a real Vertex AI pipeline end-to-end.
This course is a short technical book in 6 tightly-sequenced chapters that prepares you for the AICE Associate exam by having you build and deploy a real Vertex AI pipeline. Instead of memorizing isolated facts, you’ll practice the same decisions the exam tests: choosing the right Vertex AI capability, securing access with IAM, designing reproducible components, registering models, deploying safely, and monitoring in production-like conditions.
You’ll finish with a working end-to-end pipeline that ingests data, validates it, trains a model, evaluates against thresholds, registers model versions, and deploys to an endpoint—plus a CI/CD path to rebuild and promote across environments. The structure is intentionally “book-like”: each chapter introduces only what you need to complete the next milestone, reinforcing exam objectives through implementation.
This bootcamp is designed for learners who want a practical, exam-aligned path into Google Cloud’s Vertex AI ecosystem. It’s ideal if you can write basic Python and want to level up your MLOps skills while preparing for certification-style scenario questions.
Across the chapters, you’ll construct a reference pipeline that reflects real-world constraints: secure access, reproducible execution, clear artifact lineage, and deploy/monitor discipline. You’ll implement dataset versioning, preprocessing as a component, training and evaluation steps, model registration, and both online and batch prediction patterns.
Chapter 1 aligns exam domains to an implementable architecture and a project plan so you know exactly why each step exists. Chapter 2 establishes the cloud foundation—project setup, IAM, storage patterns, and cost controls—so your work is secure and sustainable. Chapter 3 turns raw data into governed, validated inputs with repeatable preprocessing. Chapter 4 is the core build: authoring components, composing the pipeline, and learning how execution artifacts and caching work in Vertex AI Pipelines. Chapter 5 focuses on the model lifecycle—experiments, evaluation gates, and model registration. Chapter 6 completes the production loop: deployment, monitoring, and CI/CD for rebuilds and promotions, followed by an exam-readiness checklist and scenario drills.
Pipeline-first learning: every concept is anchored to a step in the workflow, mirroring how AICE questions are framed.
Operational realism: cost controls, IAM boundaries, and promotion mechanics are included from the beginning.
Reusable blueprint: you can adapt the final architecture to your own datasets and projects after the exam.
If you’re ready to prepare for the AICE Associate exam by building the thing you’re studying, start here: Register free. Want to compare options first? You can also browse all courses to see related certification and MLOps learning paths.
Senior Machine Learning Engineer (GCP & MLOps)
Sofia Chen is a Senior Machine Learning Engineer specializing in production ML on Google Cloud, with a focus on Vertex AI pipelines, CI/CD, and governance. She has led multiple end-to-end MLOps implementations from experimentation through monitored deployment and supports teams preparing for cloud AI certification exams.
This bootcamp is designed to do two things at once: help you pass the AICE Associate exam and leave you with a working, deployable Vertex AI Pipelines reference project you can reuse. The key idea is to treat the exam blueprint as a set of engineering requirements. Every objective becomes a concrete artifact: a dataset version, an IAM binding, a pipeline component, an experiment run, a model in the registry, and a deployment on an endpoint (plus batch prediction). When you study this way, memorization is replaced by repeated implementation.
In this chapter you will set your study plan and success criteria, translate exam domains into a pipeline-driven architecture, choose a dataset and ML problem statement, standardize your environment and repository, and run a “hello pipeline” to prove that your setup is correct. The goal is not a perfect model—your goal is a reliable execution path from data ingestion to a deployed model, with cost controls and observability in place.
A common mistake in certification prep is over-investing in notebooks and under-investing in reproducibility. Vertex AI Pipelines is the forcing function: if your work runs as a pipeline with pinned dependencies, clear I/O contracts, and tracked artifacts, you are studying the exam in the same shape you will apply it in real projects.
Practice note for Set your AICE Associate study plan and success criteria: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Translate exam domains into a pipeline-driven reference architecture: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Choose a project dataset and define the ML problem statement: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create an environment checklist (tools, repos, and naming standards): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Baseline a “hello pipeline” to validate setup: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Set your AICE Associate study plan and success criteria: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Translate exam domains into a pipeline-driven reference architecture: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Choose a project dataset and define the ML problem statement: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create an environment checklist (tools, repos, and naming standards): document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
The AICE Associate exam is easiest to manage when you convert domains into deliverables. Your study plan should define “done” in terms of what you can build and explain, not what you can recognize in multiple choice. Use a two-track approach: (1) weekly implementation milestones in GCP, and (2) daily review of terminology, limits, and best practices that explain why your implementation is correct.
High-yield topics typically cluster around platform boundaries and operational judgement: IAM and least privilege for service accounts, storage choices (Cloud Storage vs BigQuery), when to use Vertex AI Datasets vs external tables, how pipelines execute and cache, and how training and deployment resources affect cost and reliability. Treat cost controls as a first-class topic: budgets, alerts, quotas, and autoscaling are operational skills that appear both in exam scenarios and real incidents.
By the end of this chapter, you should have a written study plan with concrete milestones (e.g., “by Friday: dataset versioned + validation component + budget alert configured”) and a working baseline pipeline run you can iterate on throughout the course.
Vertex AI is best understood as a set of connected surfaces that manage the ML lifecycle: data access and feature sources, training execution, experiment tracking, artifact and model governance, and serving/batch prediction. The exam often tests whether you understand which surface owns which responsibility—and how identities and locations (region, project) affect integration.
Data usually lives in Cloud Storage (files such as CSV/Parquet/images) and/or BigQuery (tables and SQL-based transformations). Vertex AI Datasets can catalog certain data types and streamline UI-driven workflows, but pipelines frequently reference data directly in GCS/BigQuery for repeatability. A practical rule: keep raw immutable data in GCS/BigQuery, and treat any derived dataset as a versioned artifact produced by a pipeline step.
Training in Vertex AI can be done with custom training jobs (your container) or prebuilt containers, and it can be orchestrated through Pipelines so every run is parameterized and traceable. The judgement call is about control vs speed: prebuilt containers accelerate setup, custom containers enforce exact reproducibility.
Tracking and governance is split across Vertex AI Experiments (run metadata, parameters, metrics) and the Model Registry (model versions, lineage, deployment targets). Many teams forget to wire metrics into Experiments; for the exam and for operations, you should be able to point to the run that produced a model and the evaluation that justified promotion.
Deploy includes online endpoints (latency-sensitive, autoscaling) and batch prediction (cost-efficient for large offline scoring). Your architecture should support both, even if your chosen use case primarily needs one. Common pitfalls include region mismatches (data in one region, endpoint in another), under-scoped service accounts for prediction, and forgetting to set min/max replica settings, which leads to either unexpected costs or throttling.
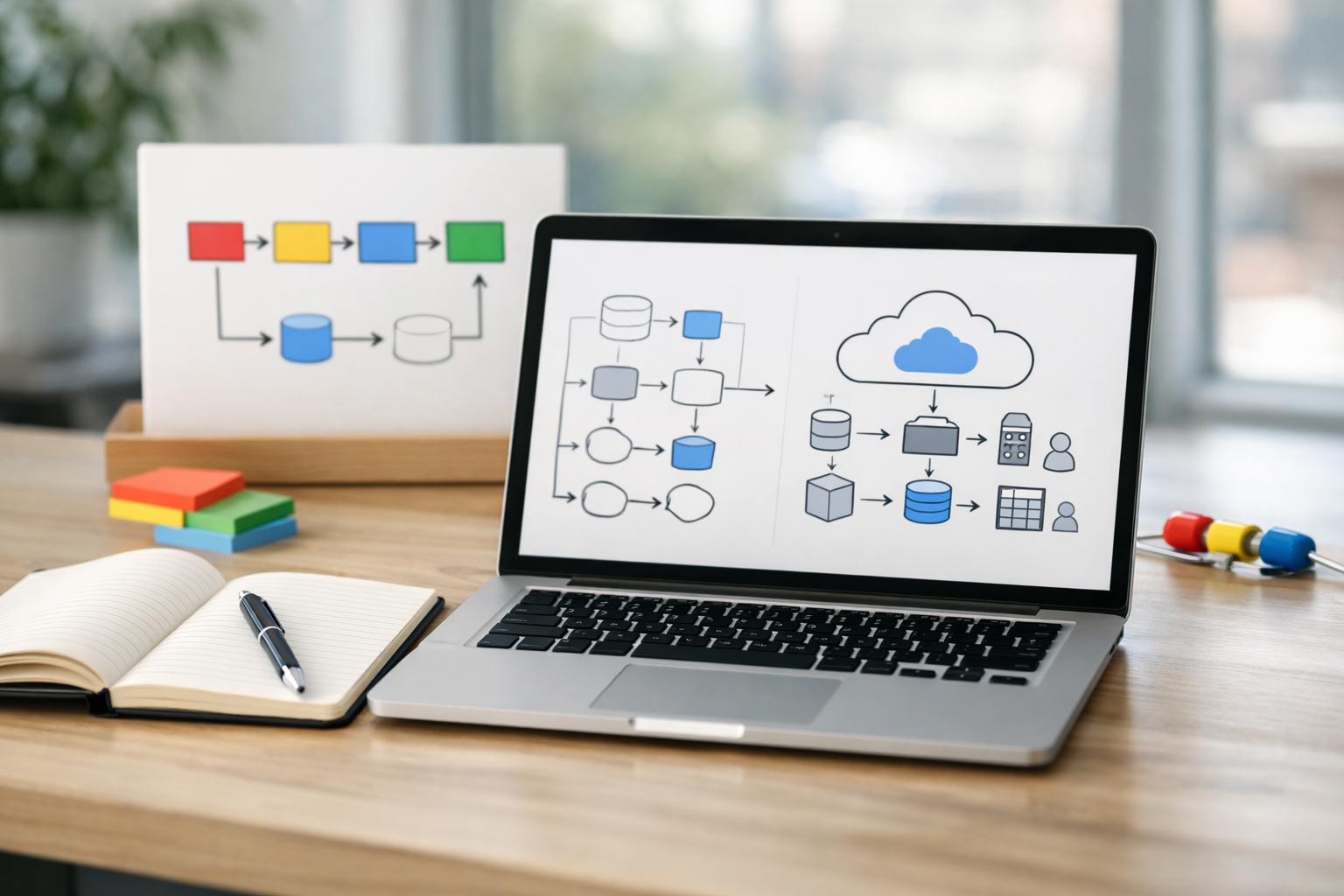
A pipeline-first architecture means your “system of record” is the pipeline definition and its artifacts—not an interactive notebook. In Vertex AI Pipelines (Kubeflow Pipelines under the hood), each component is an isolated step with explicit inputs and outputs. This design forces good engineering: deterministic transformations, clear contracts, and re-runnable jobs.
Translate exam domains into a reference pipeline that you will reuse throughout the bootcamp. A practical baseline is: (1) ingest from GCS/BigQuery, (2) validate schema and basic statistics, (3) split and preprocess, (4) train, (5) evaluate, (6) register model, (7) deploy to endpoint, (8) run a small batch prediction. Each step should produce artifacts: validation report, dataset manifest, model artifact URI, metrics JSON, and a registry entry.
Understand the execution model so you can troubleshoot quickly. Pipelines compile to a DAG; each node runs as a managed task. Caching can skip steps when inputs and code signatures match—great for iteration, confusing when you expect a step to rerun. Decide early when to enable caching and when to disable it for debugging. Also decide where parameters live: use pipeline parameters for values that change by environment (project ID, region, dataset URI), and avoid hardcoding.
The outcome of this section is an architecture diagram you can describe: data sources → pipeline orchestration → training jobs → experiment tracking → registry → online/batch serving, with identities, regions, and artifact locations called out.
Your project dataset should be simple enough to move quickly, but realistic enough to exercise the platform. Pick a supervised learning problem with a clean target column and a stable evaluation metric. Examples include tabular classification/regression in BigQuery public datasets, or a CSV dataset you store in Cloud Storage. Avoid datasets that require heavy scraping, large GPU training, or ambiguous labels—those slow down pipeline learning.
Write a one-paragraph ML problem statement that includes: who the user is, what prediction is needed, what the input features are, and what success looks like. Then define evaluation criteria before you write training code. For classification, specify metrics like AUC, precision/recall at a threshold, and calibration considerations. For regression, choose RMSE/MAE and define acceptable error bands. If you plan to deploy online, add latency and cost targets (p95 latency, max cost per 1K predictions). If you plan batch prediction, define throughput and total job completion time expectations.
This is also where you decide how to validate data. At minimum, implement schema checks (types, required columns), range checks for numeric fields, missing value thresholds, and label distribution drift compared to a baseline. A common mistake is treating “train/test split” as validation; instead, validate the dataset itself as a pipeline gate. When validation fails, the pipeline should stop and produce a readable report artifact.
Practical outcome: you will have a dataset choice, a stable train/validate/test strategy, and a metrics contract that your evaluation component must output (for Experiments and for model promotion decisions).
Certification scenarios often assume you can work in a team setting with consistent naming, repeatable builds, and auditable changes. Start with a repository structure that cleanly separates pipeline orchestration from component code and infrastructure configuration. Keep pipeline code in a place where it can be executed by CI/CD later, even if you run it manually now.
A practical structure: /pipelines for pipeline definitions and compilation, /components for component implementations (each with a clear interface), /infra for scripts/terraform (optional), /notebooks only for exploration (not production), and /configs for environment-specific values. Use a consistent naming standard for GCS buckets, BigQuery datasets, and Vertex resources (project-env-purpose-region). This prevents collisions and makes logs readable.
By the end of this section you should have an environment checklist: required tools (gcloud, Python, Docker if needed), a single source of truth for project/region naming, and a repo that supports repeatable pipeline runs on any machine.
Your first execution milestone is a “hello pipeline” that proves plumbing, not model quality. Keep it intentionally small: a pipeline with two to four components—ingest a tiny slice of data, run a lightweight validation, perform a trivial “train” step (even a fast baseline model), and write metrics to an output artifact. If your environment is correct, this run should complete quickly and leave behind visible artifacts in Vertex AI Pipelines and (optionally) Experiments.
Use this run to validate: your project configuration, service account permissions, bucket access, BigQuery access (if used), artifact storage location, and pipeline compilation/submission workflow. Confirm you can find logs for each component and that failures are actionable.
The practical outcome is confidence: you can run a pipeline end-to-end, retrieve artifacts, and debug with logs. This baseline becomes your template for the rest of the course—each subsequent chapter will replace the placeholder steps with production-grade components for ingestion, validation, training, evaluation, registry, and deployment.
1. In this bootcamp, how should you treat the AICE Associate exam blueprint to best support both passing the exam and building a reusable project?
2. Which outcome best matches Chapter 1’s primary goal for your first working system?
3. What does the chapter suggest is the biggest shift from memorization to effective certification prep?
4. Why does Chapter 1 argue that Vertex AI Pipelines acts as a “forcing function” for good prep and real-world readiness?
5. Which set of activities best represents what you complete in Chapter 1 before moving deeper into the course?
Before you build a single Vertex AI Pipeline component, you need a foundation that is secure, traceable, and predictable in cost. Many ML projects fail operationally not because the model is wrong, but because the platform setup is ad-hoc: APIs are enabled in the wrong project, pipelines write artifacts to random buckets, permissions are overly broad, and training jobs surprise the team with large bills.
This chapter turns “GCP basics” into ML-specific engineering practice. You will provision a project and resource organization that matches how Vertex AI actually runs workloads. You will lock down IAM with least privilege and purposeful service accounts. You will establish safe storage patterns for datasets and artifacts across Cloud Storage and BigQuery, and you will think through networking and egress—because data and model artifacts must move, and movement costs money and creates risk.
Finally, you will add cost controls (budgets, labels, quotas) and validate that your local/dev environment can access GCP correctly. The practical outcome is that when you start building pipelines in later chapters, you are not debugging “permission denied,” “API not enabled,” or “why did that training job pull 2 TB over the internet?” You are executing within guardrails.
Practice note for Provision the project, APIs, and resource organization: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Lock down IAM roles and service accounts for least privilege: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Configure storage, encryption, and key paths for artifacts: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Establish budgets, quotas, and labels for cost tracking: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Validate access from local/dev environment to GCP: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Provision the project, APIs, and resource organization: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Lock down IAM roles and service accounts for least privilege: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Configure storage, encryption, and key paths for artifacts: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Establish budgets, quotas, and labels for cost tracking: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Validate access from local/dev environment to GCP: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
A Vertex AI solution is anchored to a GCP project. Treat the project as the security and billing boundary for your pipeline. For exam scenarios and real-world buildouts, prefer a dedicated project for the bootcamp (for example, aice-vertex-pipelines-dev) rather than reusing a shared “sandbox” where policies and quotas are unknown.
Choose a primary region deliberately. Vertex AI training, pipelines, model registry, and endpoints are regional resources; crossing regions increases latency and can add egress cost. A good default is to keep Cloud Storage buckets for artifacts and datasets in the same region as Vertex AI (for example, us-central1) and only replicate when there is a clear compliance or availability requirement.
Enable APIs early and explicitly; many build failures are simply missing API enablement. Minimum set commonly required for this course: Vertex AI API, Cloud Storage, BigQuery, Artifact Registry (if you build custom containers), Cloud Logging, Cloud Monitoring, Cloud Build (optional), and IAM Service Account Credentials API (for some auth flows). In practice, enable only what you need and document why—API enablement is a governance signal.
gcloud is pointing at another; always confirm gcloud config get-value project.Resource organization matters too. If your org uses folders (e.g., dev, test, prod), place the project accordingly so policies and budget alerts inherit correctly. Even in a bootcamp, adopt the habit: you are training for production thinking.
Vertex AI Pipelines runs workloads on managed infrastructure, but those workloads still need identity. The secure pattern is: humans have minimal interactive access; automation uses service accounts; and each workload has only the permissions it needs. This is least privilege in a form you can reason about during incidents and audits.
Create dedicated service accounts for major responsibilities. A common split is: one service account for pipeline execution (orchestrator identity), another for training jobs, and optionally a separate one for deployment. Assign roles at the narrowest scope (project, bucket, dataset) you can manage. For example, allow the training service account to read a specific data bucket and write to a specific artifacts bucket, rather than granting broad editor access on the project.
roles/aiplatform.user for submitting jobs; roles/storage.objectAdmin scoped to the artifacts bucket; roles/bigquery.dataViewer for reading tables; roles/bigquery.jobUser for running queries.roles/editor “to make it work.” This hides missing permissions and causes future breakage when policies tighten.Workload Identity is the mechanism that maps a runtime identity (often in Kubernetes or managed services) to a Google service account without distributing long-lived keys. The security judgment is simple: avoid service account keys whenever possible. If you must use a key temporarily (for a local proof-of-concept), treat it as a secret, time-box it, and rotate it out when Workload Identity or user-based auth is available.
For this course, validate that your pipeline execution identity can: (1) create Vertex AI Pipeline runs, (2) read input data sources, (3) write artifacts and logs. Test permissions with small “canary” actions (list buckets, run a trivial BigQuery query) before launching large training jobs—this is faster and cheaper than failing halfway through a run.
ML data usually lives in two shapes: files (images, parquet, TFRecords) and tables (structured features). In GCP, Cloud Storage (GCS) and BigQuery are the default homes. The key is to decide what goes where and to keep datasets versionable and discoverable.
Use Cloud Storage for immutable-ish artifacts: raw files, training/validation splits, exported datasets, model artifacts, and pipeline outputs. Adopt a bucket naming convention and a folder layout that supports lineage. For example: gs://<project>-ml-artifacts/pipelines/<pipeline-name>/<run-id>/. Separate buckets by sensitivity or lifecycle (e.g., -ml-data-raw, -ml-data-curated, -ml-artifacts). This helps with IAM scoping and retention policies.
Use BigQuery for curated, queryable feature tables and for validation checks that are easiest in SQL. BigQuery also shines for dataset snapshots (partitioned tables, time-travel where applicable) and for auditing what data was used when. A practical pattern is: land raw data in GCS, load/transform into BigQuery curated tables, then export training views back to GCS only if your training framework requires file-based input.
Finally, understand how this ties to Vertex AI datasets and lineage. Even if you do not use the managed Dataset resource for every project, you should treat “dataset registration” (documenting source URIs, schemas, and versions) as an operational requirement. It makes pipelines debuggable and makes audits possible.
Networking is where security and cost collide. Vertex AI jobs pull data, push artifacts, and sometimes call external services. If you do nothing, many workloads will use public endpoints by default, which can be acceptable for non-sensitive bootcamp data—but the professional habit is to know your data paths and control them.
Start by keeping resources co-located: Vertex AI region, GCS bucket location, and BigQuery dataset location should align. Cross-region reads can incur egress and slow pipelines. For team environments, decide whether you require private connectivity. Private Google Access (or Private Service Connect, depending on architecture) allows resources in a VPC without external IPs to reach Google APIs privately. This reduces exposure and can simplify compliance narratives.
For training jobs that need to access resources in your VPC (databases, internal APIs), you may configure VPC network attachment for Vertex AI. The engineering judgment is to keep the default path simple until you have a requirement: VPC attachment increases configuration surface area (routes, firewall rules, NAT) and can create hidden costs if misconfigured.
In practical terms for this bootcamp, ensure your environment can reach GCS and Vertex AI endpoints reliably, and document whether you are using public endpoints or private access. That single decision affects IAM (which identities can call what), cost (egress), and reproducibility (network failures mid-run).
Cost control is not “finance paperwork”; it is an engineering feature. Vertex AI training and endpoints can scale quickly, and pipeline retries can multiply spend. You need guardrails that fail safely.
Set a budget for the project with alerts at multiple thresholds (for example, 50%, 80%, 100%). Alerts should notify the people who can act—typically the engineering team and the course learner. Pair budgets with labels. Labels make costs explorable: tag resources and jobs with env=dev, team=ml, pipeline=<name>, component=training. When a bill spikes, labels turn a mystery into a query.
Use quotas to prevent runaway usage. Quotas exist for CPUs/GPUs, API requests, and sometimes service-specific limits. In a learning environment, lowering quotas is a legitimate safety strategy: you can prevent accidental multi-GPU training. For endpoints, control min/max replica counts and choose machine types intentionally. Autoscaling is powerful, but a misconfigured max can turn a traffic test into an expensive incident.
A practical habit: every time you create a new pipeline or endpoint, ask “What is the maximum it can spend in a day?” If you cannot answer, add a quota, lower a max replica count, or add a budget alert until you can.
Pipelines become unmaintainable when configuration is scattered across notebooks, hardcoded in components, or stored as plaintext in repositories. The goal is: separate code from configuration, and protect secrets with appropriate tooling.
Use Secret Manager for sensitive values (API keys, database passwords) and grant access only to the service accounts that need them. Avoid embedding secrets in pipeline parameters, environment variables committed to code, or Dockerfiles. If a component needs a secret, fetch it at runtime using the workload identity and least-privileged IAM access to a specific secret version.
For non-secret configuration (project IDs, bucket names, dataset versions, regions), use consistent parameterization. Pipeline parameters should capture “what changes between runs” (e.g., dataset version, training steps). Environment variables or config files can capture “what changes between environments” (dev vs prod). The engineering judgment is to keep the parameter surface small: too many knobs makes runs hard to reproduce; too few makes reuse impossible.
pip install of floating versions at runtime.Finally, validate access from your local or dev environment before you rely on automation. Confirm gcloud auth is using the intended identity, verify you can read/write to the correct GCS prefixes, and run a minimal Vertex AI operation. A clean, repeatable local setup reduces the temptation to “just use my personal owner access,” which is the fastest path to fragile, non-auditable ML systems.
1. What is the main operational risk this chapter aims to prevent before building any Vertex AI Pipeline components?
2. Why does the chapter emphasize using least-privilege IAM roles with purposeful service accounts for ML workloads?
3. Which setup choice best aligns with the chapter’s guidance on artifact and dataset management?
4. How do networking and egress considerations relate to the chapter’s goals for secure, cost-aware ML?
5. What is the practical outcome of setting budgets, labels, quotas, and validating local/dev access as described in the chapter?
Reliable ML systems are built on predictable data. In the AICE Associate exam and in real Vertex AI pipelines, “data preparation” is not a one-off notebook task—it is a repeatable engineering workflow that converts raw inputs into well-defined, validated, versioned datasets and training-ready features. This chapter turns that workflow into concrete patterns you can implement in Vertex AI Pipelines: ingest raw data, define a canonical schema, enforce quality gates, create train/validation/test splits with documented assumptions, materialize features so training and inference match, and register datasets for repeatability.
Vertex AI Pipelines encourages you to treat data steps like code: each step has explicit inputs/outputs, runs in an isolated environment, and produces artifacts you can audit. When you align your pipeline’s data artifacts with Cloud Storage and BigQuery sources, and track versions and lineage, you reduce “works on my machine” failures and avoid silent performance regressions. The practical outcome is a pipeline you can re-run months later and obtain the same dataset snapshot, the same splits, and the same feature definitions—exactly what certification scenarios and production teams expect.
Throughout this chapter, keep one guiding rule in mind: if you cannot explain where a row came from, why it is in the training set (not test), and how each feature was computed at prediction time, you are not done with data preparation.
Practice note for Ingest raw data and define a canonical schema: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build data validation and quality gates: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create training/validation/test splits and document assumptions: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Materialize features/inputs for training and inference parity: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Register and version datasets for repeatable pipelines: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Ingest raw data and define a canonical schema: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Build data validation and quality gates: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Create training/validation/test splits and document assumptions: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Materialize features/inputs for training and inference parity: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Vertex AI pipelines commonly ingest data from two primary systems: Cloud Storage (GCS) for files and BigQuery for analytical tables. Pick the source based on how the data is produced and governed. GCS is ideal for event dumps, exports, images, and semi-structured logs (CSV/JSON/Parquet). BigQuery is ideal when the data already lives in curated tables with SQL-based transformations, access controls, and partitioning.
A practical ingestion pattern is to declare a “raw zone” and a “curated zone.” Raw data lands unchanged (e.g., gs://<bucket>/raw/<source>/dt=YYYY-MM-DD/). Curated data is the canonical representation you will train on (e.g., gs://<bucket>/curated/<dataset_name>/version=... or a BigQuery table with a version column). In pipelines, your first component should read raw data and write a deterministic curated artifact, so downstream steps never depend on ad-hoc file layouts.
Common mistakes include training from “latest” tables without snapshotting, mixing multiple file encodings in the same directory, and letting schema drift silently. A good engineering judgement is to favor fewer, well-defined handoff points: raw → curated dataset snapshot → splits → features. Each handoff point becomes an artifact you can store, validate, and version.
Before you validate or split data, you must define a canonical schema. This is more than column names and types; it includes meaning, allowed ranges, and how the label is computed. In exam terms, this is where you “define the label and features” and ensure the pipeline won’t accidentally train on information from the future.
Start by documenting a schema contract. For tabular ML, that contract typically includes: primary entity key (e.g., customer_id), event time (e.g., event_timestamp), label column (e.g., churned_within_30d), feature columns, and join keys if you enrich from other tables. Put the contract under version control (YAML/JSON in your repo) so pipeline code and validation logic reference the same source of truth.
Label definition is where leakage often sneaks in. A label should be derived strictly from information available after the prediction point, but not from features that would not exist at inference time. For example, if you predict churn “within 30 days of date D,” your features must use data available up to date D, and the label must be computed using outcomes in the window (D, D+30]. A subtle leakage pattern is including features like “number of support tickets in the next 7 days” because it is easy to compute in hindsight.
A practical outcome is a schema that supports repeatable splits and parity: if your schema encodes entity and time keys, you can build consistent training/validation/test splits (for example, time-based splits) and explain them to auditors or reviewers. Common mistakes include ambiguous labels, using post-outcome fields as features, and leaving null-handling to the model code instead of specifying defaults and constraints in the schema contract.
Data validation is not a dashboard; it is a gate that can stop a pipeline run. In Vertex AI Pipelines, validation should be a dedicated component that reads the curated dataset and emits a pass/fail decision plus a report artifact. The idea is simple: if the data violates your expectations, you fail fast before spending money on training and before registering bad models.
Implement checks in layers. First, schema checks: required columns exist, types are correct (or coercible), and categorical domains are within expected sets. Second, row-level constraints: non-null label rate, numeric ranges (e.g., age between 0 and 120), and uniqueness where needed (e.g., one row per entity per as-of date). Third, distribution drift checks: compare key feature distributions to a baseline (previous approved dataset version) to detect pipeline breakages like unit changes or missing joins.
Automated gates should produce machine-readable output (e.g., JSON) and a human-readable report (HTML or text) stored in GCS. Your pipeline can then branch: if validation fails, stop the run and notify; if it passes, proceed to splitting and feature materialization. Common mistakes include only logging warnings (pipelines keep going), validating after splitting (so issues are harder to debug), and using checks that are too strict to operate (causing constant failures) or too loose (missing real regressions). Engineer your thresholds to reflect business reality and progressively tighten them as data stabilizes.
Repeatable pipelines require that “the dataset” is not a moving target. Versioning means you can answer: which exact rows trained model X, which code produced them, and what upstream sources were used. In Vertex AI contexts, this is tied to both storage conventions (GCS paths, BigQuery snapshots) and metadata (Vertex ML Metadata, Experiments, and dataset resources).
A robust practice is to produce immutable dataset snapshots. For GCS, write curated outputs to a versioned directory such as gs://bucket/curated/churn/v=2026-03-26T120000Z/ and never overwrite it. For BigQuery, use time travel, table snapshots, or write to a new table name with a version suffix. Alongside the data, write a MANIFEST.json containing: source URIs, query hashes, row counts, schema hash, and the git commit of the pipeline code. This manifest becomes your lineage anchor.
Registering datasets in Vertex AI can complement storage-level versioning by giving you a discoverable resource tied to your project and IAM policies. The key judgement: don’t confuse “registered” with “immutable.” You still need snapshotting and manifests. Common mistakes include reusing a single GCS path for multiple runs, relying on “latest” views, and losing the SQL that produced the export. Auditability is earned through explicit artifacts, not tribal knowledge.
Feature engineering is where many pipelines become inconsistent: training uses one set of transformations, while batch/online prediction uses another. The cure is to treat features as a product of the pipeline, not an implicit behavior of a notebook. Your goal is training/inference parity: the same input columns, same encoding logic, and the same handling of missing values and outliers.
Start by deciding where features will be computed. For tabular workloads, many teams compute “base features” in BigQuery (using SQL, scheduled or pipeline-driven) and then perform lightweight transformations (normalization, encoding) in Python during training. This can work, but only if the same transformations are available at inference time. If you plan online prediction, consider how the serving system will compute features. If your model expects one-hot encoded categories, you must ship the category mapping. If your model expects normalized numeric inputs, you must ship the mean/std used for scaling.
Common mistakes include computing normalization using all data (leakage), letting pandas infer dtypes differently run-to-run, and using different missing-value defaults in training vs serving. Practical outcomes to aim for: a feature spec file (names, types, default behavior), a stored preprocessing artifact (e.g., a pickled encoder or TF Transform graph), and identical feature ordering for every consumer. This is also where you prepare clean train/validation/test splits and record the rationale, because model evaluation is only meaningful when the split methodology matches the deployment scenario.
To make data preparation repeatable, package preprocessing into a first-class pipeline component with a pinned runtime environment. In Vertex AI Pipelines (Kubeflow v2), this typically means a component that: reads raw/curated inputs, applies schema coercions and feature transformations, runs validation gates (or calls a separate validation component), creates splits, and writes versioned outputs plus metadata artifacts.
Design the component interface like an API. Inputs might include: source_uri (GCS prefix or BigQuery table), schema_uri (the contract file), as_of_date, split_strategy (random, stratified, time-based), and baseline_dataset_manifest for drift comparisons. Outputs should be explicit: train_data, val_data, test_data, preprocessing_artifact (encoders/scalers), validation_report, and dataset_manifest.
A strong operational habit is to make this component the only path to “official” training data. If someone wants to experiment, they can fork the component parameters, but they still produce versioned artifacts and manifests. Common mistakes include embedding preprocessing inside the training component (making it hard to reuse and validate), writing outputs to non-versioned locations, and not exporting preprocessing parameters needed for serving. When done correctly, downstream training and deployment steps can trust the inputs, and your pipeline becomes a repeatable machine for producing audited datasets and features.
1. In this chapter, what is the best description of “data preparation” for Vertex AI Pipelines?
2. Why does the chapter emphasize defining a canonical schema when ingesting raw data?
3. What is the primary purpose of data validation and quality gates in the pipeline workflow described?
4. According to the chapter’s guiding rule, what must you be able to explain to be “done” with data preparation?
5. How do registering and versioning datasets support repeatable pipelines in the chapter’s workflow?
This chapter turns your earlier groundwork (project/IAM, storage choices, and dataset versioning) into an executable Vertex AI Pipeline. The AICE Associate exam expects you to connect concepts—artifacts vs parameters, reproducible environments, pipeline caching, and operational guardrails—to day-to-day engineering decisions. The goal is not only to “make it run,” but to make it repeatable, inspectable, and safe to operate.
You will build a pipeline as a directed acyclic graph (DAG) of components: ingest/validate data, train, evaluate, and register outputs that downstream steps can consume. Each step should declare explicit inputs and outputs, emit metadata, and run in a controlled container environment. Once composed, you will execute runs, debug failures via logs and artifacts, and harden the workflow with retries, timeouts, and idempotent design so reruns do not corrupt state or create inconsistent artifacts.
Keep an exam-focused lens: Vertex AI Pipelines is Kubeflow Pipelines under the hood, so core mechanics (DAG scheduling, artifact passing, caching, and metadata tracking) matter. But in practice, your biggest wins come from disciplined component boundaries, strict typing, and treating every run as an auditable event with traceable inputs and outputs.
Practice note for Author pipeline components with inputs/outputs and metadata: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Containerize and manage dependencies for reproducible runs: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Compose the end-to-end pipeline with parameters and caching: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Run and debug pipeline executions; inspect artifacts: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Harden the pipeline with retries, timeouts, and guardrails: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Author pipeline components with inputs/outputs and metadata: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Containerize and manage dependencies for reproducible runs: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Compose the end-to-end pipeline with parameters and caching: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Run and debug pipeline executions; inspect artifacts: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Harden the pipeline with retries, timeouts, and guardrails: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Vertex AI Pipelines executes a workflow defined as a DAG: nodes are component tasks, edges represent data dependencies. “Acyclic” means you can’t have loops; iteration is modeled with constructs like parallelism and conditional branches, but the graph always has a topological order. This matters operationally: tasks can run in parallel when they don’t depend on each other, reducing overall wall-clock time and cost.
Within the DAG, two data types flow: parameters (small JSON-serializable values such as strings, numbers, booleans) and artifacts (files, directories, models, datasets—anything stored externally). Artifacts are first-class citizens in Vertex AI: the pipeline runtime records where they live (often GCS paths), their schema/type (e.g., Dataset, Model, Metrics), and lineage (what produced what). This lineage is what later enables you to answer, “Which training data and code version produced this model in the registry?”
Metrics are a specialized form of metadata. A common pattern is to output a Metrics artifact from evaluation so that downstream steps can make decisions (e.g., deploy only if AUC > 0.90). Even if you don’t implement conditional deployment yet, emitting metrics early is a practical investment: it makes runs comparable in the UI, enables baselining, and reduces guesswork during incident response.
Practically, your end-to-end pipeline will use parameters for run configuration (project ID, region, dataset version, training hyperparameters) and artifacts for durable outputs (prepared data, model, metrics). This separation is foundational for orchestration, caching, and traceability.
A pipeline component is a reproducible unit of work with an explicit interface. In Vertex AI Pipelines (KFP v2 style), you typically author components in Python with decorators, specifying typed inputs and outputs. The discipline here is exam-relevant and production-critical: correct typing drives how the system materializes data, stores artifacts, and renders metadata in the console.
Start with a small set of component patterns you can reuse:
Typing guidance: use parameters for values you would comfortably put in a build manifest (e.g., learning_rate: float, dataset_uri: str). Use artifacts for anything that is a file tree, a model, or a structured report. When outputting artifacts, write to the path provided by the runtime; do not invent your own output directories. This is a frequent source of “it ran but nothing appeared” confusion.
Also make your components emit helpful metadata. For example, after splitting data, write a small JSON manifest (counts, label distribution, feature list) into the output artifact directory. Downstream steps can read it, and humans can debug without re-running.
Practical outcome: by the end of component authoring, each step has a clear contract, can be tested locally (to the extent possible), and can be reused across pipelines (training-only, batch scoring, retraining). This modularity is the difference between a demo and an operable ML system.
Vertex AI Pipelines components run in containers. Reproducibility depends less on “pinning a requirements.txt” and more on treating the container image as part of your artifact lineage. In other words: the same inputs should produce the same outputs because the runtime environment is stable.
Choose a base image strategy that matches your team’s maturity:
Dependency management rules of thumb: pin major libraries (pandas, scikit-learn, tensorflow/torch) and any transitive dependencies known to break (protobuf is a common offender). Avoid “latest” everywhere. For GPU training, align CUDA/cuDNN versions with your framework, and validate that the Vertex AI training environment supports your chosen base.
Common mistakes include mixing incompatible package versions across components (trainer uses one version of scikit-learn, evaluator uses another), or letting pip resolve differently between runs. Another frequent problem is forgetting to include OS packages needed for reading certain file formats or connecting to databases. If a component depends on libgomp, gcc, or pyarrow system libs, bake them into the image.
Practical outcome: you can rerun a pipeline weeks later and trust that a performance regression is due to data/model changes—not an accidental dependency upgrade. This directly supports artifact tracking and reliable debugging.
Once components are solid, orchestration is about composing them into a coherent pipeline function: define the DAG, wire inputs/outputs, and expose parameters that matter. Parameterization is the lever that turns a one-off run into a reusable workflow. Typical pipeline parameters include project_id, region, dataset_version, train_steps, model_display_name, and thresholds for evaluation gates.
Design parameters with intent: expose what changes frequently (data version, hyperparameters) and keep internal wiring fixed (artifact paths, intermediate formats). If everything is a parameter, the pipeline becomes hard to reason about and easier to misuse. A good practice is to treat the pipeline as an API: stable signature, backward-compatible changes, and defaults that are safe.
Caching is the second key orchestration decision. Vertex AI Pipelines can reuse outputs when a task’s inputs (including parameters and upstream artifact lineage) match a previous execution. This is powerful for cost control: if data validation hasn’t changed, you shouldn’t pay to rerun it. But caching must be used carefully:
Common mistake: using “current date” inside a component while caching is enabled, leading to confusing results where the step appears to run but returns old outputs. The fix is either to pass the date as an explicit parameter (so cache keys change) or disable caching for that task.
Practical outcome: a composed, parameterized pipeline that can be triggered for new dataset versions, supports repeatable comparisons across runs, and avoids unnecessary compute through a deliberate caching strategy.
Running the pipeline is where engineering discipline becomes visible. You compile the pipeline definition and submit it to Vertex AI Pipelines with a chosen service account, region, and pipeline root (typically a GCS path). Ensure the service account has least-privilege access to required resources: read/write to the pipeline root bucket, read from source data locations, and permissions for training jobs and model registry as needed.
When something fails, debug systematically:
Artifact inspection is not only for failures. Use it to validate correctness: confirm row counts after filtering, verify label distribution, ensure evaluation metrics match expectations. This also ties into Vertex AI Experiments and Model Registry: when the trainer produces a model, store relevant metadata (hyperparameters, dataset version, evaluation metrics) so you can compare runs and decide what to register or promote.
Common mistake: treating logs as the only source of truth. Logs are transient signals; artifacts are durable evidence. Make critical debugging data an artifact (JSON report, metrics file) so it remains attached to the run.
Practical outcome: you can explain any run—what it used, what it produced, and why it failed or succeeded—using the console’s run details, linked artifacts, and recorded metadata.
Reliability is what turns pipelines into dependable systems. In real environments, tasks fail for reasons unrelated to your code: transient network issues, temporary quota constraints, or upstream service hiccups. Your pipeline should recover gracefully without creating inconsistent state or duplicating work.
Use three core patterns:
gs://bucket/latest/.Guardrails are the practical layer on top. Validate inputs early (fail fast if a BigQuery table is missing, if the dataset version is not found, or if schema drift exceeds a threshold). Emit explicit error messages and structured reports so operators know what to fix. If you later add conditional logic (e.g., only register/deploy when metrics meet a threshold), ensure the evaluation component produces metrics in a consistent format and that thresholds are parameters, not hardcoded constants.
Common mistakes include retrying a component that appends to a fixed table (creating duplicates) or letting a component silently succeed with empty data. The fix is to enforce invariants: minimum row counts, required columns, and explicit version identifiers passed through the pipeline.
Practical outcome: pipeline executions that are resilient to transient failures, safe to rerun, and bounded in cost—matching both exam expectations and real operational needs.
1. When designing a Vertex AI Pipeline component for this chapter’s goals, which practice best supports repeatable and inspectable runs?
2. In the end-to-end pipeline DAG (ingest/validate → train → evaluate → register), what is the main benefit of registering step outputs as artifacts that downstream steps consume?
3. How does containerizing components and managing dependencies align with the chapter’s focus on operational reliability?
4. What is the best way to approach debugging a failed pipeline execution according to the chapter?
5. You want reruns to be safe and not corrupt state or create inconsistent artifacts. Which hardening approach best matches the chapter?
This chapter turns your pipeline from “it trains” into “it can be promoted safely.” In the AICE Associate context, that means you can launch training jobs in Vertex AI, capture metrics consistently, evaluate against clear thresholds, compare runs, and register a winning model with complete metadata and lineage so it’s ready for review and deployment. The exam expects you to understand the purpose of each managed service feature (training jobs, experiments, model registry) and how they fit into an end-to-end pipeline that supports governance and repeatability.
The key engineering shift is to treat training as a production workload: every run must be attributable to a dataset version, code version, container image, hyperparameters, and environment configuration. If you cannot answer “what changed?” between two runs, you cannot confidently promote a model. Vertex AI gives you building blocks (Custom Training, AutoML, Experiments, Model Registry) but it is your pipeline design—metrics, acceptance criteria, and artifact discipline—that makes promotion trustworthy.
We will walk through a practical workflow: select a training option, standardize metric logging, produce an evaluation report, gate promotion with acceptance criteria, compare runs via Experiments, register the model with governance metadata, and package explainability/documentation artifacts. In the final section, we tie it together into a dev → stage → prod promotion workflow that can be automated in Vertex AI Pipelines.
Common failure modes you’ll learn to avoid include: training locally then uploading a “mystery model,” logging only aggregate accuracy without slices, comparing runs by memory instead of recorded metadata, and registering models without dataset lineage. Fixing those problems early saves days of confusion later—especially when endpoints, autoscaling, or batch prediction start depending on a specific model version.
Practice note for Launch training jobs and capture metrics consistently: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Implement evaluation and thresholds for automated promotion: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Track experiments and compare runs for model selection: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Register the model with proper metadata and lineage: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Prepare explainability and documentation artifacts for review: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Launch training jobs and capture metrics consistently: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Implement evaluation and thresholds for automated promotion: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Vertex AI gives you multiple training paths, and choosing correctly is part of good engineering judgment. The two you’ll use most in pipelines are Custom Training and AutoML. In both cases, the pipeline should treat training as a job that consumes a dataset artifact and produces a model artifact plus metrics.
Custom Training is the default choice when you need control: custom feature engineering, bespoke architectures, custom loss functions, distributed training strategies, or precise dependency management. You package your training code into a container (or use a prebuilt container) and submit a CustomJob. This is the path to use when you need deterministic behavior and want to pin versions of Python packages, CUDA libraries, and your own code. It also aligns well with reproducible environments in CI/CD.
AutoML is ideal when you want fast baseline performance, lower maintenance, and built-in best practices. AutoML tabular, image, text, and video training can produce strong models without you managing architecture details. Use AutoML when the objective is rapid iteration, when the dataset fits supported schemas, and when your team prefers managed optimization over custom modeling. A practical pattern is: start with AutoML to establish a baseline and acceptance metrics, then move to Custom Training if you need more control or a custom feature pipeline.
Regardless of option, standardize how you launch training jobs and capture metrics consistently. For Custom Training, emit metrics via structured logging or Vertex AI’s metrics reporting so downstream evaluation components can rely on a stable schema (for example: accuracy, AUC, F1, log loss, latency estimates). For AutoML, extract the relevant metrics from the training job output and normalize them into the same evaluation artifact format used elsewhere in your pipeline.
A common mistake is mixing training styles without normalizing outputs: one pipeline path writes metrics to Cloud Logging, another writes JSON to Cloud Storage, and evaluation code breaks. Decide early on a single contract: “training outputs model URI + metrics JSON + optional plots,” and enforce it for both Custom and AutoML paths.
Training metrics are not enough; promotion requires evaluation that produces a clear, reviewable decision. In production pipelines, evaluation is a first-class component that reads a model artifact and a held-out evaluation dataset, then writes an evaluation report artifact plus a pass/fail signal.
Start by defining which metrics matter and how they’re computed. For classification, you might log AUC, precision/recall at a fixed threshold, and calibration error. For regression, RMSE/MAE and error percentiles. For ranking, NDCG or MAP. Your pipeline should compute metrics the same way every time (same preprocessing, same label mapping, same sampling rules). Otherwise, two runs are not comparable even if the numbers look similar.
Next, formalize acceptance criteria—the thresholds that enable automated promotion. Examples include: AUC ≥ 0.92, fairness gap ≤ 0.05 across critical slices, and no more than 2% degradation versus the current “champion” model. Implement these criteria in code and output a boolean (or a small JSON object) that downstream pipeline steps can use in conditional execution.
Evaluation reports should be both machine-readable and human-reviewable. A practical pattern is to write: (1) a JSON metrics file for automation, (2) a small HTML or Markdown summary for reviewers, and (3) optional plots (ROC, PR curves, residuals) as artifacts stored in Cloud Storage. This supports your lesson objective: implement evaluation and thresholds for automated promotion while still providing artifacts for governance review.
Common mistakes include evaluating on the training set (inflated metrics), changing the evaluation dataset without versioning, or using “accuracy” alone for imbalanced data. In an exam and real work, you should demonstrate that you know how to pick metrics aligned to business risk and how to encode the acceptance criteria as a deterministic pipeline gate.
When multiple training runs exist—and they always will—you need a systematic way to track what happened. Vertex AI Experiments provides a structured place to log parameters, metrics, and artifacts per run so you can compare runs and justify model selection.
Design your pipeline so that each training execution creates (or attaches to) an Experiment and writes an Experiment Run that includes: dataset identifiers (BigQuery table version, Vertex AI Dataset ID, or GCS manifest URI), feature transformation version, container image digest, hyperparameters, and resulting metrics. Avoid vague names like “run-1”; instead encode meaning: “xgb_v3_featset7_seed42” or use labels for key facets (model_family=xgb, featureset=7, seed=42).
For comparison, focus on decision metrics and operational metrics. Decision metrics are the ones you gate promotion on (AUC, RMSE, fairness measures). Operational metrics include training time, resource usage class (CPU/GPU), and model size—important for endpoint latency and cost later. When you can compare these across runs, you can choose a model that meets quality thresholds without blowing your serving budget.
This is where the lesson track experiments and compare runs for model selection becomes practical: you’re not selecting the “best” model by memory or by a spreadsheet; you’re selecting it by recorded evidence tied to an immutable artifact trail. In pipelines, you can even implement a “best-run selector” component that queries Experiment runs and chooses the highest metric among those that pass constraints, then forwards that model for registration.
A common mistake is logging metrics in an ad hoc way (custom text logs) that cannot be aggregated or compared. Use consistent metric keys and units, and ensure your pipeline writes them in the same place every run. Consistency is what turns Experiments into a decision tool rather than a passive log.
Once you have a candidate that meets acceptance criteria, you need to register it correctly so it can be promoted and deployed with confidence. Vertex AI Model Registry is where you store the model as a managed resource, with versioning, metadata, and lineage links to the training process.
Think of the Registry as the “source of truth” for deployable models. In a pipeline, registration should include: model artifact URI, serving container specification (or framework), prediction schema if applicable, labels, and a description that ties back to the Experiment run. The goal is that an operator can answer: “Which data and code produced this model, and why was it chosen?”
Use versions to represent improvements within the same logical model (for example, “fraud-detector” version 1, 2, 3). Use aliases (or a consistent labeling scheme) to represent lifecycle status such as “candidate,” “staging,” and “prod,” or “champion” and “challenger.” This supports controlled promotion without losing history: you can promote by moving an alias, not by overwriting artifacts.
This section satisfies the lesson register the model with proper metadata and lineage. In practice, you should enforce a minimum metadata contract in code: if required labels or lineage fields are missing, fail the pipeline step rather than registering an incomplete model. That prevents “registry pollution,” where dozens of models exist but none are safely deployable.
Common mistakes include registering a model without pinning the serving container version, forgetting to store the preprocessing logic version, or failing to record which evaluation dataset was used. Those gaps become outages later when batch prediction or online serving uses a model with mismatched preprocessing.
Promotion only makes sense if you can reproduce and explain results. Reproducibility in ML is not “run it again and hope for the same number”; it is disciplined control over randomness, environments, and artifacts. In Vertex AI pipelines, reproducibility is largely a design choice: you decide what to pin and what to allow to float.
Start with random seeds. Set seeds in every library you use (Python random, NumPy, TensorFlow/PyTorch, and any algorithm-specific seeds). Record the seed as a parameter in the pipeline and log it to Experiments. This lets you distinguish “better model” from “lucky run.” For some GPU workloads, full determinism may reduce performance; the practical approach is to aim for bounded variance and document where nondeterminism remains.
Next, enforce artifact pinning. Pin your training container by image digest (not a floating tag like :latest). Pin Python dependencies via lock files. Pin data via immutable references: a BigQuery snapshot table, a GCS object generation, or a versioned Vertex AI Dataset export. Store preprocessing code (for example, a feature transformation module) in the same repository revision as training, and log the commit SHA.
Reproducibility also includes consistent metric computation. If evaluation depends on a preprocessing step, that step must be identical across runs, otherwise your acceptance criteria are meaningless. This is why artifact discipline matters: the evaluation component should consume the same transformation artifacts as training (or apply the same transformation container) to avoid training/eval skew.
A common mistake is assuming that setting a seed alone solves reproducibility. If your container tag changes, your BLAS library changes, or your dataset query returns different rows, you will not reproduce results. Treat reproducibility as a multi-layer contract: seeds + pinned environments + versioned data + logged metadata.
A promotion workflow is the bridge between “model training” and “model deployment.” A robust design separates environments—dev → stage → prod—and promotes only models that pass quality gates and governance checks. In Vertex AI Pipelines, this is typically implemented with conditional steps, approvals, and controlled alias changes in the Model Registry.
In dev, you optimize iteration speed: smaller datasets, fewer hyperparameter trials, and frequent runs. You still log metrics and artifacts consistently, but acceptance criteria can be looser (for example, “must not be obviously broken”). Dev is where you validate the pipeline mechanics: training launches correctly, metrics are captured, Experiments runs appear, and models register with the required metadata.
In stage, you run the near-production evaluation: full evaluation dataset, slice metrics, fairness checks, and stricter thresholds. Stage should also generate the artifacts needed for review: evaluation summary, model card inputs, and an explainability configuration (for example, feature attributions settings and baseline selection). This directly supports the lesson prepare explainability and documentation artifacts for review. Your pipeline should write these artifacts to a stable location and link them in the Model Registry metadata.
In prod, promotion is a controlled act. A practical pattern is: register the model version, set alias “candidate,” run stage evaluation, then move alias to “prod” only if gates pass (and optionally after manual approval). This makes rollback simple: move the alias back to the previous version. Avoid rebuilding or re-uploading models during promotion; promote the already-registered artifact to preserve lineage.
Common mistakes include promoting directly from dev to prod, using ad hoc naming instead of aliases, and skipping documentation artifacts until after deployment. The practical outcome of a good design is that deployment (online endpoints or batch prediction) becomes a separate, safer step: you deploy a known registry version with known metrics, not an untracked file sitting in Cloud Storage.
1. What is the key engineering shift Chapter 5 emphasizes for making model promotion trustworthy?
2. Which pipeline outcome best supports automated promotion in a dev → stage → prod workflow?
3. If you cannot answer “what changed?” between two training runs, what does the chapter imply about promoting the model?
4. How do Vertex AI Experiments fit into the workflow described in Chapter 5?
5. Which set of actions best matches the chapter’s guidance for registering a model ready for review and deployment?
This chapter turns your working Vertex AI Pipeline into a system you can safely operate in production-like conditions—the exact mindset the AICE Associate exam expects. Training a model is only one milestone; the job is finished when you can deploy it, serve predictions reliably, monitor behavior changes, and promote new versions through controlled automation.
In practice, deployment and operations are where teams lose time and incur risk: a rushed endpoint configuration that can’t scale, batch jobs that overwrite outputs, missing logs during an incident, or “silent” data drift that gradually erodes accuracy. You will build a repeatable workflow: (1) register a model, (2) deploy it to an endpoint with autoscaling and safe rollouts, (3) run batch prediction with careful destinations and scheduling, (4) instrument observability and define operational health targets, (5) enable model monitoring for drift/skew/alerts, and (6) implement CI/CD with gated promotion.
Throughout, apply engineering judgment: prefer explicit versioning over “latest,” treat serving configuration as code, separate dev/stage/prod environments, and design for reversibility (roll back fast). These habits align directly with exam scenarios that ask what you should do next when latency spikes, prediction distributions shift, or a pipeline change must be promoted safely.
Practice note for Deploy to online endpoints with scaling and traffic splitting: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Run batch predictions and manage outputs safely: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Add monitoring for drift, performance, and operational health: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Implement CI/CD for pipeline builds and environment promotion: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Complete an AICE-style capstone review and practice exam checklist: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Deploy to online endpoints with scaling and traffic splitting: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Run batch predictions and manage outputs safely: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Add monitoring for drift, performance, and operational health: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Implement CI/CD for pipeline builds and environment promotion: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Practice note for Complete an AICE-style capstone review and practice exam checklist: document your objective, define a measurable success check, and run a small experiment before scaling. Capture what changed, why it changed, and what you would test next. This discipline improves reliability and makes your learning transferable to future projects.
Online prediction in Vertex AI is built around an Endpoint that can host one or more deployed model versions. Treat the endpoint as the stable “URL contract” and the deployed models as the changeable implementations. This separation enables safe rollouts without forcing clients to change.
Start by choosing the right machine type (CPU vs GPU, memory size) based on model size and latency requirements. A common operational mistake is over-provisioning (wasting cost) or under-provisioning (timeouts, cold starts, and retries that amplify load). For most tabular models and lightweight TF/PyTorch models, CPU machines with adequate memory are sufficient; reserve GPUs for truly GPU-bound inference.
Configure autoscaling using min/max replica counts and utilization targets. The “min replicas” is your hedge against cold-start latency, while “max replicas” is your cost and safety ceiling. Use a minimum of 1 replica for production-critical endpoints; set max replicas based on expected peak traffic and budget. If you have predictable peaks, size max replicas to handle them without saturating CPU. If you have spiky traffic, consider higher max with stricter budgets and alerting.
Practical outcome: you can deploy a new model from Model Registry to an endpoint, ramp traffic gradually, and revert quickly if quality or latency regresses. Exam scenarios often ask what’s safest: traffic splitting plus monitoring beats replacing a single deployment in-place.
Batch prediction is the right tool when you don’t need millisecond latency and you want cost-efficient throughput on large datasets. In Vertex AI, you create a BatchPredictionJob that reads from a source (often BigQuery or Cloud Storage) and writes predictions to a destination (Cloud Storage or BigQuery). The job is immutable once started, which is good: it preserves evidence of what ran, when, and with which model version.
Output management is where teams commonly make mistakes. Never write batch outputs to a “shared” path like gs://bucket/predictions/ without a run-specific prefix; you will overwrite results and lose auditability. Prefer a pattern such as gs://bucket/predictions/model=MODEL_ID/date=YYYY-MM-DD/run=PIPELINE_JOB_ID/. If writing to BigQuery, write to a versioned table name or partition and include columns for model_id, model_version, and prediction_timestamp.
Practical outcome: you can run safe, repeatable batch scoring and integrate it into daily/weekly workflows. On the exam, expect prompts about choosing online vs batch, and about safeguarding destinations and permissions.
Observability is your ability to answer, quickly and confidently: “What is the system doing right now, and why?” For ML systems, this includes traditional service signals (latency, errors, saturation) plus ML-specific context (model version, feature schema, and prediction distributions). Vertex AI integrates with Cloud Logging and Cloud Monitoring; use them deliberately rather than relying on default logs that are hard to correlate.
Start with structured logs. At minimum, log: endpoint ID, deployed model ID, request ID/correlation ID, latency, HTTP/gRPC status, and payload sizes. Avoid logging sensitive features or full request bodies unless you have an explicit privacy and retention plan. A common mistake is adding “debug logs” during an incident and forgetting to remove them, causing costs and compliance issues.
Tracing is especially useful when online prediction is called as part of a wider workflow (API gateway → feature retrieval → prediction → business logic). Use consistent request IDs across services so you can follow a single user request end-to-end. When you see latency spikes, tracing helps distinguish “model is slow” from “upstream feature store query is slow.”
Practical outcome: you can detect and diagnose operational issues quickly, and you can justify rollout/rollback decisions with evidence. Exam items often test whether you know where to look first: logs for errors, monitoring for trends, tracing for root cause across services.
Model monitoring is observability focused on statistical behavior. Two foundational concepts are training-serving skew (serving data differs from what the model saw during training) and drift (serving data changes over time). These are not always “bugs,” but they are strong indicators that performance may degrade.
Enable monitoring by defining a baseline: the training dataset statistics or a curated reference window of production data that you trust. Then choose which features to monitor and appropriate thresholds. The engineering judgment here is to avoid monitoring everything equally. Monitor high-impact features (those with strong influence on predictions) and features prone to upstream changes (categorical IDs, source-system codes, or heavily preprocessed fields).
Common mistakes include setting thresholds too sensitive (constant noise) or too loose (no early warning), and treating drift as automatically requiring redeployment. Drift is a signal—your response might be to validate labels, run shadow evaluation, or trigger a retraining pipeline with approval gates.
Practical outcome: you can configure monitoring to detect meaningful distribution changes and respond with a controlled process rather than panic. The exam frequently frames these as “model accuracy is dropping” or “prediction distribution changed”; monitoring is your first line of evidence.
CI/CD for ML is the discipline of turning pipeline code, training code, and serving configuration into a promotable release. The goal is repeatability: the same commit should build the same container images, compile the same pipeline, and produce traceable artifacts. In Vertex AI environments, this typically means Cloud Build (or another CI runner), Artifact Registry, and environment-specific deployment steps.
Organize your delivery into stages. In CI, validate code quality and reproducibility: run unit tests for components, lint Dockerfiles, and build versioned images pushed to Artifact Registry. Compile pipelines (or run a “dry compile” step) and store pipeline specs as artifacts. In CD, deploy to dev automatically, promote to stage after integration checks, and promote to prod with an approval gate.
v1.4.0) triggers a promotion workflow.latest. Record model registry IDs and pipeline job IDs as release metadata.Common mistakes include rebuilding images during promotion (introducing accidental changes), sharing one endpoint across environments, and using broad IAM permissions for CI service accounts. Use least privilege and separate projects or at minimum separate service accounts and resources per environment.
Practical outcome: you can reliably rebuild and promote pipeline and serving changes with traceability and controls—exactly the operational maturity the AICE Associate blueprint is steering you toward.
The AICE Associate exam is scenario-heavy: it tests whether you choose the safest, most maintainable option under constraints. Use the chapter’s workflow as your mental model: register → deploy (safe rollout) → observe → monitor → automate promotion. When confronted with a prompt, first classify it: online vs batch need, operational incident vs model quality issue, or deployment process vs code issue.
Scenario drill mindset (without turning it into a quiz): if latency rises after a rollout, your first move is usually to check endpoint metrics/logs and shift traffic back, not to retrain. If prediction outputs are missing, check batch destination paths/permissions and job status before rerunning. If distributions drift but errors are normal, investigate upstream data changes and consider shadow evaluation before changing production traffic.
Final checklist for exam-ready MLOps: (1) you can deploy a model version to an endpoint with autoscaling and traffic splitting, (2) you can run batch prediction with versioned outputs and least-privilege access, (3) you can locate relevant logs/metrics and reason about incidents, (4) you can explain drift vs skew and when to retrain, (5) you can describe a CI/CD path that pins artifacts and uses approvals for promotion, and (6) you can justify each choice in terms of reliability, cost, and risk.
1. Which workflow best reflects the chapter’s recommended path for operating a Vertex AI model in production-like conditions?
2. A team worries a new model version could increase risk during rollout. What chapter-aligned deployment practice reduces risk while still enabling release?
3. Why does the chapter emphasize managing batch prediction outputs “safely”?
4. In an exam-style scenario where prediction distributions shift over time without obvious failures, what capability does the chapter recommend to detect and respond?
5. Which set of engineering habits best matches the chapter’s guidance for safe CI/CD and environment promotion?

- Learning Evolved.
- Intelligence Amplified.

